「大規模な言語モデルとベクトルデータベースを使用してビデオ推薦システムを構築した方法」
Method for building video recommendation system using large-scale language model and vector database
大規模な言語モデル、最新のテキストおよび音声解析ツール、およびベクトルデータベースを活用して、エンドツーエンドのオーディオ推薦ソリューションを構築します。
はじめに
私たちの世代は、オーディオからビデオコンテンツまで、あらゆる種類のストリーミングサービスを利用できる幸運な世代です。
私たちの電話、ノートパソコン、およびその他のデジタルデバイスから、これらのサービスがどれだけ迅速に生成されるかによって、簡単に圧倒されることがあります。
結局のところ、私たちは全宇宙が生成する曲やポッドキャストではなく、特定のタイプのコンテンツに興味を持つだけです 🌏。
この記事では、大規模な言語モデルとベクトルデータベースを活用して、ユーザーの興味に基づいてトップのビデオを提案するオーディオ推薦システムを作成する方法について学びます。
- 「Amazon Redshift」からのデータを使用して、Amazon SageMaker Feature Storeで大規模なML機能を構築します
- 「正しい方法で新しいデータサイエンスのスキルを学ぶ」
- 「機械学習モデルが医学的診断と治療において不公平を増幅する方法」
推薦ワークフローと主要なコンポーネント
技術的な実装に入る前に、構築しようとしている推薦システムの一般的なワークフローを見てみましょう。
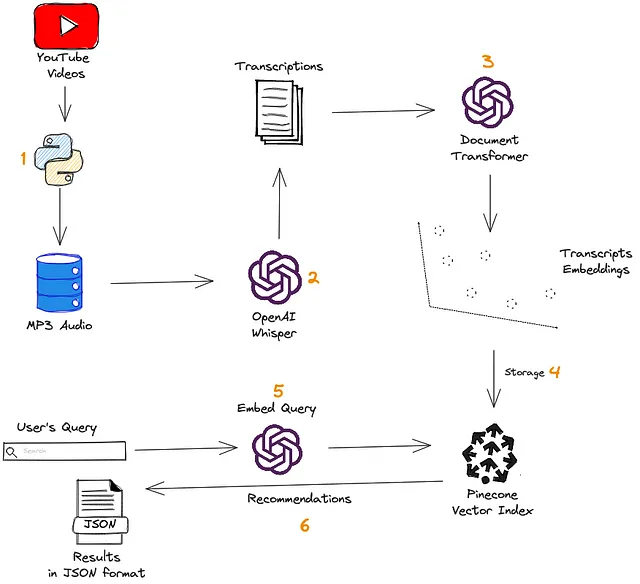
- まず、Pythonを使用してビデオを収集し、それぞれをオーディオに変換します。
- 次に、OpenAIの
whisperモデルを使用して、オーディオをテキストに変換します。 - その後、
text-embedding-ada-002モデルを使用して、転写埋め込みを生成します。 - これらの埋め込みを使用して、クエリを実行するためにベクトルデータベースが作成されます。
whisperモデルの概要
whisperモデルは、強力なテキスト読み上げモデルであり、音声認識や翻訳などのタスクにおける音声処理システムの能力を研究するために開発されました。
このモデルは、著者によれば、監督付き音声認識でこれまでに作成されたものの中でも最大のものの一つとされる、680,000時間のラベル付き音声データで訓練されました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「初心者のためのPandasを使ったデータフォーマットのナビゲーション」
- 「GPT4のデータなしでコードLLMのインストラクションチューニングを行う方法は? OctoPackに会いましょう:インストラクションチューニングコード大規模言語モデルのためのAIモデルのセット」
- 「データ主導的なアプローチを取るべきか?時にはそうである」
- 「Azure Data Factory(ADF)とは何ですか?特徴とアプリケーション」
- 「pandasのCopy-on-Writeモードの深い探求-パートII」
- 「データサイエンス(2023年)で学ぶべきこと」
- データセンターは、電力管理ソフトウェアの欠陥により危険にさらされています
