メディアでの顔のぼかしの力を解き放つ:包括的な探索とモデルの比較
Media Face Blurring Comprehensive Exploration and Model Comparison
さまざまな顔検出とぼかしアルゴリズムの比較

今日のデータ駆動型の世界では、個人のプライバシーと匿名性を確保することが最も重要です。個人のアイデンティティを保護したり、GDPRのような厳格な規制に準拠したりするために、さまざまなメディア形式で顔を匿名化するための効率的で信頼性の高いソリューションの必要性はこれまでにないほど高まっています。
目次
- はじめに
- 顔検出- Haar Cascade- MTCNN- YOLO
- 顔ぼかし- ガウシアンぼかし- ピクセル化
- 結果と議論- リアルタイム性能- シナリオに基づく評価- プライバシー
- 動画での利用
- ウェブアプリケーション
- 結論
はじめに
このプロジェクトでは、顔ぼかしのトピックについていくつかのソリューションを探求し、簡単な評価が可能なウェブアプリケーションを開発します。このようなシステムの需要を牽引する多様なアプリケーションを探求しましょう:
- プライバシーの保護
- 規制環境のナビゲーション:規制環境が急速に進化する中で、世界中の産業や地域が個人のアイデンティティを保護するためにより厳格な基準を実施しています。
- トレーニングデータの機密性:機械学習モデルは多様で十分に準備されたトレーニングデータに基づいて発展します。しかし、このようなデータを共有するには注意深い匿名化が必要です。
このソリューションは、2つの重要なコンポーネントに分解できます:
- 顔検出
- 顔ぼかし技術
顔検出
匿名化の課題に対処するために、最初のステップは画像内の顔が存在する領域を特定することです。この目的のために、私は画像検出のために3つのモデルをテストしました。
- 「教師付き学習の実践:線形回帰」
- 「トランスフォーマーとサポートベクターマシンの関係は何ですか? トランスフォーマーアーキテクチャにおける暗黙のバイアスと最適化ジオメトリを明らかにする」
- 富士通とLinux Foundationは、富士通の自動機械学習とAIの公平性技術を発表:透明性、倫理、アクセシビリティの先駆者
Haar Cascade

Haar Cascadeは、画像や動画などのオブジェクト検出に使用される機械学習手法です。これは、画像の領域内のピクセルの強度変動に焦点を当てたシンプルな矩形フィルタである「Haar-like特徴」(図1)を利用して動作します。これらの特徴は、顔によく見られるエッジ、角度、およびその他の特徴を捉えることができます。
トレーニングプロセスでは、アルゴリズムに肯定的な例(顔が含まれる画像)と否定的な例(顔が含まれない画像)を提供します。アルゴリズムは、これらの例を区別するために特徴の重みを調整することで学習します。トレーニング後、Haar Cascadeは、段階的に検出プロセスを洗練させる各ステージからなる分類器の階層となります。
顔検出には、前向きの顔の画像でトレーニングされた事前トレーニング済みのHaar Cascadeモデルを使用しました。
import cv2face_cascade = cv2.CascadeClassifier('./configs/haarcascade_frontalface_default.xml')def haar(image): gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30)) print(len(faces) + "個の顔が検出されました。") for (x, y, w, h) in faces: print(f"ボックス内で顔を検出しました {x} {y} {x+w} {y+h}")MTCNN
MTCNN(Multi-Task Cascaded Convolutional Networks)は、顔検出においてHaar Cascadeの能力を超える洗練された高精度なアルゴリズムです。さまざまな顔のサイズ、向き、照明条件で優れたパフォーマンスを発揮するために設計されたMTCNNは、顔検出プロセス内の特定のタスクを実行するために調整された一連のニューラルネットワークを活用しています。
- フェーズ1 — 提案の生成:MTCNNは、小さなニューラルネットワークを通じて潜在的な顔領域(バウンディングボックス)の複数を生成することで、プロセスを開始します。
- フェーズ2 — 改善:最初のフェーズで生成された候補は、このステップでフィルタリングされます。2つ目のニューラルネットワークは提案されたバウンディングボックスを評価し、真の顔の境界とより正確に一致するように位置を調整します。これにより、精度が向上します。
- フェーズ3 — 顔の特徴点:このステージでは、目の角、鼻、口などの顔の特徴点を特定します。ニューラルネットワークを使用して、これらの特徴点を正確に特定します。
MTCNNのカスケードアーキテクチャにより、顔のない領域をプロセスの初めの段階で迅速に排除し、顔を含む確率が高い領域に計算を集中させることができます。ハールカスケードに比べて、異なるスケール(ズームレベル)の顔や回転を扱う能力が高く、複雑なシナリオに非常に適しています。ただし、ニューラルネットワークベースの逐次的なアプローチにより、計算の負荷が高くなる特性があります。
MTCNNの実装には、mtcnnライブラリを利用しました。
import cv2from mtcnn import MTCNNdetector = MTCNN()def mtcnn_detector(image): faces = detector.detect_faces(image) print(len(faces) + " 個の顔が検出されました。") for face in faces: x, y, w, h = face['box'] print(f"ボックス内で顔が検出されました {x} {y} {x+w} {y+h}")YOLOv5
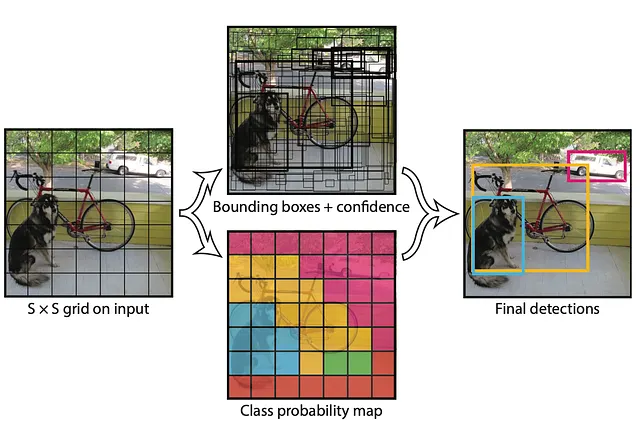
YOLO(You Only Look Once)は、顔を含む多数のオブジェクトを検出するために使用されるアルゴリズムです。従来の手法とは異なり、YOLOはニューラルネットワークを通じて1回の処理で検出を行うため、リアルタイムのアプリケーションや動画に適しています。YOLOを使用したメディアでの顔検出のプロセスは、以下の4つのパートに分解できます:
- 画像グリッドの分割:入力画像はセルのグリッドに分割されます。各セルは、その境界内にあるオブジェクトを予測する責任を持ちます。各セルでは、YOLOはバウンディングボックス、オブジェクトの確率、およびクラスの確率を予測します。
- バウンディングボックスの予測:各セル内で、YOLOは1つ以上のバウンディングボックスとそれに対応する確率を予測します。これらのバウンディングボックスは、潜在的なオブジェクトの位置を表します。各バウンディングボックスは、中心座標、幅、高さ、およびそのバウンディングボックス内にオブジェクトが存在する確率によって定義されます。
- クラスの予測:各バウンディングボックスに対して、YOLOはオブジェクトが属する可能性のあるさまざまなクラス(例:「顔」、「車」、「犬」)の確率を予測します。
- 非最大抑制(NMS):重複するバウンディングボックスを除去するために、YOLOはNMSを適用します。このプロセスでは、確率と他のボックスとの重なりを評価し、最も確信度の高く重ならないボックスのみを保持します。
YOLOの主な利点は、その速度にあります。画像全体をニューラルネットワークを通じて1回のフォワードパスで処理するため、スライディングウィンドウや領域提案を使用するアルゴリズムよりもはるかに高速です。ただし、この速度は、特に小さなオブジェクトや混雑したシーンの場合には、わずかなトレードオフとして精度に影響する可能性があります。
YOLOは、顔専用のデータでトレーニングし、出力クラスを「顔」のみに変更することで、顔検出に適用することができます。これには、YOLOv5をベースにした「yoloface」ライブラリを使用しました。
import cv2from yoloface import face_analysisface=face_analysis()def yolo_face_detection(image): img,box,conf=face.face_detection(image, model='tiny') print(len(box) + " 個の顔が検出されました。") for i in range(len(box)): x, y, h, w = box[i] print(f"ボックス内で顔が検出されました {x} {y} {x+w} {y+h}")顔のぼかし
画像内の潜在的な顔の周りにバウンディングボックスを識別した後、次のステップはそれらの顔をぼかして身元を隠すことです。このタスクには、2つの実装を開発しました。デモンストレーション用の参照画像は図4に示されています。
ガウシアンぼかし

ガウシアンぼかしは、画像ノイズを減らし、細部をぼかすために使用される画像処理技術です。顔のぼかしの領域では特に有用であり、その領域の詳細を消去します。各ピクセルの周囲の近傍のピクセル値の平均を計算します。この平均は、ぼかされるピクセルを中心におり、ガウス分布を使用して算出され、近くのピクセルに重みを大きく、遠いピクセルに重みを小さく与えます。その結果、高周波ノイズと細部が減少した、柔らかい画像が得られます。ガウシアンぼかしの適用結果は図5に示されています。
ガウシアンぼかしには3つのパラメータがあります:
- ぼかしを施す画像部分。
- カーネルサイズ:ぼかし操作に使用される行列。大きなカーネルサイズはより強いぼかしをもたらします。
- 標準偏差:より高い値はぼかし効果を高めます。
f = image[y:y + h, x:x + w]blurred_face = cv2.GaussianBlur(f, (99, 99), 15) # ぼかしパラメータを調整できますimage[y:y + h, x:x + w] = blurred_faceピクセル化

ピクセル化は、画像内のピクセルを単一の色の大きなブロックで置き換える画像処理技術です。この効果は、画像をセルのグリッドに分割し、各セルがピクセルのグループに対応するように行われます。セル内のすべてのピクセルの色または強度を、そのセル内のすべてのピクセルの色の平均値として取り、この平均値をセル内のすべてのピクセルに適用します。このプロセスにより、画像の細部レベルが簡略化され、繊細な詳細が減少します。ピクセル化の適用結果は図6に示されています。観察できるように、ピクセル化は人物の特定を著しく困難にします。
ピクセル化には1つの主要なパラメータがあり、特定の領域を表すためにグループ化されるピクセルの数を決定します。たとえば、顔が含まれるイメージの(10,10)のセクションは、10×10のピクセルグループで置き換えられます。数字が小さいほど、より強いぼかしが生じます。
f = image[y:y + h, x:x + w]f = cv2.resize(f, (10, 10), interpolation=cv2.INTER_NEAREST)image[y:y + h, x:x + w] = cv2.resize(f, (w, h), interpolation=cv2.INTER_NEAREST)結果と議論
私は異なるアルゴリズムを2つの観点から評価します:リアルタイムパフォーマンス分析および特定の画像シナリオ。
リアルタイムパフォーマンス
同じ参考画像(図4)を使用して、各顔検出アルゴリズムが画像内の顔のバウンディングボックスを検出するために必要な時間を測定しました。結果は、各アルゴリズムについて10回の平均値に基づいています。ぼかしアルゴリズムに必要な時間は無視できるため、評価プロセスでは考慮されません。

YOLOv5は、ニューラルネットワークを通過する単一の処理によって最高のパフォーマンス(速度)を実現していることが観察されます。一方、MTCNNのような手法は、複数のニューラルネットワークを順次トラバースする必要があります。これにより、アルゴリズムの並列化のプロセスがさらに複雑になります。
シナリオに基づくパフォーマンス
上記のアルゴリズムのパフォーマンスを評価するために、参照画像(図4)に加えて、さまざまなシナリオでアルゴリズムをテストするためにいくつかの画像を選択しました:
- 参照画像(図4)
- 密集した人々のグループ – 異なる顔のサイズ、近くのものと遠くのものをキャプチャするアルゴリズムの能力を評価するため(図8)
- 横顔 – カメラに直接向かっていない顔を検出するアルゴリズムの能力をテストするため(図10)
- 180度回転した顔 – 180度回転した顔を検出するアルゴリズムの能力をテストするため(図11)
- 90度回転した顔 – 横向きに90度回転した顔を検出するアルゴリズムの能力をテストするため(図12)



Haar Cascade
Haar Cascadeアルゴリズムは、一部の例外を除いて、顔を匿名化するのに一般的に優れたパフォーマンスを発揮します。参照画像(図4)と「複数の顔」シナリオ(図9)を優れた結果で検出します。ただし、「人々のグループ」シナリオ(図8)では、一部の顔が完全に検出されないか、遠くにある顔があります。 Haar Cascadeは、カメラに直接向かっていない顔(図10)や回転した顔(図11および12)といった場面で、顔を完全に認識できないという課題に直面します。

MTCNN
MTCNNはHaar Cascadeと非常に似た結果を実現し、同じ強みと弱点を持っています。さらに、MTCNNは図9の濃い肌のトーンの顔を検出するのに苦労します。

YOLOv5
YOLOv5は、Haar CascadeやMTCNNとは若干異なる結果を提供します。人々がカメラに直接向かっていない場合にも顔を正しく検出します(図10)。また、180度回転した顔も検出します(図11)。しかし、「人の集団」の画像(図8)では、以前のアルゴリズムほど遠くの顔を効果的に検出することはありません。

プライバシー
画像処理におけるプライバシーの課題に対処する際に考慮すべき重要な側面は、顔を識別できないようにする一方で、画像の自然な外観を維持するという微妙なバランスです。
ガウシアンぼかし
ガウシアンぼかしは、画像内の顔領域をぼかします(図5に示されているように)。ただし、その成功はぼかし効果に使用されるガウシアン分布のパラメータに依存します。図5では、顔の特徴が識別可能なままであることが明らかであり、最適な結果を得るにはより高い標準偏差とカーネルサイズが必要であることを示唆しています。
ピクセル化
ピクセル化(図6に示されているように)は、ガウシアンぼかしと比較して、視覚的により魅力的に見えることが多いです。ピクセル化に使用されるピクセル数は、顔の識別性を低下させますが、より自然な外観につながる場合があります。
全体として、ガウシアンぼかしアルゴリズムよりもピクセル化の方が好まれています。これは、その馴染みと文脈における自然さがバランスを取っているためです。
逆エンジニアリング
AIツールの台頭に伴い、ぼかし画像からプライバシーフィルタを除去するための逆エンジニアリング技術の可能性を予測することが重要になってきます。しかし、顔をぼかす行為そのものは、特定の顔の詳細を一般化されたものに置き換えることで、不可逆的に行われます。現時点では、AIツールは同じ人物の明確な参照画像が提示された場合にのみ、ぼかされた顔の逆エンジニアリングが可能です。逆に、これは最初に逆エンジニアリングの必要性を前提としており、個人の身元の知識を前提としています。したがって、進化するAIの能力に対してプライバシーを保護するために、顔のぼかしは効果的かつ必要な手段として存在しています。
動画での使用
動画は基本的には画像の連続ですので、各アルゴリズムを動画用に匿名化することは比較的容易です。ただし、ここでは処理時間が重要になります。1秒あたり60フレーム(画像)で記録された30秒の動画の場合、アルゴリズムは1800フレームを処理する必要があります。このような場合、MTCNNのようなアルゴリズムは実現不可能です。したがって、私はYOLOモデルを使用して動画の匿名化を実装することにしました。
import cv2from yoloface import face_analysisface=face_analysis()def yolo_face_detection_video(video_path, output_path, pixelate): cap = cv2.VideoCapture(video_path) if not cap.isOpened(): raise ValueError("ビデオファイルを開けませんでした") # ビデオのプロパティを取得 fps = int(cap.get(cv2.CAP_PROP_FPS)) frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # コーデックを定義し、出力ビデオのためにVideoWriterオブジェクトを作成 fourcc = cv2.VideoWriter_fourcc(*'H264') out = cv2.VideoWriter(output_path, fourcc, fps, (frame_width, frame_height)) while cap.isOpened(): ret, frame = cap.read() if not ret: break tm = time.time() img, box, conf = face.face_detection(frame_arr=frame, frame_status=True, model='tiny') print(pixelate) for i in range(len(box)): x, y, h, w = box[i] if pixelate: f = img[y:y + h, x:x + w] f = cv2.resize(f, (10, 10), interpolation=cv2.INTER_NEAREST) img[y:y + h, x:x + w] = cv2.resize(f, (w, h), interpolation=cv2.INTER_NEAREST) else: blurred_face = cv2.GaussianBlur(img[y:y + h, x:x + w], (99, 99), 30) # ぼかしのパラメータを調整できます img[y:y + h, x:x + w] = blurred_face print(time.time() - tm) out.write(img) cap.release() out.release() cv2.destroyAllWindows()Webアプリケーション
さまざまなアルゴリズムの簡単な評価のために、ユーザーは任意の画像や動画をアップロードし、顔検出とぼかしのアルゴリズムを選択し、処理後の結果がユーザーに返されるWebアプリケーションを作成しました。この実装は、バックエンドでPythonのFlaskを使用し、前述のライブラリとOpenCVを利用し、フロントエンドではReact.jsを使用してユーザーがモデルとの対話を行うようにしました。完全なコードはこのリンクで入手できます。
結論
この投稿の範囲内で、Haar Cascade、MTCNN、YOLOv5などのさまざまな顔検出アルゴリズムが、異なる側面で調査、比較、分析されました。プロジェクトはまた、画像ぼかし技術に焦点を当てました。
ハールカスケードは、特定のシナリオでは効率的な方法であり、一般的に良好な時間的パフォーマンスを示しました。MTCNNは、さまざまな条件で堅牢な顔検出能力を持つアルゴリズムとして際立っていましたが、従来の向きではない顔には苦労しました。YOLOv5は、リアルタイムの顔検出能力を持ち、時間が重要な要素であるシナリオ(動画など)では優れた選択肢となりましたが、グループ設定ではやや精度が低下します。
すべてのアルゴリズムと技術が1つのWebアプリケーションに統合されました。このアプリケーションでは、顔検出およびぼかしのすべての手法に簡単にアクセスし利用することができ、ぼかし技術を使用して動画を処理することもできます。
この投稿は、スコピエのコンピュータサイエンスおよびエンジニアリング学部の「画像のデジタル処理」コースの私の作業の結論です。読んでいただきありがとうございました!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「言語モデルは放射線科を革新することができるのか?Radiology-Llama2に会ってみてください:指示調整というプロセスを通じて特化した大規模な言語モデル」
- 「InstaFlowをご紹介します:オープンソースのStableDiffusion(SD)から派生した革新的なワンステップ生成型AIモデル」
- マルチAIの協力により、大規模な言語モデルの推論と事実の正確さが向上します
- 自己対戦を通じてエージェントをトレーニングして、三目並べをマスターする
- AI/MLを活用してインテリジェントなサプライチェーンを構築するための始め方
- 「検索強化生成システムのパフォーマンスを向上させるための10の方法」
- 「LLMプロンプティングにおける思考の一端:構造化されたLLM推論の概要」




