MeLoDyとは:音楽合成のための効率的なテキストからオーディオへの拡散モデル
MeLoDy is an efficient text-to-audio propagation model for music synthesis.


音楽は、調和、メロディ、リズムから成る芸術であり、人生のあらゆる面に浸透しています。深層生成モデルの発展に伴い、音楽生成は近年注目を集めています。言語モデル(LM)は、長期的な文脈にわたる複雑な関係をモデリングする能力において、顕著なクラスの生成モデルとして、音声合成にLMを成功裏に応用することができるAudioLMやその後の作品が登場しています。DPM(拡散確率モデル)は、生成モデルのもう1つの競争力のあるクラスとして、音声、音楽の合成に優れた能力を発揮しています。
しかし、自由形式のテキストから音楽を生成することは依然として課題であり、許容される音楽の記述が多様で、ジャンル、楽器、テンポ、シナリオ、あるいは主観的な感情に関連していることがあります。
従来のテキストから音楽を生成するモデルは、しばしば音声の継続や高速サンプリングなど特定の特性に焦点を当て、一部のモデルは音楽プロデューサーなどの専門家によって実施される堅牢なテストを優先しています。さらに、ほとんどのモデルは大規模な音楽データセットでトレーニングされ、高い忠実度とテキストプロンプトのさまざまな側面への遵守とともに、最先端の生成性能を示しています。
しかし、MusicLMやNoise2Musicなどのこれらの手法の成功は、実用性に重大な影響を与える高い計算コストと引き換えに得られています。比較的、DPMに基づく他の手法は、高品質な音楽の効率的なサンプリングを実現しました。しかしながら、彼らが示したケースは比較的小さく、サンプリング効果が制限されていました。実現可能な音楽作成ツールを目指すにあたり、生成モデルの高い効率性は、人間のフィードバックを考慮に入れたインタラクティブな作成を促進するために不可欠です。
LMとDPMの両方が有望な結果を示しているにもかかわらず、関連する問題は、どちらを好むかではなく、両方の方法の利点を同時に活用できるかどうかです。
上記の動機に基づき、MeLoDyと呼ばれるアプローチが開発されました。戦略の概要は、以下の図に示されています。
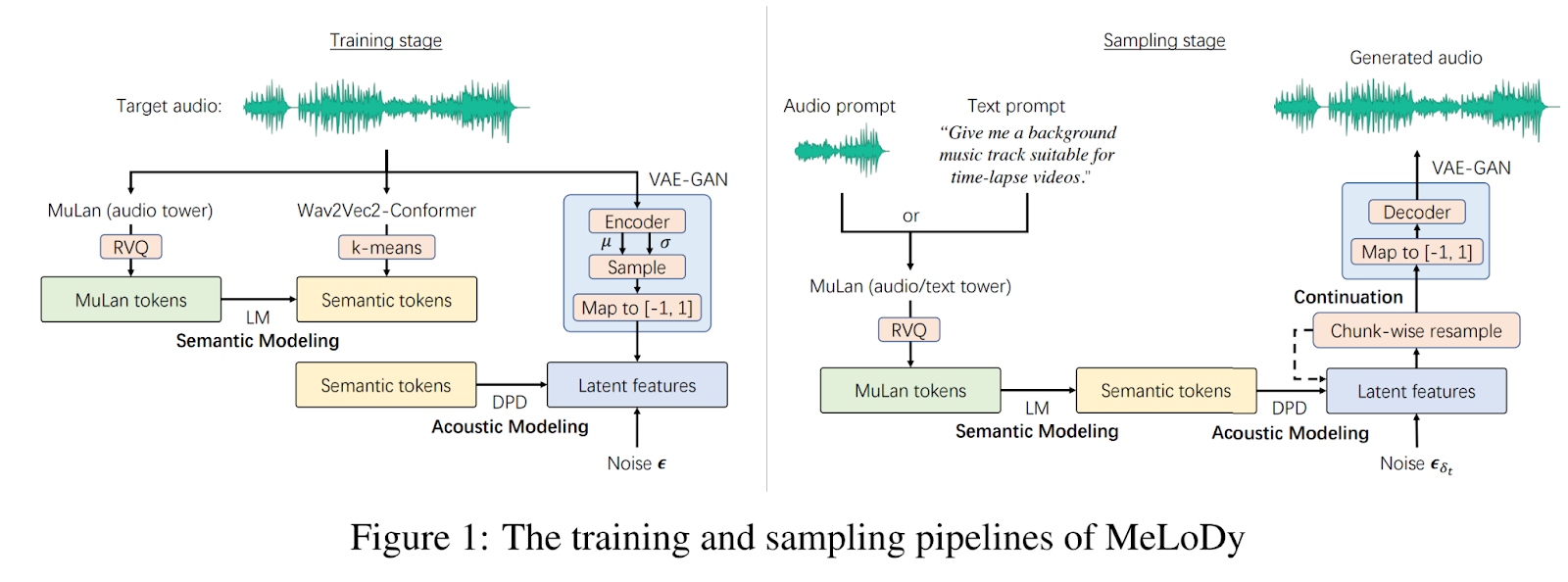
MusicLMの成功を分析した後、著者たちは、MusicLMの最高レベルのLMである「意味LM」を活用して、メロディ、リズム、ダイナミクス、音色、テンポの全体的なアレンジメントを決定する音楽の意味構造をモデリングします。この意味LMに条件付けられた上で、非自己回帰性のDPMを活用して、成功したサンプリングの加速技術を用いて、音響を効率的かつ効果的にモデリングします。
さらに、著者たちは、古典的な拡散プロセスを採用する代わりに、デュアルパス拡散(DPD)モデルを提案しています。実際、生データで作業することは、計算費用を指数関数的に増加させることになります。提案された解決策は、生データを低次元の潜在表現に縮小することです。データの次元を減らすことで、操作に対するその影響を阻害し、したがって、モデルの実行時間を短縮することができます。その後、生データは、事前にトレーニングされたオートエンコーダを介して、潜在表現から再構築されることができます。
モデルによって生成されたいくつかの出力サンプルは、以下のリンクから入手できます:https://efficient-melody.github.io/。コードはまだ利用可能ではないため、現時点ではオンラインまたはローカルで試すことはできません。
これは、最先端の品質の音楽オーディオを生成する効率的なLMガイド拡散モデルであるMeLoDyの概要でした。興味がある場合は、以下のリンクでこの技術について詳しく学ぶことができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- AIの未来を形作る ビジョン・ランゲージ・プリトレーニング・モデルの包括的な調査と、ユニモーダルおよびマルチモーダルタスクにおける役割
- FastAPI、AWS Lambda、およびAWS CDKを使用して、大規模言語モデルのサーバーレスML推論エンドポイントを展開します
- ディープラーニングが深く掘り下げる:AIがペルー砂漠で新しい大規模画像を公開
- 線形回帰の理論的な深堀り
- GPTとBERT:どちらが優れているのか?
- DeepMind RoboCat:自己学習ロボットAIモデル
- BITEとは 1枚の画像から立ち姿や寝そべりのようなポーズなど、困難なポーズでも3D犬の形状とポーズを再構築する新しい手法






