「MITの新しい機械学習の研究では、階層的な計画(HiP)のための組成的な基礎モデルを提案しています:長期的な課題の解決のために言語、ビジョン、行動を統合する」
MIT proposes a compositional foundation model for hierarchical planning (HiP) in their new machine learning research, integrating language, vision, and action for solving long-term tasks.


見知らぬ家でお茶を準備するという課題について考えてみましょう。このタスクを効率的に完了するための戦略は、抽象レベル(例えば、お茶を温めるために必要な高レベルの手順)、具体的な幾何学的レベル(例えば、彼らがどのように物理的に動き、キッチンを通り抜けるか)、および制御レベル(例えば、カップを持ち上げるために関節をどのように動かすか)を含む、複数のレベルで階層的に推論することです。茶ポットを探すための抽象的なプランは、幾何学的レベルで物理的に考えられ、彼らが行える行動に基づいて実行可能でなければなりません。そのため、各レベルでの推論が互いに整合性を持つことが重要です。本研究では、階層的な推論を用いることができる、ユニークな長期的なタスク解決用のボットの開発を調査しています。
大規模な「基礎モデル」は、数学的な推論、コンピュータビジョン、自然言語処理の問題に取り組む上でリードを取っています。「基礎モデル」を作成することは、このパラダイムの下で重要な問題であり、ユニークで長期的な意思決定問題に対応できる「基礎モデル」の作成には、多くの関心が集まっています。いくつかの以前の研究では、視覚、言語、アクションのデータをマッチさせ、長期的なタスクを処理するために単一のニューラルネットワークを訓練することが行われました。しかし、連動したビジョンと言語のロボットの例は、インターネット上で利用可能な豊富な資料に対して見つけることが難しく、編集するのにも費用がかかります。
さらに、モデルの重みがオープンソース化されていないため、GPT3.5/4やPaLMなどの高性能な言語モデルを微調整することは現在困難です。基礎モデルの主な特徴は、新しい問題を解決するために学習する必要がある場合よりも、はるかに少ないデータで解決できることです。本研究では、長期的な計画のための基礎モデルを構築するために、3つのモダリティ間でペアのデータを収集するという時間と費用のかかるプロセスに代わるスケーラブルな代替手段を模索しています。これは、新しい計画タスクの解決においても合理的に効果的であることができるでしょうか。
- UCIと浙江大学の研究者は、ドラフティングと検証のステージを使用した自己推測デコーディングによるロスレスな大規模言語モデルの高速化を紹介しました
- 「挑戦的に、マイクロソフトの研究者はGPT-4に「人工知能の火花」を見つけたと述べる」
- 「ヌガットモデルを使用した研究論文の生成AI」
Improbable AI Lab、MIT-IBM Watson AI Lab、マサチューセッツ工科大学からの研究者たちは、階層的計画のための構成的基礎モデル(HiP)を提案しています。これは、言語、ビジョン、アクションのデータに独自にトレーニングされた多くの専門モデルから構成される基礎モデルです。基礎モデルを構築するために必要なデータ量は大幅に削減されます(図1)。HiPは、抽象的な言語指示で指定された意図したタスクから、一連のサブタスク(すなわち、計画)を発見するために大規模な言語モデルを使用します。HiPは、環境に関する幾何学的および物理的情報を収集するために大規模なビデオ拡散モデルを使用して、観察のみの軌跡としてより複雑な計画を開発します。最後に、HiPは、以前にトレーニングされた大規模な逆モデルを使用して、一連の自己中心的な画像をアクションに変換します。
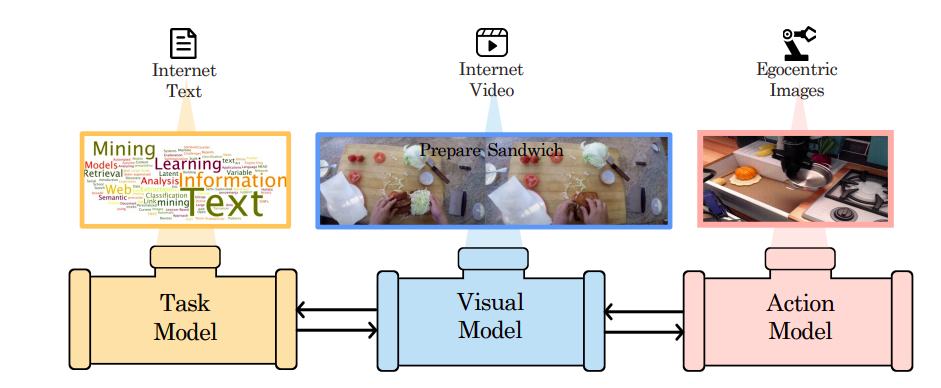
図1:階層的計画のための構成的基礎モデルが上記に示されています。HiPは、タスクモデル(LLMによって表される)を使用して抽象的な計画を作成し、ビジュアルモデル(ビデオモデルによって表される)を使用して画像の軌跡計画を作成し、自己中心的なアクションモデルを使用して画像の軌跡からアクションを推論します。
連動した意思決定データをモダリティ間で収集する必要がないため、構成的な設計選択は、さまざまなモデルが階層の異なるレベルで推論し、専門的な結論を共同で導くことを可能にします。別々にトレーニングされた3つのモデルは、相反する結果を生成する可能性があり、全体の計画プロセスで失敗する可能性があります。例えば、キャビネットでティーケトルを探すという計画のステップは、一つのモデルでは高い確率で成功する一方で、もう一つのモデルでは確率がゼロになるかもしれません。家にキャビネットがない場合などです。代わりに、すべての専門モデルにわたって尤度を最大化する戦略をサンプリングすることが重要です。
彼らは、多様なモデル間で一貫性を確保するための反復的な改良技術を提供しています。ダウンストリームモデルからのフィードバックを利用して、異なるモデル間で一貫性のある計画を開発します。言語モデルの生成プロセスの出力分布には、各段階で現在の状態を表す条件付きの尤度推定器からの中間フィードバックが組み込まれています。同様に、アクションモデルからの中間入力は、開発プロセスの各段階でのビデオの作成を向上させます。この反復的な改良プロセスにより、多くのモデル間で合意形成が促進され、目標に対応し、既存の状態とエージェントに基づいて実行可能な階層的に一貫した計画が作成されます。彼らの提案された反復的改良手法は、広範なモデルの微調整を必要とせず、トレーニングの計算効率が高くなっています。
さらに、彼らはモデルの重みを知る必要もなく、彼らの戦略は入力と出力のAPIアクセスを提供するすべてのモデルに適用できます。結論として、彼らは長期の計画を作成するために、さまざまなインターネットおよびエゴセントリックなロボティクスデータのモダリティで独立に取得された基礎モデルの組成を使用する階層的計画の基礎モデルを提供しています。3つの長期のテーブルトップ操作シナリオにおいて、彼らは有望な結果を示しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「研究者たちが、チップベースのサーミオニック冷却を量子コンピュータに応用可能にしました」
- ChatGPTはナップサック問題を解決できますか?
- このAI研究は、ITオペレーション向けの新しい大規模言語モデルであるOwlを紹介します
- 「IBMの研究者たちは、モダリティやタスクに関係なくAIシステム向けの敵対的な入力を生成することが可能な新しい敵対的攻撃フレームワークを提案しています」
- 人工知能を使用した3Dモデルのカスタマイズを革新する:MITの研究者が、機能性に影響を与えずに美的な調整を行うためのユーザーフレンドリーなインターフェースを開発しました
- 「Googleの研究者は、シーンのダイナミクスに先行する画像空間をモデリングするための新しい人工知能アプローチを発表します」
- エイントホーフェンとノースウェスタン大学の研究者が、外部のトレーニングを必要としないオンチップ学習が可能な新しいニューロモーフィックバイオセンサーを開発しました






