メタスの新しいテキストから画像へのモデル – CM3leon論文の説明
Meta's new model for text-to-image - CM3leon paper explanation
新しいSOTAで非常に効率的なテキストから画像への変換(そして逆も!)モデル。
![出典:構成:著者、画像:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*8uAXSsuPcTE8-K1TBS_ZLw.png)
Metaは最近、CM3Leonと呼ばれる最新のテキストから画像へのモデルを公開しましたが、これはStable-Diffusion [2]、Midjourney、またはDALLE [3]のような拡散を基にしていません。
それは検索増強型の自己回帰型デコーダーのみモデルです!
かなり長い説明になりますが、この記事ではそれがどういう意味なのかを知ることにします。この時点では、現在の画像生成モデルが素晴らしい画像を生成できることは既にわかっていますが、まだ特定の制約があります。例えば、それらのモデルの効率性とコストです。また、手を生成することもできません!しかしCM3Leonなら可能です。著者たちは非常に自信を持っているようです!
生成自体は素晴らしいですが、この自己回帰型デコーダーのアプローチによって画像からテキストへの変換の機能も可能になります!
- 「ライス大学とIITカーンプールは、共同研究賞の受賞者を発表します」という文を日本語に翻訳すると、以下のようになります: 「ライス大学とIITカーンプールは、共同研究賞の受賞者を発表します」
- CMUの研究者たちは、視覚的な先行知識をロボティクスのタスクに転送するためのシンプルなディスタンスラーニングAIメソッドを開発しました:ベースラインに比べてポリシーラーニングを20%改善
- 「MITとハーバードの研究者は、脳内の生物学的な要素を使ってトランスフォーマーを作る方法を説明する可能性のある仮説を提出しました」
結果
しかし、まずは結果となぜCM3Leonが特別なのかを詳しく見てみましょう。
![トレーニング中の等価A100 GPU時間に対するさまざまなモデルのFIDスコアの対数スケールのプロット。出典:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*pZ8E5XsgQzKl2Qrt-gpevA.png)
すでに素敵な生成画像を見ましたが、上記の図の数値を見ると、CM3leonがDALLEやPartiなどの他のモデルよりもはるかに優れていることが本当にわかります。FIDスコアが生成された画像のリアリズムを実際にどれだけ捉えているかは議論の余地がありますが、それにもかかわらず、CM3LeonはMS COCOデータセットで新しいSOTAのFIDスコアを達成しています。ただし、DALLEモデルの自己回帰バージョンを選択することは少し不公平かもしれません。
DALLEはどのように動作するのか?
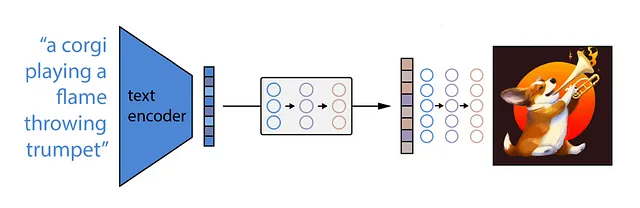
ちょっとした余談ですが、DALLEには中間モデルである「事前モデル」があります。これはCLIPによって生成されたテキスト埋め込みを対応する画像エンコーディングにマッピングし、それを拡散を使用して最終的な画像を生成するために使用します。この事前モデルは再び拡散プロセスまたは自己回帰プロセスのいずれかになります。どちらも似たような結果をもたらすようですが、拡散プロセスの方が効率的ですので、DALLEの著者たちはそれを選んだわけです。ですので、ここでの比較で効率の低いバージョンを選ぶのはDALLEに少し不公平かもしれません。
画像生成の結果に戻る
![FIDによって測定されたゼロショットMS-COCOタスク上のさまざまなテキストから画像へのモデルの要約。各入力クエリに対して8つのサンプルを生成し、CLIPモデルを使用して最良の生成を選択します。出典:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*coRfNm3CN8DmmXrylC_-5w.png)
さて、FIDスコアだけでも素晴らしいですが、さらに嬉しいことに、CM3Leonは非常に効率的であると同時にこの性能を達成しています!最大7兆パラメータのモデルでも、最大のPartiモデルよりもはるかに小さく、トレーニングデータと時間の使用もずっと少ないです!また、著者たちは「責任ある」トレーニングのための新しい尺度を導入しています。CM3Leonのトレーニングに使用される画像はすべてShutterstockからライセンスを取得しているため(おそらく)訴訟の心配がなくなります!そして、「検索されたドキュメントの数」の列もCM3Leonモデルの主な特徴の1つで、この後で詳しく説明します。要するに、テキストのプロンプトが与えられた場合、モデルは何らかの方法で関連する画像やテキストをメモリバンクから取得し、画像生成プロセスのさらなるコンテキストとして使用することができます。
ゼロショット生成とは何ですか?
今、私が疑問に思うのは、モデルが生成プロセスのためにさらなる画像を取得する場合、それは本当にゼロショット生成と見なされるのでしょうか? おそらくモデル自体が追加の画像を取得し、それらはモデルを促す人によって提供されていないのですが、はい、ここでは100%確信が持てません。
それに関連して、著者は抽象化の中で、「ゼロショットMS-COCO FID [スコア] 4.88」を達成するトップパフォーミングモデルについて言及しています。
CM3Leonは、比較可能な手法と比較してトレーニング計算量が5倍少ないテキストから画像の生成で最先端のパフォーマンスを達成します(ゼロショットMS-COCO FID 4.88)。 — 出典:[1]
しかし、このスコアは2つの取得された画像で達成されています。つまり、彼らは取得をゼロショットと呼んでいます。しかし、彼らの図1のキャプションでは、次のように述べています。
CM3Leonのゼロショット生成のショーケース(取得なしの拡張)。 — 出典:[1]
では、ゼロショット生成とは何ですか? 取得ありまたは取得なしでしょうか?
マルチモーダルベンチマーク
さて、ここまではすべて画像生成についてでしたが、このモデルは自己回帰型のデコーダーモデルであり、すべての大規模LLMと同様に、画像を通常のトークンとして解釈し、テキスト生成の文脈として使用することもできます! 言い換えれば、教師付きファインチューニング(またはSFTとも呼ばれる)を適用した後、モデルはより複雑なマルチモーダルタスクも実行できます。
![広範な組み合わせ画像とテキストのタスクを使用してCM3Leonモデルをファインチューニングした後の定量的な例。 出典:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*tDZ23diYuDA0n2CmNpMjRg.png)
「テキストガイド付き編集」や「画像対画像の生成」といったテキストと画像のタスクにおいて、セグメンテーションマップ、輪郭のみのスケッチ、または深度マップを提供し、それらとテキストプロンプトに基づいて新しい画像が生成されます。また、「空間的に基づいた画像生成」では、テキストプロンプト内のオブジェクトの座標を提供し、生成された画像はその座標にオブジェクトを配置します。さらに、モデルは画像内のテキストを生成するのにも非常に優れており、これはしばらくの間そうではありませんでした。しばらくの間とは、文字通り1年または2年前のことを指します :))最後に、正しい教師付きファインチューニングを行うと、CM3Leonは画像を入力として受け取り、イメージキャプショニング(短い回答または長い回答)、ビジュアルクエスチョンアンサリング、および推論などのタスクを実行することもできます。それはまだFlamingo [4]のような専用の画像キャプショニングモデルほど優れていませんが、これはほぼモデル設計の副産物であるため、結果は非常に印象的です!
CM3Leonはどのように機能しますか?
わかりました、でもCM3Leonはどのように機能し、リトリーバル補完、自己回帰型、デコーダーモデルとは何を意味するのでしょうか!?
この時点で、私たちはほぼみんなが拡散がどのように機能するかを知っています。モデルは画像のノイズを予測するように訓練されているため、完全にランダムなノイズから始めると、このモデルを適用してノイズを段階的に除去できます。このノイズ除去プロセスは、プロンプトとテキストに基づいて条件付けることもできるため、プロンプトで生成プロセスをガイドすることができます。
自己回帰モデルは少し異なる方法で機能します。Partiがこの自己回帰型画像生成モデルのアイデアを実装する方法を見てみましょう。
自己回帰型とは何ですか?
オートエンコーダーの動作原理を覚えていますか? エンコーダーネットワークは画像を埋め込みにマッピングし、デコーダーは潜在ベクトル表現から同じ画像を生成します。以下の画像では、このアイデアが緑のモジュールによって示されています。
![Partiで提案された画像生成のための自己回帰型エンコーダーデコーダーアーキテクチャ。 出典:[5]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*aw7AU-ZmRPk7WD9q0ta77g.png)
では、デコーダ(Partiの場合、detokenizerと呼ばれる)が画像を生成するために使用する埋め込みが、言語モデルによって予測されるトークンの形で提供される場合はどうなるでしょうか? GPTモデルがシンプルな「Start-of-Sequence」トークンで始まり、与えられた語彙の次のトークン、またはトークン埋め込みを予測する方法を思い浮かべてみてください。ビジョン・トランスフォーマーも、画像の各パッチ・トークンに対して埋め込みを生成し、それらは特定の語彙から選ばれるよう制約を設けることができます。つまり、私たちの自己回帰型テキスト・デコーダ(青いモジュール)は、各画像埋め込みトークンを生成し、その後、画像生成器(再び、ここではdetokenizerと呼ばれる)によって画像を生成することもできます。さて、画像トークン生成プロセスを制約するために、Partiはエンコーダ・デコーダのアプローチを採用することにしました。元々はテキストを翻訳するために設計された完全なTransformerアーキテクチャを使用しています。この場合、テキストの言語を画像の言語に翻訳するということ、つまり、テキストトークンを画像トークンに翻訳することです。言い換えると、テキストエンコーダ(黄色のモジュール)の埋め込みをテキストデコーダの条件として使用して、画像トークンを一つずつ予測します。
この自己回帰的アプローチは、拡散モデルが抱えるいくつかの問題を解決します。たとえば、自己回帰モデルは長いテキストプロンプトをよりうまく扱うことができ、画像内のテキストを非常にうまく生成することができます!ただし、それはスケールによってのみ実現できます。単純に大きくすればうまくいくというケースは、ここでは非常に極端です。例えば、カンガルーとテキスト「Welcome Friends!」を使用したこの例を見てみましょう。
![画像は同じプロンプトで異なるモデルサイズを使用して生成されました。出典:[5]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*m5Q-OZR5FEwBeVusMgHG6w.png)
デコーダのみとは何ですか?
わかりました、自己回帰型の画像生成がどのように機能するかはわかりましたが、CM3LeonはPartiのようなエンコーダ・デコーダモデルではなく、自己回帰型のデコーダのみモデルです。これは、生成プロセスのテキスト条件付けがエンコーダとクロスアテンションを介してではなく、単純なテキストトークンとしてデコーダのコンテキストで行われることを意味します。つまり、語彙には画像トークンの語彙(著者は既存のトークナイザを使用)とテキストトークンの語彙(著者自身が新しいトークナイザを訓練)が含まれる必要があります。さらに、著者はモダリティの遷移を示す新しい<break>トークンも導入しています。
![マルチモーダルドキュメントのイラスト。テキストと画像トークンが含まれる単一のシーケンス。出典:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*XVKMg9_xFHHF60rAYH5TFw.png)
これで、デコーダの入力と出力は次のようになるでしょう。例えば、プロンプト「A Photo of a cat shown on a dslr」から始め、次に<break>トークンが続き、デコーダが次々に次の画像トークンを予測します。別の<break>トークンまたは<EOS>トークンに到達すると、画像デコーダが引き継いで画像を生成できます!
トレーニングデータの場合、モデルは「Image of a chameleon:」のようなマルチモーダルなケースを処理することができ、そこではモデルは通常の次のトークン予測の損失に基づいて訓練されます。
「Image of a chameleon:」 → 「<Img233>」、「<Img44>」、…
ただし、これはまた、モデルが単純に同じ例を再フォーマットして、サンプルの特定の部分をマスクし、モデルに<infill>リクエストの後にマスクされた部分を予測させることで画像キャプションのタスクを処理することも意味します。
「Image of a <mask>: <Img233>、… <infill> →」chameleon」
つまり、モデルは画像を見て、その画像に何が含まれているかを予測する必要があります。
私たちのモデルは今やテキストと画像の両方を生成することができます。
自己回帰型、チェック。デコーダのみ、チェック。最後に、この「検索補完」の仕組みはどのように機能するのでしょうか?
リトリーバル増強とは何ですか?
すでに述べたとおり、これは初期のプロンプトが与えられた場合、モデルは画像またはテキスト、または両方を検索し、そのコンテキストに追加することができることを意味します。デコーダーのみのモデルへの入力の仕組みがわかったので、コンテキストに簡単に画像やテキストを追加する方法も理解できます。
![多くの交互に挿入された画像とテキスト要素を持つ完全なデータサンプルのイラスト。出典:[1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*sSkA2eGMMaXxDYg3whPPYw.png)
最大コンテキスト長が許す限り、単純に<break>トークンの間にあるテキストと画像を追加するだけです!シーケンス長が4096であれば、1つまたは2つの検索されたドキュメントを追加できます。ここでのドキュメントとは、単一の画像またはテキスト、または画像とキャプションのペアなどの要素を指します。
CM3LeonはRA-CM3論文[6]に基づいて構築されており、これはCM3論文[7]で提案された手法にこのリトリーバル増強機能を追加することを提案しています。これが研究ですね、1つの論文が別の論文に基づいて構築されているのです!
RA-CM3論文では、与えられたテキストプロンプトに対して画像を検索した場合の効果が非常によく見えます。
![メモリバンクから1つの画像を検索した場合の画像生成プロセスの効果。出典:[6]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*lihnjpu0CpKIt-SmcyL7aw.png)
例えば、ここでは「ムーンの表面でフランスの旗が振られている」というプロンプトに対する出力を見ることができます。リトリーバルなしの通常のCM3では、アメリカの旗が月に置かれますが、今回コンテキストにフランスの旗の画像を追加すると、RA-CM3は適切な結果を生成します。2つの画像を検索する場合など、同様の効果が見られます。
![画像生成/インペイントプロセスにおいて画像を手動で指定した場合の効果。出典:[6]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*6-pKivvIa4X2rBSFxJoVxA.png)
もちろん、これにより生成される画像のスタイルを制御するために画像を手動で指定することも可能です。この例では、赤いジャケットを着た人の画像を提供すると、モデルは赤いジャケットを着た人をインペイントします。
それでは、このリトリーバルはどのように機能するのでしょうか?アイデアは実際には非常にシンプルです。著者たちは、市販のCLIPモデルを使用して入力クエリ(例:単純なテキストプロンプト)をエンコードし、関連スコアによってメモリバンクから類似した候補をソートします。メモリバンク内の個々のテキストと画像の例は、単にCLIPモデルを通過しますが、画像とキャプションのドキュメントでは、テキストと画像を分割し、それぞれをエンコードしてから、ドキュメント全体のベクトル表現として2つのベクトルの平均を取ります。
著者たちは最も類似したドキュメントを単純に選択するのではなく、検索をより情報豊かにするために異なるヒューリスティックを使用しています。例えば、画像とテキストから成るドキュメントの方がテキストのみや画像のみよりも情報が豊富です。また、クエリとほぼ同じドキュメントがすでに検索されている場合や、同じドキュメントがすでに検索されている場合は、候補ドキュメントをスキップします。その他のいくつかのトリックもあります。
モデルの出力自体をさらに効果的にするための他の細かな(但し重要な!)詳細もありますが、それらは基本的には新しいアイデアではなく、一般的にパフォーマンスを向上させるために現れる付加的なトリックです。例えば、異なる温度値をランダムにサンプリングしたり、TopPサンプリングと呼ばれる手法を適用したり、推論中にクラシファイヤフリーガイダンスを適用したり、Contrastive Decodingの独自の適応を行ったりします。
結局のところ、リトリーバル増強型の自己回帰型デコーダーのCM3Leonモデルの動作と可能なことを知ることができました。このリトリーバルのアイデアは、モデルがパラメーターとデータの効率性が非常に高いことに大きく貢献しています!
![メモリバンクからの二つの画像の取得が画像生成プロセスに与える影響。出典:[6]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*yHR0SJSwE13YVHt-obxTtg.png)
モデルは、例えば桜の木やラッシュモア山のようなものの外観を記憶する必要はありません。そして、デコーダーのみのアーキテクチャを使用することで、トレーニングや新しいタスクへの微調整が容易になります!
潜在的に拡散モデルが画像生成に最適な方法であると考えている場合、この論文はまた、有名なトランスフォーマーモデルなどの自己回帰モデルが広範なテキストや画像のタスクに対してどれほど強力であるかを示しています。
もしこの記事がお気に入りだった場合、拍手を残してフォローしてください。さらに興味深いAI論文解説記事をお楽しみいただけます!
P.S.: もしこのコンテンツやビジュアルが気に入った場合、YouTubeチャンネルも覗いてみてください。そこでは同様のコンテンツがより洗練されたアニメーションと共に公開されています!
参考文献
[1] Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning、L. Yu, B Shi, R Pasunuru, et al., 2023、論文へのリンク
[2] High-Resolution Image Synthesis with Latent Diffusion Models、R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B., 2021、https://arxiv.org/abs/2112.10752
[3] Zero-Shot Text-to-Image Generation、Ramesh et al., 2021、https://arxiv.org/abs/2102.12092
[4] Flamingo: a Visual Language Model for Few-Shot Learning、B. Alayrac, J. Donahue, P. Luc, A. Miech et al., 2022、https://arxiv.org/abs/2204.14198
[5] Scaling Autoregressive Models for Content-Rich Text-to-Image Generation、Yu et al., 2022、https://arxiv.org/abs/2206.10789
[6] Retrieval-Augmented Multimodal Language Modeling、Yasunaga et al., 2022、https://arxiv.org/abs/2211.12561
[7] CM3: A Causal Masked Multimodal Model of the Internet、A. Aghajanyan et al., 2022、https://arxiv.org/abs/2201.07520
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Google DeepMindの研究者は、機能を維持しながら、トランスフォーマーベースのニューラルネットワークのサイズを段階的に増やすための6つの組み合わせ可能な変換を提案しています
- 「LangChainとGPT-4を使用した多言語対応のFEMAディザスターボットの研究」
- コンピュータ科学の研究者たちは、モジュラーで柔軟なロボットを作りました
- MITの研究者は、ディープラーニングと物理学を組み合わせて、動きによって損傷を受けたMRIスキャンを修正する方法を開発しました
- 「NTUとSenseTimeの研究者が提案するSHERF:単一の入力画像からアニメーション可能な3D人間モデルを復元するための汎用的なHuman NeRFモデル」
- このUCLAのAI研究によると、大規模な言語モデル(例:GPT-3)は、様々なアナロジー問題に対してゼロショットの解決策を獲得するという新たな能力を獲得していることが示されています
- SalesforceのAI研究者が、LLMを活用した自律エージェントの進化と革新的なBOLAA戦略を紹介します






