マイクロソフトの研究者は、テキスト重視の画像の機械読み取りのためのマルチモーダルリテラシーモデルであるKosmos-2.5を紹介しました
Microsoftの研究者は、テキスト重視の画像の機械読み取りのためのKosmos-2.5というマルチモーダルリテラシーモデルを紹介しました


近年、大規模言語モデル(LLM)が人工知能の中で注目を浴びていますが、これまで主にテキストに焦点を当て、視覚的な内容の理解に苦労してきました。多モーダル大規模言語モデル(MLLM)は、このギャップを埋めるために登場しました。MLLMは、ビジュアルとテキストの情報を単一のTransformerベースのモデルで組み合わせ、両方のモダリティからコンテンツを学習・生成することができるため、AIの能力の大幅な向上をもたらします。
KOSMOS-2.5は、統一されたフレームワーク内で2つの密接に関連する転写タスクを処理するために設計された多モーダルモデルです。最初のタスクは、空間認識を持つテキストブロックを生成し、テキストリッチな画像内のテキスト行に空間座標を割り当てることです。2番目のタスクは、さまざまなスタイルと構造を捉えたマークダウン形式の構造化されたテキスト出力を生成することに焦点を当てています。
両方のタスクは、共有のTransformerアーキテクチャ、タスク固有のプロンプト、および適応可能なテキスト表現を利用した単一のシステムで管理されています。モデルのアーキテクチャは、ViT(Vision Transformer)に基づくビジョンエンコーダと、Transformerアーキテクチャに基づく言語デコーダを組み合わせ、リサンプラモジュールを介して接続されています。
- 「大規模な言語モデルがコンパイラ最適化のメタAI研究者を驚かせる!」
- 「大規模な言語モデルは、長い形式の質問応答においてどのようにパフォーマンスを発揮するのか?Salesforceの研究者によるLLMの頑健性と能力についての詳細な解説」
- 「UCSD研究者がオープンソース化したGraphologue:GPT-4のような大規模言語モデルの応答をリアルタイムでインタラクティブな図表に変換するユニークなAI技術」
このモデルを訓練するためには、テキストが多い画像の大規模なデータセットで事前トレーニングを行います。このデータセットには、境界ボックス付きのテキスト行とプレーンなマークダウンテキストが含まれています。このデュアルタスクトレーニングのアプローチにより、KOSMOS-2.5の全体的な多モーダルリテラシー能力が向上します。
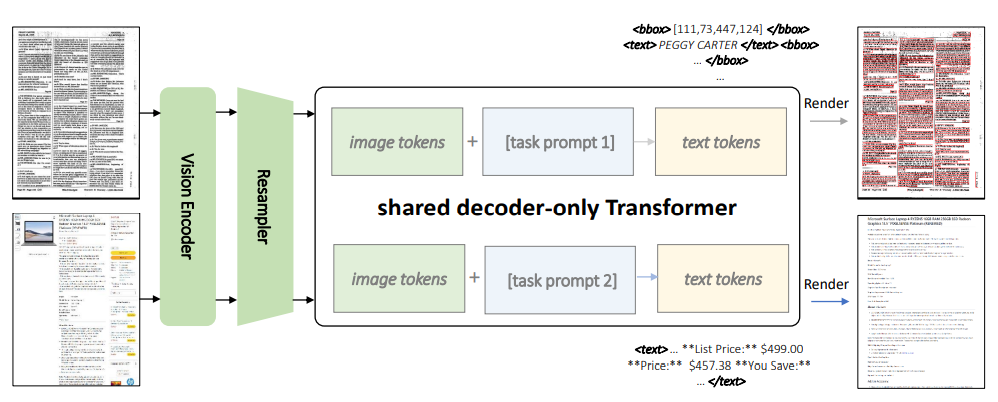
上記の画像は、KOSMOS-2.5のモデルアーキテクチャを示しています。KOSMOS-2.5の性能は、エンドツーエンドのドキュメントレベルのテキスト認識と、マークダウン形式の画像からのテキスト生成の2つの主要なタスクで評価されます。実験結果は、テキスト集中の画像タスクの理解力における強力なパフォーマンスを示しています。さらに、KOSMOS-2.5は、フューショットおよびゼロショット学習を含むシナリオで有望な能力を発揮し、テキストリッチな画像を扱う実世界のアプリケーションにおいて、多目的なツールとなります。
これらの有望な結果にもかかわらず、現在のモデルにはいくつかの制限があり、貴重な将来の研究方向を提供しています。たとえば、KOSMOS-2.5は現在、テキストの空間座標を入力と出力として事前トレーニングしているにもかかわらず、自然言語の指示を使用してドキュメント要素の位置を細かく制御することはサポートしていません。広範な研究領域では、モデルのスケーリング能力の開発をさらに進めるという重要な方向性があります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ソウル国立大学の研究者たちは、効率的かつ適応性のあるロボット制御のための革新的なAI手法であるロコモーション・アクション・マニピュレーション(LAMA)を紹介しています
- 「マイクロソフトと清華大学によるこのAI研究は、EvoPromptという新しいAIフレームワークを紹介しますこのフレームワークは、LLMと進化アルゴリズムを接続するための自動的な離散プロンプト最適化を実現します」
- 「ReLU vs. Softmax in Vision Transformers Does Sequence Length Matter? Insights from a Google DeepMind Research Paper」 ビジョン・トランスフォーマーにおけるReLU vs. Softmax:シーケンスの長さは重要か?Google DeepMindの研究論文からの洞察
- 東京大学の研究者たちは、攻撃者から機密性の高い人工知能(AI)ベースのアプリケーションを保護するための新しい技術を紹介しました
- 「MITの新しい機械学習の研究では、階層的な計画(HiP)のための組成的な基礎モデルを提案しています:長期的な課題の解決のために言語、ビジョン、行動を統合する」
- UCIと浙江大学の研究者は、ドラフティングと検証のステージを使用した自己推測デコーディングによるロスレスな大規模言語モデルの高速化を紹介しました
- 「挑戦的に、マイクロソフトの研究者はGPT-4に「人工知能の火花」を見つけたと述べる」






