「マイクロソフトの研究者がSpeechXを紹介:ゼロショットのTTSと様々な音声変換タスクに対応する多目的音声生成モデル」
Microsoft researchers introduce SpeechX a multi-purpose speech generation model that supports zero-shot TTS and various voice conversion tasks.


テキスト、ビジョン、音声など、複数の機械学習アプリケーションは、生成モデルの技術において急速かつ重要な進展を遂げてきました。これらの進展により、産業や社会は大きな影響を受けています。特に、マルチモーダルな入力を持つ生成モデルは、真に革新的な発展を遂げています。ゼロショットテキストto音声(TTS)は、音声ドメインにおけるよく知られた音声生成の問題であり、音声テキスト入力を使用します。意図した話者の小さな音声クリップだけを使用して、ゼロショットTTSはその話者の声の特徴や話し方を持ったテキストソースを音声に変換することを含みます。初期のゼロショットTTSの研究では、固定次元の話者埋め込みが使用されました。この方法は話者クローニングの機能を効果的にサポートせず、TTSに限定した使用に制限がありました。
しかしながら、最近の戦略では、マスクされた音声の予測やニューラルコーデックの言語モデリングなど、より広範な概念が含まれています。これらの先端的な手法では、一次元の表現に圧縮せずにターゲットスピーカーのオーディオを使用します。その結果、これらのモデルは、優れたゼロショットTTSの性能に加えて、音声変換や音声編集などの新機能を表示しています。この増加した適応性は、音声生成モデルの可能性を大きく拡大することができます。ただし、これらの現在の生成モデルには、特に入力音声の変換を含むさまざまな音声テキストベースの音声生成タスクを処理する際に、いくつかの制限があります。
例えば、現在の音声編集アルゴリズムは、クリーンな信号のみを処理することができず、バックグラウンドノイズを維持しながら話された内容を変更することはできません。さらに、議論されたアプローチは、ノイズのある信号をクリーニングするためにクリーンな音声セグメントで囲まれる必要があるため、その実用的な適用性に重大な制限を課しています。ターゲットスピーカーの抽出は、汚れた音声を変更する文脈で特に役立つ仕事です。ターゲットスピーカーの抽出は、複数の話者を含む音声混合物から目標の話者の声を取り除くプロセスです。少しの話し声クリップを再生することで、希望の話者を指定することができます。前述のように、現在の生成音声モデルは、その潜在的な重要性にもかかわらず、この仕事を処理することができません。
- 「スタンフォード大学の研究者が自然な視覚の解読を解明し、新しいモデルが目が視覚シーンを解読する方法を明らかにする」
- アリババの研究者たちは、ChatGPTのような現代のチャットボットの指示に従う能力を活用した、オープンセットの細かいタグ付けツールであるINSTAGを提案しています
- 新しい研究によって、テキストをスムーズに音声化することができるようになりました | Google
回帰モデルは、過去の手法におけるノイズ除去やターゲットスピーカーの抽出などの信頼性のある信号回復に使用されてきました。しかし、これらの以前の手法では、発生しうるさまざまな音響的な混乱に対して異なる専門モデルが必要な場合があり、最適ではありません。特定の音声改善タスクに主に焦点を当てた小規模な研究以外にも、参照転写を使用して理解可能な音声を生成するための完全な音声テキストベースの音声改善モデルに関する研究はまだ行われていません。音声と変換能力を統合した音声テキストベースの生成音声モデルの開発は、上記の要素および他の学問分野での成功した前例に鑑みて、重要な研究の関心を持ちます。
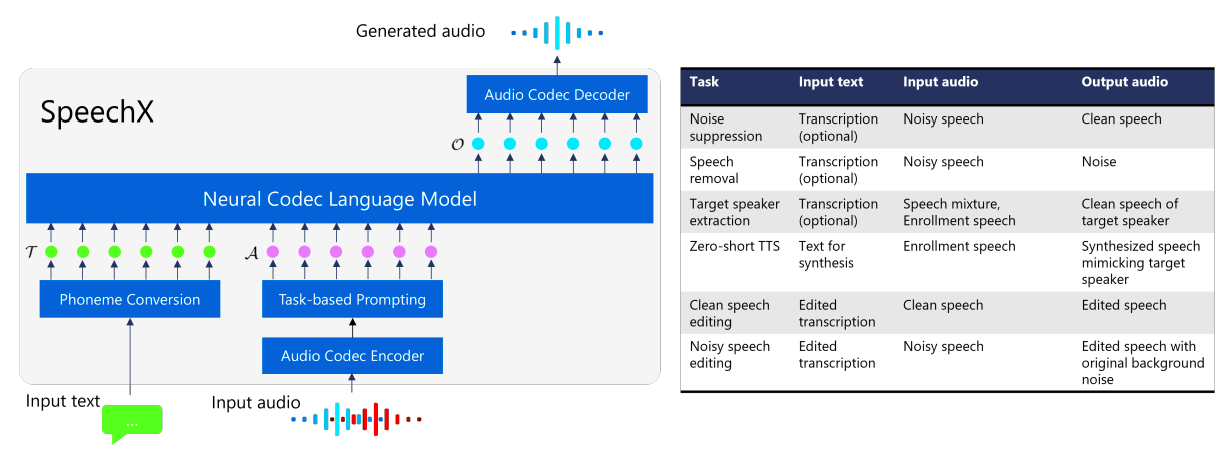
これらのモデルは、さまざまな音声生成ジョブを処理する幅広い能力を持っています。これらのモデルは、他の機械学習の領域で作成された統一または基礎となるモデルと同様に、オーディオとテキストの入力から音声を生成するさまざまなタスクを実行できる必要があります。ゼロショットTTSだけでなく、音声拡張や音声編集など、さまざまな種類の音声変更もこれらの活動に含まれるべきです。
統一モデルは音響的に困難な状況で使用される可能性があるため、さまざまな音響的な歪みに対して耐性を示さなければなりません。これらのモデルは、背景ノイズが一般的な実世界の状況で役立つことができます。
• 拡張性: 統一モデルでは、柔軟なアーキテクチャを使用して、スムーズなタスクサポートの拡張を可能にする必要があります。これを実現する方法の一つは、追加のモジュールや入力トークンなどの新しいコンポーネントのためのスペースを提供することです。この柔軟性により、モデルは新しい音声生成のタスクに効率的に適応することができます。Microsoft Corporationの研究者は、この論文でこの目標を達成するために、柔軟な音声生成モデルを紹介しています。このモデルは、ゼロショットTTS、オプションのトランスクリプト入力を使用したノイズ抑制、音声除去、オプションのトランスクリプト入力を使用したターゲットスピーカー抽出、および静かな環境と騒々しい環境の両方に対する音声編集など、複数のタスクを実行することができます(図1)。彼らはSpeechX1を推奨モデルとして指定しています。
VALL-Eと同様に、SpeechXは、テキストと音声の入力に基づいてニューラルコーデックモデルのコードまたは音響トークンを生成する言語モデリングアプローチを採用しています。さまざまなタスクの処理を可能にするために、彼らはマルチタスク学習の設定で追加のトークンを組み込んでおり、トークンは共同して実行されるタスクを指定します。トレーニングセットとしてLibriLightから60K時間の音声データを使用した実験結果は、SpeechXの効果を示しており、上記のすべてのタスクで専門モデルと比較して同等または優れた性能を発揮しています。特に、SpeechXは、音声編集中に背景音を保持する能力や、ノイズ抑制やターゲットスピーカー抽出のための参照トランスクリプトを活用するなど、新しいまたは拡張された機能を備えています。彼らが提案するSpeechXモデルの能力を示すオーディオサンプルは、https://aka.ms/speechx でご覧いただけます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- このAI研究では、詳細な全身のジオメトリと高品質のテクスチャを持つ、リアルな3Dの服を着た人物を、単一の画像から再構築するためのテクノロジー(TeCH)を提案します
- 「MITとハーバードの研究者が提案する(FAn):SOTAコンピュータビジョンとロボティクスシステムの間のギャップを埋める包括的なAIシステム- 任意のオブジェクトのセグメンテーション、検出、追跡、および追従のためのエンドツーエンドのソリューションを提供する」
- メタスの新しいテキストから画像へのモデル – CM3leon論文の説明
- 「ライス大学とIITカーンプールは、共同研究賞の受賞者を発表します」という文を日本語に翻訳すると、以下のようになります: 「ライス大学とIITカーンプールは、共同研究賞の受賞者を発表します」
- CMUの研究者たちは、視覚的な先行知識をロボティクスのタスクに転送するためのシンプルなディスタンスラーニングAIメソッドを開発しました:ベースラインに比べてポリシーラーニングを20%改善
- 「MITとハーバードの研究者は、脳内の生物学的な要素を使ってトランスフォーマーを作る方法を説明する可能性のある仮説を提出しました」
- Google DeepMindの研究者は、機能を維持しながら、トランスフォーマーベースのニューラルネットワークのサイズを段階的に増やすための6つの組み合わせ可能な変換を提案しています