マイクロソフトの研究者が「LoRAShear LLMの構造的な剪定と知識の回復に対する画期的な人工知能効率的アプローチ」を紹介
マイクロソフトの研究者が「LoRAShear LL Mの構造的な剪定と知識の回復に対する画期的な人工知能効率的アプローチ」の紹介


LLMは大量のテキストデータを処理し、関連情報を迅速に抽出することができます。これは、検索エンジン、質問応答システム、データ分析などに応用され、ユーザーが必要とする情報をより簡単に見つけるのに役立ちます。LLMは、即座に広範な情報データベースにアクセスすることにより、研究者、プロフェッショナル、様々な分野で知識を求める個人にとって価値のある情報を提供することで、人間の知識を補完することができます。
知識の復元は、LLMにおいて最も重要なタスクの1つです。LLMにおける知識の復元には、ファインチューニングという一般的な方法があります。開発者は、事前学習済みのモデルを取り、特定のデータセットでファインチューニングすることで、その知識を更新することができます。最新のイベントや特定の領域についてのモデルを知識を持たせたい場合、関連するデータでのファインチューニングが役立ちます。LLMを維持する研究者や組織は、定期的に新しい情報でモデルを更新し、より最新のデータセットや特定の知識の更新手順でモデルを再学習しています。
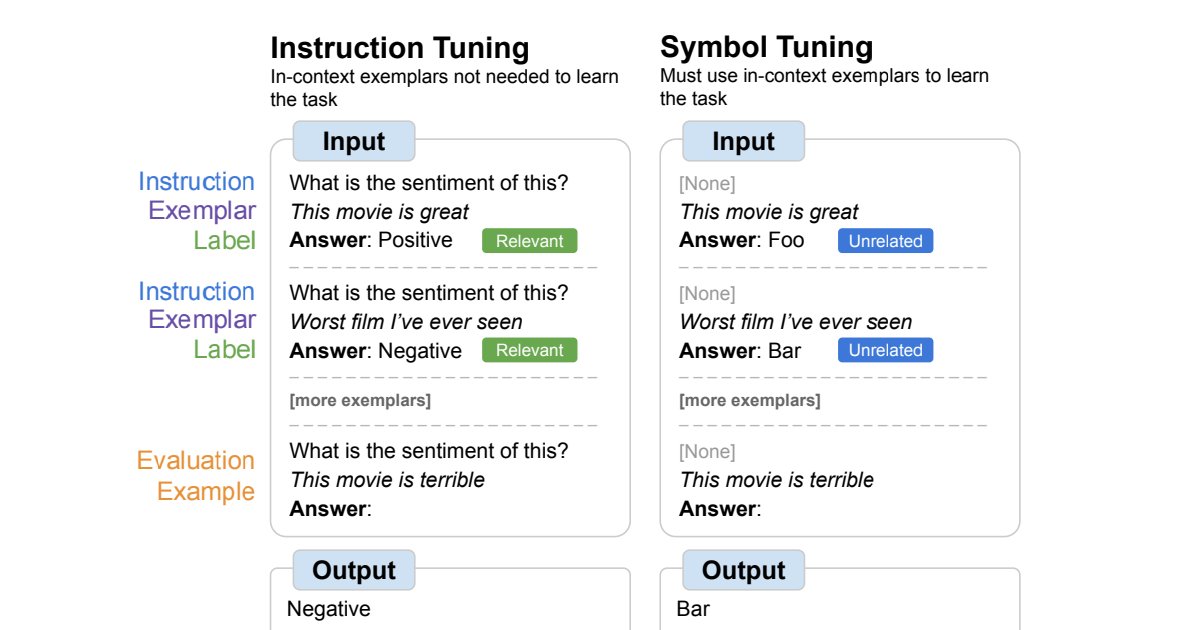
マイクロソフトの研究者は、LLMの枝刈りと知識の構造的な回復を効率的に行う革新的な手法を開発しました。これを「LoRAShear」と呼んでいます。構造的な枝刈りは、ニューラルネットワークのアーキテクチャの特定の要素を削除または減少させることで、より効率的でコンパクトで計算量の少ないものにすることを指します。彼らは、LoRAモジュールとの間で進行的な構造的な枝刈りを可能にするために、Lora Half-Space Projected Gradient(LHSPG)を提案し、さらに、事前学習と指示付きファインチューニングの両方の方法でのマルチステージのファインチューニングを行うためのダイナミックな知識回復ステージを導入しています。
- サリー大学の研究者が新しい人工知能(AI)モデルを開発しましたこのモデルは、通信ネットワークが最大76%ものネットワークを節約できる可能性があります
- COSPとUSPの内部:GoogleがLLMsの推論を進めるための新しい方法を研究する
- 「ビジョン・トランスフォーマーの内部機能」
研究者たちは、LoRAShearをLoRAモジュールを持つLLMに適用することで、一般的なLLMに適用できると述べています。彼らのアプローチは、元のLLMおよびLoRAモジュールの依存関係グラフを作成するためのアルゴリズムを固有に定義します。また、LoRAモジュールからの情報を利用して重みを更新する構造的疎密最適化アルゴリズムも導入しており、知識の保存を向上させています。
LoRAPruneは、LoRAを反復的な構造的な枝刈りと組み合わせることで、パラメータの効率的なファインチューニングと直接的なハードウェアアクセラレーションを実現しています。彼らは、これはLoRAの重みと勾配のみを用いた枝刈り基準に依存しているため、メモリの効率的なアプローチであると述べています。彼らは、LLMを与えられた場合、トレースグラフを構築し、圧縮するノードグループを確立します。学習可能な変数を最小限の削除構造に分割し、学習可能な変数グループを再構成してLLMに返します。
彼らは、これをオープンソースのLLAMAv1に実装することで、その効果を実証しています。20%削減されたLLAMAv1はパフォーマンスが1%低下し、50%削減されたモデルは評価ベンチマークで82%のパフォーマンスを保持することを発見しました。ただし、LLMへの適用は、大量の計算リソースと事前学習および指示付きファインチューニングデータセットの利用できない要件により、重要な課題に直面しています。今後の課題は、これを解決することです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「AWS 研究者がジェミニを紹介:大規模な深層学習トレーニングにおける画期的な高速障害回復」
- ミシガン大学の研究者は、AIの心理理論において新領域を開拓し、分類法と厳密な評価プロトコルを明らかにしました
- AIにおける事実性の向上 このAI研究は、より正確かつ反映性のある言語モデルを実現するためのセルフ-RAGを紹介します
- アップルの研究者が提案する「大規模な言語モデル強化学習ポリシー(LLaRP)」:体現された視覚的課題のために汎用的なポリシーとして機能するLLMをカスタマイズするためのAIアプローチ
- スタンフォードの研究者がRoboFuMeを導入:最小限の人間の入力でロボットの学習を革新する
- マイクロソフトの研究者が、言語AIを活用してオンライン検索エンジンを革命化するための「大規模検索モデル」フレームワークを紹介しました
- この中国のAI研究は、マルチモーダルな大規模言語モデル(MLLMs)の幻覚を修正するために設計された革新的な人工知能フレームワークである「ウッドペッカー」を紹介します