「ユナイテッド航空がコスト効率の高い光学文字認識アクティブラーニングパイプラインを構築した方法」
Method for building a cost-effective optical character recognition active learning pipeline by United Airlines
この投稿では、United AirlinesがAmazon Machine Learning Solutions Labとの協力のもと、AWS上で乗客のドキュメント処理を自動化するためのアクティブラーニングフレームワークを構築した方法について説明します。
「最高の飛行体験を提供し、内部のビジネスプロセスをできるだけ効率化するために、私たちはAWS上で自動化された機械学習ベースのドキュメント処理パイプラインを開発しました。コンピュータビジョンなど他のデータモダリティを使用するアプリケーションをパワーアップするためには、データの迅速な注釈付け、モデルのトレーニングと評価、そして迅速なイテレーションを可能にする堅牢かつ効率的なワークフローが必要です。数か月にわたり、UnitedはAmazon Machine Learning Solutions Labsと協力し、AWS CDKを使用した再利用可能なユースケースに依存しないアクティブラーニングワークフローを設計・開発しました。このワークフローは、非構造化データベースの機械学習アプリケーションの基盤となり、人間のラベリング作業を最小限に抑え、迅速に強力なモデルのパフォーマンスを提供し、データのドリフトに適応することができます。」
– United Airlinesのデータサイエンスおよび機械学習の上級マネージャー、ジョン・ネルソン氏
問題
Unitedのデジタルテクノロジーチームは、世界中の多様なメンバーが先端技術と共に協力してビジネス成果を上げ、顧客満足度を高めるために取り組んでいます。彼らは、コンピュータビジョン(CV)や自然言語処理(NLP)などの機械学習(ML)技術を活用してドキュメント処理パイプラインを自動化したいと考えています。この戦略の一環として、彼らは自社内でパスポート解析モデルを開発し、乗客のIDを検証しています。このプロセスでは、MLモデルのトレーニングに人手による注釈付けが必要であり、非常にコストがかかります。
- 『NVIDIAのCEO、ジェンソン・ファング氏がテルアビブで開催されるAIサミットの主演を務めます』
- AIはクリエイティブな思考のタスクで人間を上回ることができるのか?この研究は人間と機械学習の創造性の関係についての洞察を提供します
- 「AIとブロックチェーンの交差点を探る:機会と課題」
Unitedは、パスポート情報の検証、乗客の身元確認、および可能な不正なドキュメントの検出を自動化するための柔軟で堅牢かつコスト効率の高いMLフレームワークを作成したいと考えています。彼らはこの目標を達成するためにML Solutions Labと協力しました。これにより、Unitedは将来の乗客増加に対応しながら世界クラスのサービスを提供し続けることができます。
解決策の概要
私たちの共同チームは、AWS Cloud Development Kit(AWS CDK)を活用したアクティブラーニングフレームワークを設計・開発しました。このフレームワークは、必要なAWSサービスをプログラムで設定・プロビジョニングします。フレームワークは、Amazon SageMakerを使用して未ラベルのデータを処理し、ソフトラベルを作成し、Amazon SageMaker Ground Truthで手動ラベリングジョブを起動し、その結果のデータセットで任意のMLモデルをトレーニングします。また、名前やパスポート番号などの特定のドキュメントフィールドから情報を自動抽出するためにAmazon Textractを使用します。大まかなアプローチは、以下の図で説明されます。
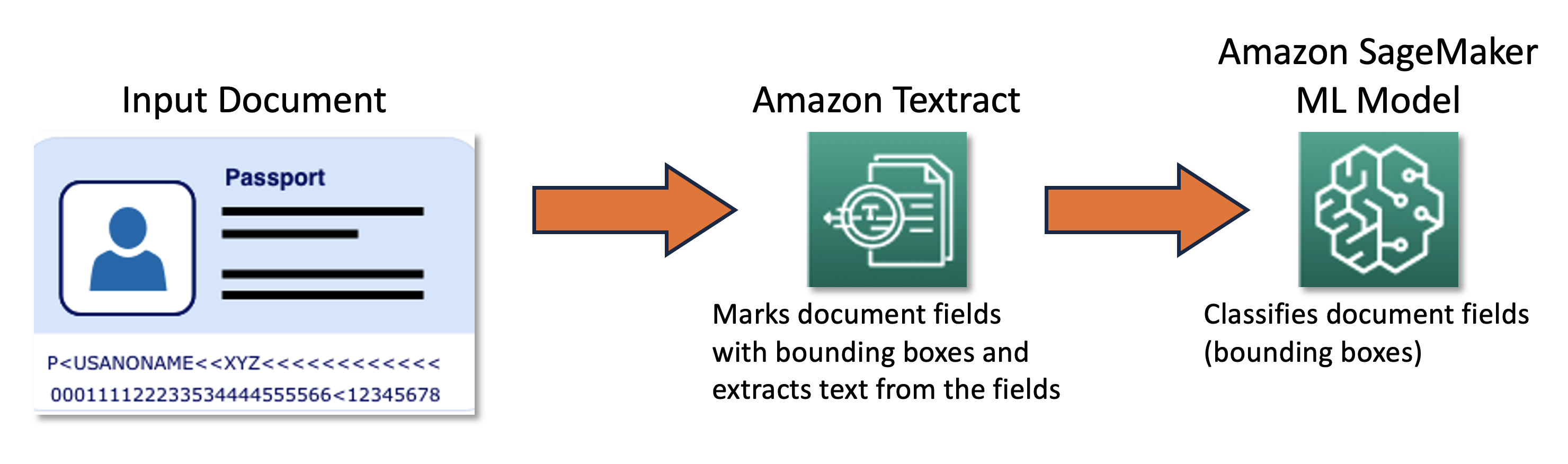
データ
この問題の主なデータセットは、数万枚のメインページのパスポート画像であり、個人情報(名前、生年月日、パスポート番号など)を抽出する必要があります。画像のサイズ、レイアウト、構造は発行国によって異なります。これらの画像を一連の統一されたサムネイルに正規化し、アクティブラーニングパイプライン(自動ラベリングと推論)の機能的な入力とします。
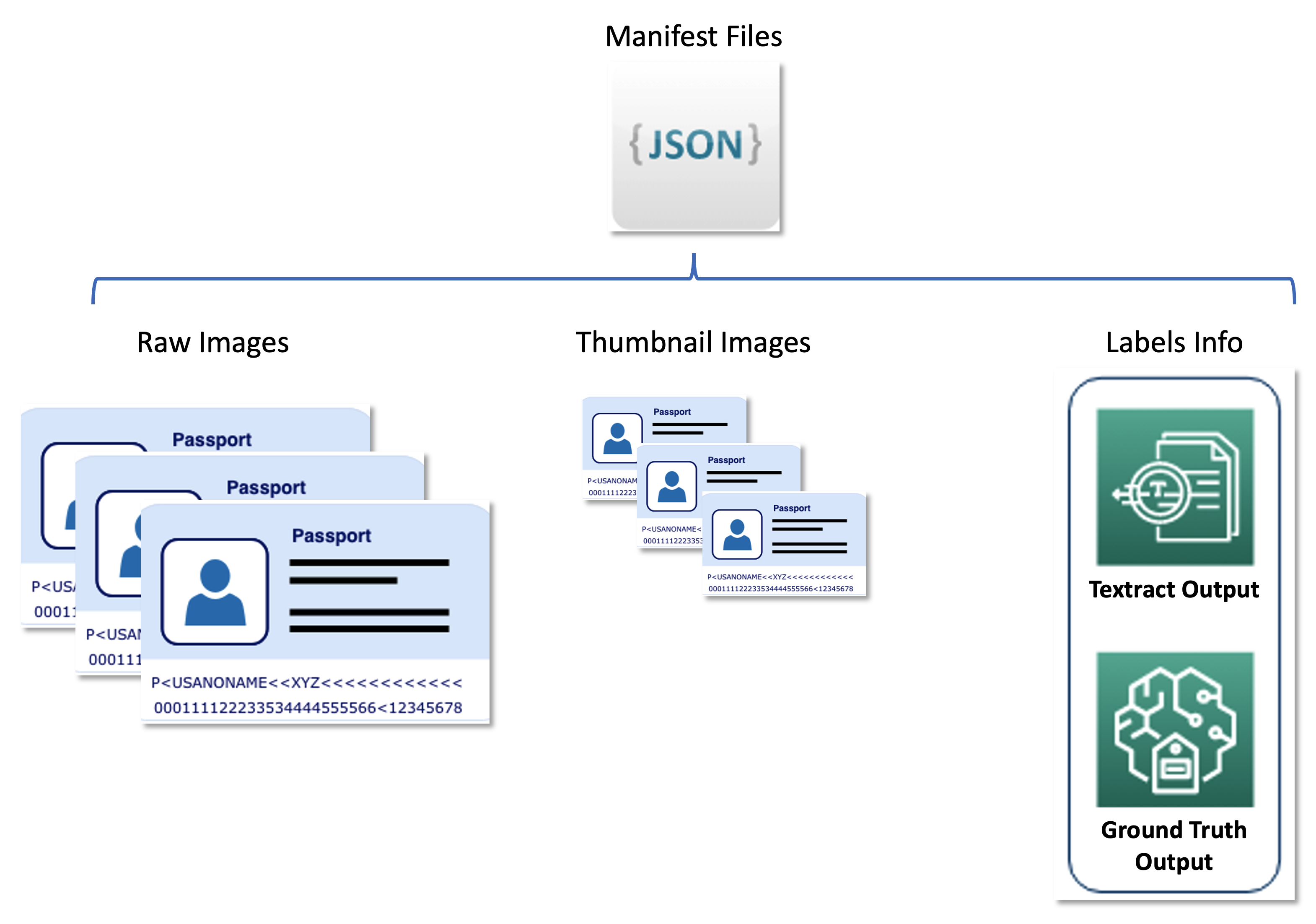
2番目のデータセットには、JSON行形式のマニフェストファイルが含まれており、生のパスポート画像、サムネイル画像、ソフトラベルやバウンディングボックスの位置などのラベル情報と関連付けられています。マニフェストファイルは、さまざまなAWSサービスの結果を統一された形式で格納するメタデータセットとして機能し、Unitedが使用する下流サービスからアクティブラーニングパイプラインを切り離します。以下の図は、このアーキテクチャを示しています。
次のコードは、マニフェストファイルの例です:
{
"raw-ref": "s3://bucket/passport-0.jpg",
"textract-ref": "s3://bucket/textract/passport-0.jpg",
"source-ref": "s3://bucket/clean-images/passport-0.jpg",
"page-num": 1,
"label": {
"image_size": [...],
"annotations": [
{
"class_id": 0,
"top": 1856,
"left": 1476,
"height": 67,
"width": 329
},
{"class_id": 1 ...},
{"class_id": 2 ...},
{"class_id": 3 ...},
{"class_id": 4 ...},
{"class_id": 5 ...},
{"class_id": 6 ...},
{"class_id": 7 ...},
{"class_id": 8 ...},
{"class_id": 9 ...},
{"class_id": 10 ...},
]
},
"label-metadata": {
"objects": [...],
"class-map ": {"0": "パスポート番号" ...},
"type": "groundtruth/object-detection",
"human-annotated": "yes",
"creation-date": "2022-09-19T00:58:55.729305",
"job-name": "labeling-job/passports-20220918-195035"
}
}ソリューションコンポーネント
このソリューションには、2つの主要なコンポーネントがあります:
- モデルのトレーニングを担当するMLフレームワーク
- コスト効率の良い方法でトレーニングモデルの精度を向上させるための自動ラベリングパイプライン
MLフレームワークは、MLモデルのトレーニングとSageMakerエンドポイントへの展開を担当します。自動ラベリングパイプラインは、SageMaker Ground Truthジョブの自動化とそれらのジョブを通じたラベリング用の画像のサンプリングに焦点を当てています。
これらの2つのコンポーネントは分離されており、ラベリングパイプラインによって生成された一連のラベル付きイメージを通じてのみ相互作用します。つまり、ラベリングパイプラインは、後でMLフレームワークによって使用されるラベルを作成します。
MLフレームワーク
ML Solutions Labチームは、Hugging Faceによる最先端のLayoutLMV2モデル(LayoutLMv2:Multi-modal Pre-training for Visually-Rich Document Understanding、Yang Xuなど)の実装を使用してMLフレームワークを構築しました。トレーニングは、Amazon Textractの出力を基に行われ、対象テキストの周りにバウンディングボックスを生成しました。このフレームワークは、分散トレーニングを使用し、SageMakerのプリビルトHugging FaceイメージをベースにしたカスタムDockerコンテナ上で実行されます(SageMakerのプリビルトDockerイメージに欠けているが、Hugging Face LayoutLMv2に必要な依存関係がある)。
MLモデルは、以下の11クラスのドキュメントフィールドを分類するためにトレーニングされました:
"0": "パスポート番号",
"1": "姓",
"2": "名",
"3": "国籍",
"4": "生年月日",
"5": "出生地",
"6": "性別",
"7": "発行日",
"8": "権限",
"9": "有効期限",
"10": "特記事項"
プリビルトイメージのパラメータは以下の通りです:
{
"framework": "huggingface",
"py_version": "py38",
"version": "4.17",
"base_framework_version": "pytorch1.10"
}カスタムイメージのDockerfileは以下の通りです(BASE_IMAGEは前述のベースイメージを指します):
ARG BASE_IMAGE
FROM ${BASE_IMAGE}
RUN pip install "amazon-textract-response-parser>=0.1,<0.2" "Pillow>=8,<9" \
&& pip install git+https://github.com/facebookresearch/detectron2.git
RUN pip install pytesseract "datasets==2.2.1" "torchvision>=0.11.3,<0.12"
RUN pip install setuptools==59.5.0トレーニングパイプラインは以下の図で要約されます。
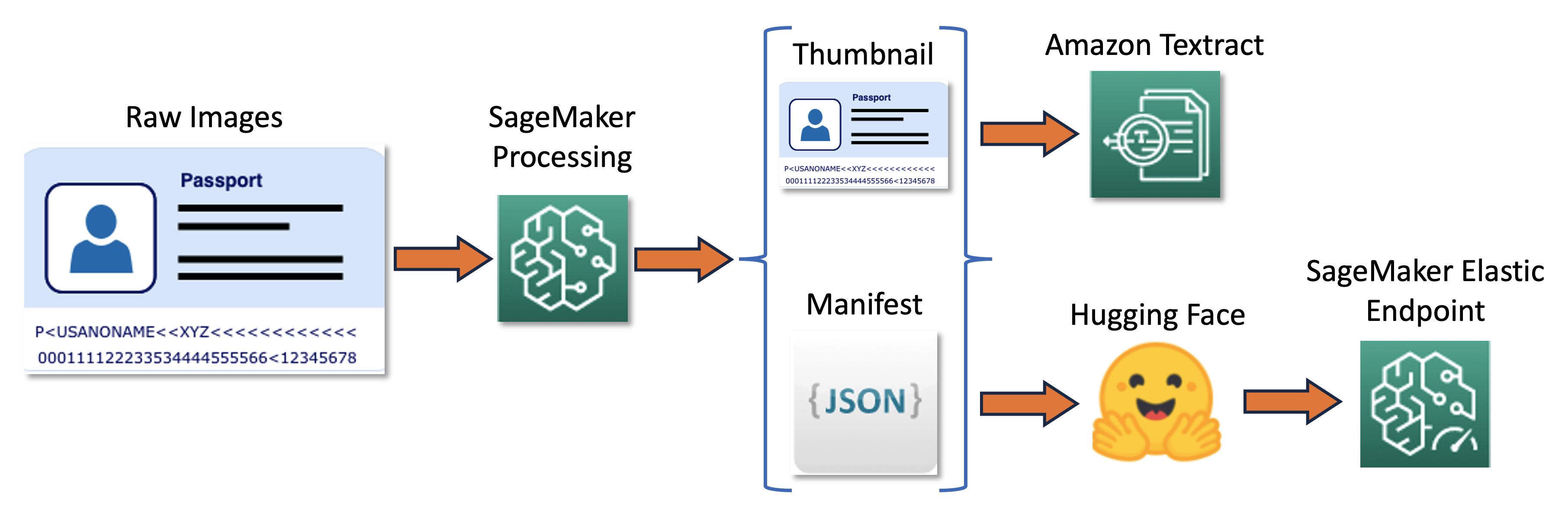
まず、一連の生の画像をサムネイルにリサイズし正規化します。同時に、バッチからの生の画像とサムネイル画像に関する情報を1行ごとに含むJSONラインマニフェストファイルが作成されます。次に、Amazon Textractを使用してサムネイル画像内のテキストバウンディングボックスを抽出します。Amazon Textractによって生成されたすべての情報は、同じマニフェストファイルに記録されます。最後に、サムネイル画像とマニフェストデータを使用してモデルをトレーニングし、後でSageMakerエンドポイントとして展開します。
自動ラベリングパイプライン
次の機能を実行するように設計された自動ラベリングパイプラインを開発しました:
- 未ラベルのデータセットに対して定期的なバッチ推論を実行します。
- 特定の不確実性サンプリング戦略に基づいて結果をフィルタリングします。
- 人間の労働力を使用してサンプリングされた画像をラベリングするためのSageMaker Ground Truthジョブをトリガーします。
- 新たにラベル付けされた画像をトレーニングデータセットに追加し、モデルの改善に使用します。
不確実性サンプリング戦略は、モデルの精度向上に最も貢献しそうな画像を選択することで、人間のラベリングジョブに送信される画像の数を減らします。人間のラベリングは高額な作業ですので、このようなサンプリングは重要なコスト削減技術です。以下の4つのサンプリング戦略をサポートしており、AWS Systems Managerのパラメータストアに保存されたパラメータとして選択できます:
- 最低信頼度
- 最大マージン信頼度
- 信頼度の比率
- エントロピー
全体の自動ラベリングワークフローは、AWS Step Functionsを使用して実装されており、処理ジョブ(バッチ推論のためのエラスティックエンドポイント)、不確実性サンプリング、およびSageMaker Ground Truthをオーケストレーションしています。以下の図は、Step Functionsのワークフローを示しています。

コスト効率
ラベリングコストに影響を与える主な要素は、手動注釈です。このソリューションを展開する前、ユナイテッドチームは高価な手動データ注釈とサードパーティのパースOCR技術を必要とするルールベースのアプローチを使用する必要がありました。当社のソリューションにより、ユナイテッドは、モデルの改善が最も見込まれる画像のみを手動でラベリングすることで、手動ラベリングの作業量を削減しました。フレームワークがモデルに依存しないため、パスポート画像を超えたより広範なドキュメントにも価値を提供できます。
以下の仮定に基づいてコスト分析を実施しました:
- 各バッチには1,000枚の画像が含まれています
- 訓練はmlg4dn.16xlargeインスタンスを使用して行われます
- 推論はmlg4dn.xlargeインスタンスで行われます
- 訓練は各バッチごとに注釈付きラベルの10%で行われます
- 訓練の各ラウンドで以下の精度改善が得られます:
- 最初のバッチ後に50%
- 2番目のバッチ後に25%
- 3番目のバッチ後に10%
当社の分析では、アクティブラーニングがない場合、訓練コストは一定で高くなります。アクティブラーニングを組み込むことで、新しいデータの各バッチごとに指数関数的にコストが減少します。
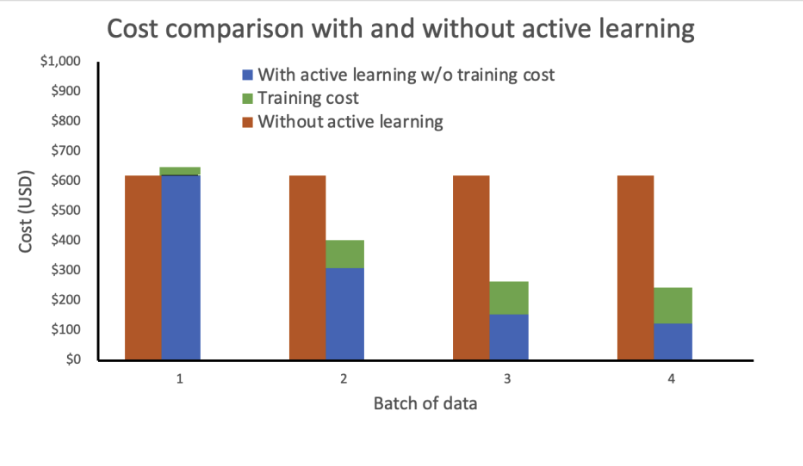
また、自動スケーリングポリシーを追加することで推論エンドポイントを弾力的なエンドポイントとして展開することで、コストをさらに削減しました。エンドポイントのリソースは、ゼロから設定された最大インスタンス数までスケーリングできます。
最終的なソリューションアーキテクチャ
私たちの焦点は、ユナイテッドチームが機能要件を満たしながらスケーラブルで柔軟なクラウドアプリケーションを構築することでした。MLソリューションラボチームは、AWS CDKの支援を受けながら、すべてのクラウドリソースとサービスの管理とプロビジョニングを自動化した、本番用の完全なソリューションを開発しました。最終的なクラウドアプリケーションは、4つのネストされたスタックで構成されるAWS CloudFormationスタックとしてデプロイされました。各スタックは、単一の機能コンポーネントを表しています。
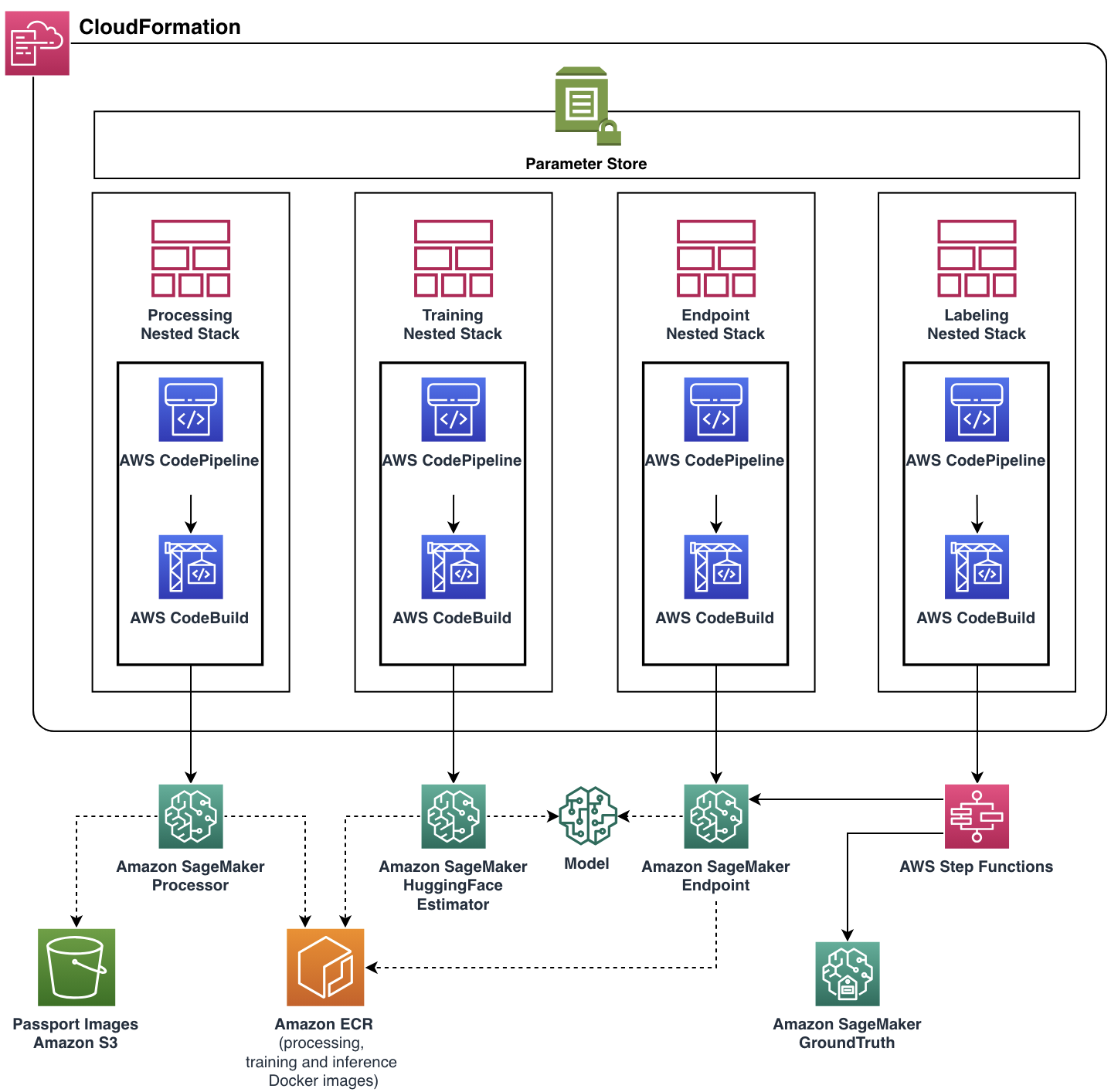
ほとんどのパイプライン機能、Dockerイメージ、エンドポイントの自動スケーリングポリシーなどは、Parameter Storeを介してパラメータ化されました。このような柔軟性により、同じパイプラインインスタンスをさまざまな設定で実行することができ、実験の能力を追加しました。
結論
この記事では、ユナイテッド航空がMLソリューションラボとの協力でAWS上にアクティブラーニングフレームワークを構築して、乗客ドキュメントの処理を自動化した方法について説明しました。このソリューションは、ユナイテッド航空の自動化目標の2つの重要な側面に大きな影響を与えました:
- 再利用性 – モジュラーな設計とモデル非依存の実装により、ユナイテッド航空はほぼすべての他の自動ラベリングMLユースケースでこのソリューションを再利用することができます
- 継続的なコスト削減 – 手動ラベリングプロセスと自動ラベリングプロセスを効果的に組み合わせることで、ユナイテッドチームは平均ラベリングコストを削減し、高価なサードパーティのラベリングサービスを置き換えることができます
同様のソリューションの実装に興味がある場合や、MLソリューションラボについて詳しく知りたい場合は、アカウントマネージャーにお問い合わせいただくか、Amazon Machine Learning Solutions Labのウェブサイトをご覧ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





