「BLIVAと出会ってください:テキスト豊かなビジュアル質問をより良く扱うためのマルチモーダルな大規模言語モデル」
Meet BLIVA A multimodal large-scale language model for better handling text-rich visual questions.


最近、大規模言語モデル(LLMs)は、自然言語理解の分野で重要な役割を果たしており、ゼロショットやフューショットのシナリオを含む幅広いタスクの一般化能力において、素晴らしい能力を示しています。OpenAIのGPT-4などのVision Language Models(VLMs)は、画像または一連の画像に関する質問に答えるためにモデルが答える必要があるオープンエンドのビジュアルクエスチョンアンサリング(VQA)タスクの解決において、大きな進展を遂げています。これらの進展は、LLMsと視覚理解能力の統合によって実現されています。
視覚関連のタスクにおいてLLMsを活用するために、視覚エンコーダのパッチ特徴との直接的なアライメントや、一定数のクエリ埋め込みを介した画像情報の抽出など、様々な手法が提案されています。
しかし、これらのモデルは、画像内のテキストを解釈する際に課題に直面します。テキストを含む画像は日常生活でよく見られ、このようなコンテンツを理解する能力は人間の視覚知覚にとって重要です。以前の研究では、クエリ埋め込みを使用した抽象モジュールが使用されていましたが、このアプローチでは画像内のテキストの詳細を捉える能力が制限されていました。
本記事で概説されている研究では、研究者らはBLIVA(InstructBLIP with Visual Assistant)というマルチモーダルLLMを紹介しています。このモデルは、LLM自体と密接に関連する学習済みのクエリ埋め込みと、より広範な画像関連データを含む画像エンコードされたパッチ埋め込みという2つの主要なコンポーネントを統合するように戦略的に設計されています。提案手法の概要は以下の図に示されています。
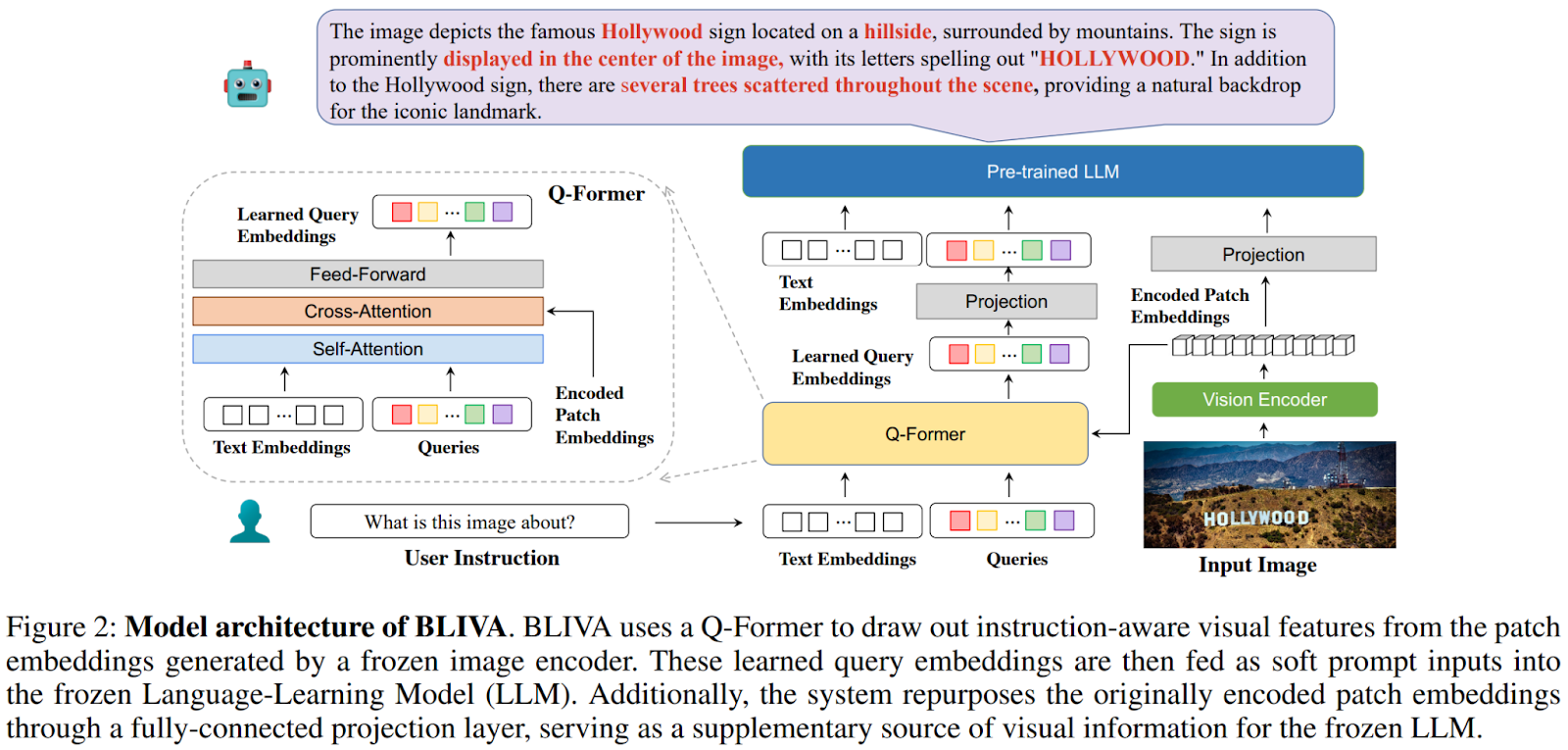
この技術は、通常言語モデルに画像情報を提供する際に関連する制約を克服し、最終的にはテキスト-イメージの視覚知覚と理解を向上させるものです。モデルは、事前学習済みのInstructBLIPと、ゼロからトレーニングされたエンコードされたパッチ射影層を使用して初期化されます。2段階のトレーニングパラダイムが採用されています。初期段階では、パッチ埋め込み射影層の事前トレーニングと、インストラクションチューニングデータを使用してQ-formerとパッチ埋め込み射影層の両方を微調整します。このフェーズでは、実験から得られた2つの主な結果に基づいて、画像エンコーダとLLMの両方が凍結された状態に保たれます。第一に、ビジョンエンコーダを凍結解除すると、以前の知識の大規模な忘却が起こります。第二に、LLMの同時トレーニングは改善をもたらさず、トレーニングの複雑さを導入します。
著者によって示された2つのサンプルシナリオは、”詳細なキャプション”および”小さなキャプション+VQA”に関連するVQAタスクにおけるBLIVAの影響を示しています。

これが、VQAタスクに取り組むためにテキストとビジュアルエンコードされたパッチ埋め込みを組み合わせる革新的なAI LLMマルチモーダルフレームワークであるBLIVAの概要でした。興味があり、さらに詳しく知りたい場合は、以下に引用されたリンクを参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






