「WebAgentに会いましょう:DeepMindの新しいLLM、ウェブサイト上での指示に従ってタスクを完了する」
Meet WebAgent DeepMind's new LLM that completes tasks following instructions on websites.
モデルは言語理解とウェブナビゲーションを組み合わせています。

最近、AIに焦点を当てた教育ニュースレターを始めました。既に16万人以上の購読者がいます。TheSequenceは、5分で読むことができる、ハイプやニュースなどのない、機械学習に特化したニュースレターです。目標は、機械学習プロジェクト、研究論文、概念について最新情報を提供することです。以下のリンクから購読して試してみてください:
TheSequence | Jesus Rodriguez | Substack
機械学習、人工知能、データの最新情報を得るための最良のソース…
thesequence.substack.com
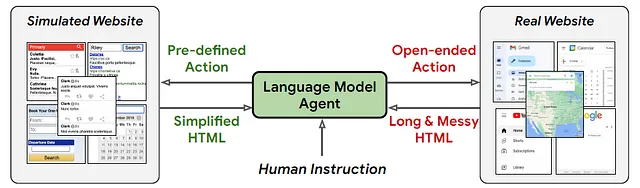
大規模言語モデル(LLM)とウェブサイトの統合は、LLMを利用した新たなアプリケーションの波を開く可能性のある分野の一つです。LLMは、基本的な算術や論理的な推論から、常識的な理解、質問応答、さらには対話型の意思決定など、さまざまな自然言語タスクで優れた能力を示しています。これらの能力をウェブナビゲーションと組み合わせることで、非常に強力な組み合わせが実現されます。最近、Google DeepMindはWeb Agentという、ユーザーの指示に基づいて実際のウェブサイトをナビゲートするLLM駆動の自律エージェントを発表しました。
ウェブナビゲーションの実装は、以下のような一意な課題を提起しています:
(1)事前に定義されたアクションスペースの不在。
(2)シミュレータと比較してはるかに長いHTML観察の存在。
(3)LLM内でのHTMLに関するドメイン固有の知識の不足。
これらのハードルは、現実のウェブサイトの無制限な性質と指示の複雑さによって引き起こされるものであり、事前に適切なアクションスペースを定義することが困難です。一部の研究では、教示の微調整や人間からのフィードバックによる強化学習などがHTMLの理解とナビゲーションの精度を向上させる可能性を示していますが、LLMの設計は常にHTMLドキュメントの効果的な処理に最適化されているわけではありませんでした。具体的には、ほとんどのLLMは比較的短いコンテキスト長しか持っておらず、実際のウェブサイトにある平均トークン長を処理するのに十分ではなく、構造化ドキュメントの処理に必要な重要な技術を採用していない場合があります。
WebAgentの登場
WebAgentは、各ステップごとにサブ指示を計画し、これらのサブ指示に基づいて長いHTMLページを関連するスニペットに要約し、サブ指示とHTMLスニペットを実行可能なPythonコードに基づいて接地します。Google DeepMindは、WebAgentを構築するために2つのLLM、「Flan-U-PaLM」(接地コード生成)と「HTML-T5」(タスク計画と条件付きHTML要約を担当する新たに導入されたドメインエキスパートの事前トレーニング言語モデル)を組み合わせています。エンコーダーデコーダーアーキテクチャで設計されたHTML-T5は、ローカルおよびグローバルなアテンションメカニズムを利用して、長いHTMLページの構造をキャプチャすることに優れており、CommonCrawlから合成された広範なHTMLデータコーパスでセルフサプリービスの事前トレーニングを行っています。
既存のLLM駆動エージェントは通常、単一のLLMで決定タスクを処理し、役割ごとに異なる例をプロンプトとして使用します。しかし、より複雑な現実世界のタスクに対しては、このアプローチでは不十分です。Google DeepMindの包括的な評価によると、WebAgentの組み合わせ手法は、プラグイン言語モデルを統合することで、HTMLの理解と接地を大幅に改善し、より良い汎化を実現しています。WebAgentは、実世界のウェブナビゲーションの成功率が50%以上向上し、詳細な分析によってタスク計画とHTML要約を専門の言語モデルを使用して結びつけることが成功したタスク実行における重要な役割を明らかにしています。さらに、WebAgentは静的なウェブサイト理解のタスクでも優れたパフォーマンスを発揮し、QAの精度で単一のLLMを上回り、強力なベースラインに対して競争力を持っています。
Google DeepMindのWebAgentは、HTML-T5とFlan-U-PaLMという2つの異なる言語モデルの革新的な組み合わせであり、ウェブナビゲーションとHTMLドキュメントの処理を可能にする効率的なウェブオートメーションタスクです。
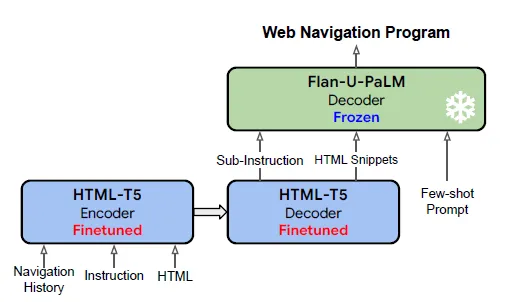
HTML-T5は、次のステップのプログラムのサブ命令を予測し、長いHTMLドキュメントの要約を条件付きで行うために重要な役割を果たす、ドメインエキスパートエンコーダーデコーダーモデルです。この特殊なモデルは、T5、Flan-T5、Instruct-GPTなどの言語モデルの一般的な機能(強力なHTML理解を持つウェブナビゲーション能力)と、Guoらによって提案されたような、HTML固有の帰納バイアスを備えたプライオントランスフォーマーモデルとのバランスを取ります。HTML-T5は、エンコーダーでローカルとグローバルの注意機構を活用して、HTML入力の階層構造を効果的に処理します。ローカルの注意は、HTMLの各要素(例:、
従来の自然言語モデルで使用される密な注意とは異なり、HTML-T5はローカルとグローバルの注意機構の採用により、HTMLドキュメントに明示的な階層構造をより適切に捉えることができます。HTMLの葉要素(例:、
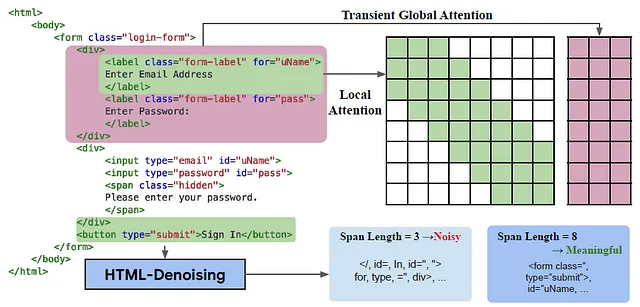
HTML-T5を実装するために、Google DeepMindはLongT5の基本アーキテクチャをベースに構築しています。このローカルとグローバルの注意機構とデコーダーの密な注意の組み合わせは、ウェブオートメーションのタスクにおいてHTMLドキュメントを処理するための効果的かつバランスの取れた解決策を提供します。
結果
Google DeepMindのWebAgentの能力を示すために、不動産のウェブサイトのコンテキストで自動化を見てみましょう。この設定では、WebAgentは、計画、要約、および具体的なプログラム合成を包括する強力なフローを具体化します。このプロセスでは、HTML-T5がリードを担当し、HTMLドキュメント、指示、および過去の予測を詳細に分析して、分解されたサブ命令とタスクに関連するスニペット(オレンジで示される)を予測するための反復的なアプローチを採用します。同時に、オレンジのサブ命令とスニペットによってトリガーされるFlan-U-PaLMは、青で表されるPythonプログラムを巧みに復号化します。

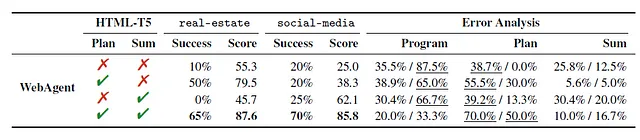
WebAgentによって達成された結果は、実際のウェブサイトで70%の成功率を誇ります。この重要な進展は、単一のLLMアプローチのパフォーマンスを50%以上も上回ります。この成果は、タスクをサブ問題のシーケンスに分解し、異なる言語モデルによってそれぞれ処理することで、全体的なタスクの成功を大幅に向上させることができることを示しています。
さらに、Google DeepMindは、HTMLに特化した言語モデルを作成するための革新的かつスケーラブルな手法を提案しています。このアプローチでは、ローカルとグローバルの注意機構を長いスパンのデノイジング目的を組み合わせてトレーニングすることが含まれています。究極の目標は、HTMLドキュメントの基礎となる階層構造を巧みに捉え、HTML関連のタスクの理解と効果的な処理を向上させることです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles