マックス・プランク研究所の研究者たちは、MIME(3D人間モーションキャプチャを取得し、その動きに一致する可能性のある3Dシーンを生成する生成AIモデル)を提案しています
Max Planck Institute researchers propose MIME, an AI model that captures 3D human motion and generates 3D scenes that match the captured motion.


人間は常に周囲と相互作用しています。空間を移動したり、物に触れたり、椅子に座ったり、ベッドで寝たりします。これらの相互作用は、シーンの設定やオブジェクトの位置を詳細に示します。マイムは、そのような関係性の理解を利用して、身体の動きだけで豊かで想像力豊かな3D環境を作り出すパフォーマーです。彼らはコンピュータに人間の動作を模倣させて適切な3Dシーンを作ることができるでしょうか?建築、ゲーム、バーチャルリアリティ、合成データの合成など、多くの分野がこの技術に恩恵を受ける可能性があります。たとえば、AMASSなどの3D人間の動きの大規模なデータセットが存在しますが、これらのデータセットには収集された3D設定の詳細がほとんど含まれていません。
AMASSを使用して、すべての動きに対して信憑性の高い3Dシーンを作成できるでしょうか?そうであれば、AMASSを使用してリアルな人間-シーンの相互作用を考慮したトレーニングデータを作成できます。彼らは、MIME(Mining Interaction and Movement to infer 3D Environments)と呼ばれる新しい技術を開発しました。これは、3D人間の動きに基づいて信憑性の高い内部3Dシーンを作成して、このような問いに対応します。それを可能にするのは何でしょうか?基本的な仮定は次のとおりです。(1)空間を移動する人間の動きは、物の欠如を示し、実質的に家具のない画像領域を定義します。また、これにより、シーンに接触する場合の3Dオブジェクトの種類や場所が制限されます。たとえば、座っている人は椅子、ソファ、ベッドなどに座っている必要があります。
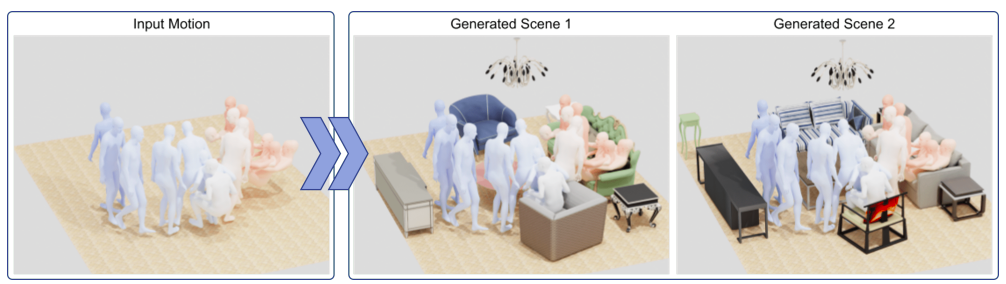
ドイツのマックスプランク知能システム研究所とAdobeの研究者たちは、これらの直感を具体的な形で示すために、MIMEと呼ばれるトランスフォーマーベースの自己回帰3Dシーン生成技術を作成しました。空のフロアプランと人間の動きシーケンスが与えられると、MIMEは人間と接触する家具を予測します。さらに、人間と接触しないが他のオブジェクトにフィットし、人間の動作によって引き起こされる自由空間の制約に従う信憑性の高いアイテムを予測します。彼らは、人間の動きを接触と非接触のスニペットに分割して、3Dシーン作成を人間の動きに条件付けます。POSAを使用して接触可能なポーズを推定します。非接触姿勢は、足の頂点を地面に投影して、部屋の自由空間を確立し、2Dフロアマップとして記録します。
- UCサンディエゴとクアルコムの研究者たちは「Natural Program」を公開しましたそれは自然言語での厳密な推論チェーンの容易な検証にとって強力なツールであり、AIにおける大きな転換点となります
- 中国の研究者グループが開発したWebGLM:汎用言語モデル(GLM)に基づくWeb強化型質問応答システム
- SalesForceのAI研究者が、マスク不要のOVISを紹介:オープンボキャブラリーインスタンスセグメンテーションマスクジェネレータ
POSAによって予測された接触頂点は、接触ポーズと関連する3D人体モデルを反映した3D境界ボックスを作成します。接触と自由空間の基準を満たすオブジェクトは、トランスフォーマーへの入力として自己回帰的に期待されます。図1を参照してください。彼らは、3D-FRONTという大規模な合成シーンデータセットを拡張して、MIMEをトレーニングするための新しいデータセットである3D-FRONT HUMANを作成しました。彼らは、RenderPeopleスキャンからの静止接触ポーズと、AMASSからのモーションシーケンスを使用して、3Dシナリオに人を自動的に追加します(一連の歩行モーションと立っている人を含む非接触人と、座って、触れて、横たわっている人を含む接触人)。
MIMEは、3Dバウンディングボックスとして表される入力動作のリアルな3Dシーンレイアウトを推論時に作成します。彼らは、この配置に基づいて3D-FUTUREコレクションから3Dモデルを選択し、人間の位置とシーンの間の幾何学的制約に基づいて3D配置を微調整します。彼らの手法は、ATISSのような純粋な3Dシーン作成システムとは異なり、人間の接触と動きをサポートする3Dセットを作成し、自由空間に説得力のあるオブジェクトを配置することができます。Pose2Roomという最近のポーズ条件付け生成モデルとは異なり、個々のオブジェクトではなく完全なシーンを予測することができます。彼らは、PROX-Dのように記録された本物のモーションシーケンスに対して調整なしで彼らの手法が機能することを示しました。
まとめると、彼らが提供したものは以下の通りです:
• 人と接触するものを自動的に生成し、運動定義された空きスペースを占有しないように自己回帰的に作成する、3Dルームシーンの全く新しい運動条件付き生成モデル。
• RenderPeopleの静止接触/立ち姿勢からの3Dモーションデータを用いて、人と自由空間にいる人々が相互作用する3Dシーンデータセットが、3D FRONTを埋めるように作成されました。
コードはGitHubで入手可能であり、ビデオデモとアプローチのビデオ解説も提供されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






