ストラテゴをマスターする:情報の不完全なクラシックゲーム
Mastering Stratego The Incomplete Classic Game
DeepNashがゲーム理論とモデルフリーの深層強化学習を組み合わせて、ゼロからストラテジーゲームをプレイする方法を学びました
ゲームプレイの人工知能(AI)システムは新たな領域に進化しています。チェスや囲碁よりも複雑で、ポーカーよりも巧妙なクラシックボードゲームであるストラテジーは、ついにマスターされました。Scienceに掲載された論文では、DeepNashというAIエージェントが自己対戦により、人間のエキスパートレベルまでゲームを学習したことを紹介しています。
DeepNashは、ゲーム理論とモデルフリーの深層強化学習に基づいた革新的な手法を使用しています。そのプレースタイルはナッシュ均衡に収束するため、相手に対して非常に難しいプレイスタイルとなります。実際に、DeepNashは世界最大のオンラインストラテジープラットフォームであるGravonで、人間のエキスパートの中でもトップ3のランキングを達成しました。
ボードゲームは、AIの分野での進歩の指標となってきました。制御された環境で人間と機械が戦略を開発し実行する方法を研究することができます。チェスや囲碁とは異なり、ストラテジーは情報の不完全なゲームです。プレイヤーは相手の駒の正体を直接観察することはできません。
この複雑さのため、他のAIベースのストラテジーシステムはアマチュアレベルを超えることができませんでした。また、ストラテジーでは従来の「ゲーム木探索」という非常に成功したAI手法は、十分にスケーラブルではありません。そのため、DeepNashは従来のゲーム木探索をはるかに超えています。
ストラテジーをマスターする価値は、ゲーム以上のものです。知識の不完全な他のエージェントや人々との複雑な現実世界の状況で操作できる高度なAIシステムを構築する必要があります。DeepNashが不確実性のある状況で適用でき、複雑な問題の解決に成功したことを示す論文です。
ストラテジーの理解
ストラテジーは、ターン制のフラッグ奪取ゲームです。ブラフや戦術、情報収集や微妙な操縦が求められます。そして、ゼロサムゲームなので、一方のプレイヤーの利益は相手の同じだけの損失を意味します。
ストラテジーは、情報の不完全なゲームであるため、AIにとっては挑戦的な要素があります。両プレイヤーは最初に40個の駒を任意の配置で配置し、ゲームが始まるとお互いに隠されます。両プレイヤーが同じ知識にアクセスできないため、意思決定をする際にはすべての可能な結果をバランスさせる必要があります。これは戦略的な相互作用を研究するための挑戦的なベンチマークを提供します。駒の種類とそのランキングは以下の通りです。

ストラテジーでは情報は容易に得られません。相手の駒の正体は、通常、戦場で他のプレイヤーと接触したときに初めて明らかにされます。これは、チェスや囲碁のような完全情報ゲームとは対照的であり、両プレイヤーには各駒の場所や正体が知られているからです。
DeepMindのAlphaZeroなど、完全情報ゲームでうまく機能する機械学習手法は、ストラテジーには容易に転用できません。不完全な情報を持って意思決定をする必要があり、ブラフの可能性があるため、ストラテジーはテキサスホールデムポーカーに似ており、アメリカの作家ジャック・ロンドンがかつて指摘したように、人間らしい能力が求められます。「人生は常に良いカードを持つことではなく、時には悪い手をうまくプレイすることもある」ということです。
AIテクニックはテキサスホールデムなどのゲームで非常にうまく機能しますが、Strategoには適用することができません。なぜなら、ゲームが非常に長いためです。プレーヤーが勝利するまでには何百もの手がかかることがよくあります。Strategoでは、各アクションが最終的な結果にどのように寄与するかについての明確な洞察がないため、推論を行う必要があります。
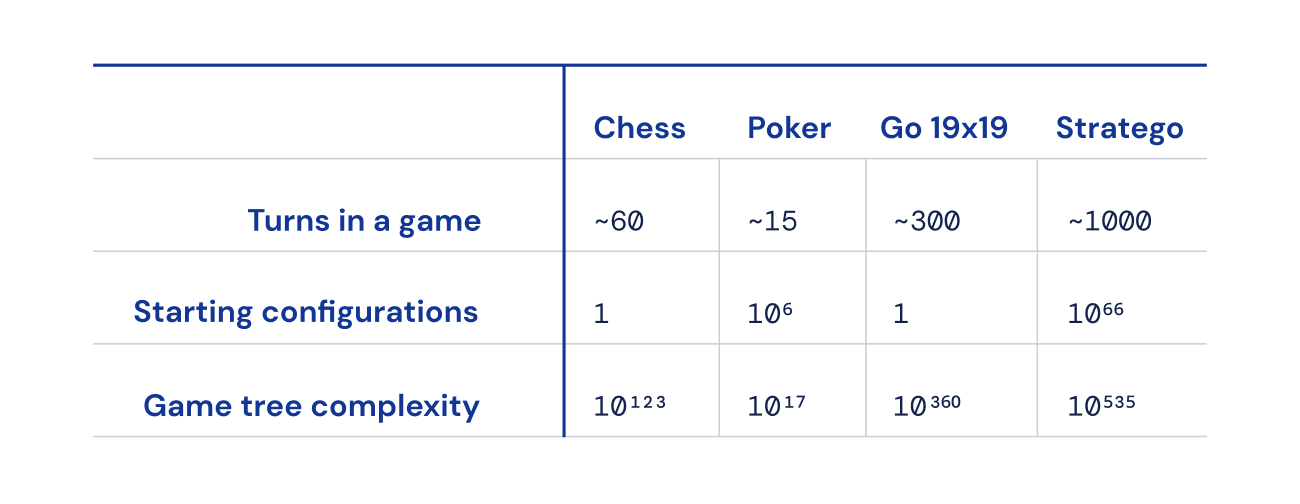
さらに、チェス、囲碁、ポーカーと比較して、可能なゲーム状態の数(「ゲームツリーの複雑さ」として表される)が桁外れに多く、解決するのが非常に困難です。これが私たちがStrategoに興奮し、それがAIコミュニティにとって数十年にわたる課題となっている理由です。
平衡を求める
DeepNashは、ゲーム理論とモデルフリーのディープ強化学習を組み合わせた画期的なアプローチを採用しています。「モデルフリー」とは、DeepNashがゲーム中に相手のプライベートなゲーム状態を明示的にモデル化しようとしていないことを意味します。特にゲームの初期段階では、DeepNashは相手の駒についてほとんど知識がないため、そのようなモデリングは効果的ではないかもしれませんし、不可能かもしれません。
また、Strategoのゲームツリーの複雑さが非常に巨大であるため、DeepNashはAIベースのゲームであるモンテカルロ木探索の堅実なアプローチを採用することはできません。ツリー探索は、より複雑でないボードゲームやポーカーでの多くの画期的な成果の重要な要素となっています。
その代わり、DeepNashは、私たちが「正則化されたナッシュダイナミクス(R-NaD)」と呼んでいる、新しいゲーム理論的なアルゴリズムのアイデアに基づいて動作しています。R-NaDは、DeepNashの学習行動をナッシュ均衡として知られるものに向かわせることで、前例のないスケールで動作します(詳細は当社の論文をご覧ください)。
ナッシュ均衡に結果が導かれるゲームプレイの行動は、時間の経過とともに利用されないものです。人間や機械が完璧に利用されないStrategoをプレイした場合、最低の勝率は50%になりますが、それも同様に完璧な相手と対戦した場合だけです。
コンピュータStrategoワールドチャンピオンなどの最高のStrategoボットとの対戦では、DeepNashの勝率は97%を超え、しばしば100%でした。Gravonゲームプラットフォームのトップのエキスパートプレーヤーとの対戦では、DeepNashは84%の勝率を達成し、歴代トップ3のランキングを獲得しました。
予期せぬことが起こる
これらの結果を実現するために、DeepNashは初期の配置フェーズとゲームプレイフェーズの両方で驚くべき振る舞いを示しました。利用されにくくなるために、DeepNashは予測できない戦略を展開しました。これは、ゲームのシリーズ中に相手がパターンを見つけるのを防ぐために、初期の配置を十分に変化させることを意味します。そして、ゲームのフェーズ中には、DeepNashは見かけ上同等のアクションの間でランダムに変動し、利用可能な傾向を防ぎます。
Strategoプレーヤーは予測できないようにすることを目指しており、情報を隠すことに価値があります。DeepNashは、情報を非常に効果的に評価する方法を示しています。以下の例では、人間のプレーヤーに対して、DeepNash(青)はゲームの早い段階で7(メジャー)と8(大佐)を含む駒を犠牲にし、その結果、相手の10(元帥)、9(将軍)、8と2つの7を特定することができました。
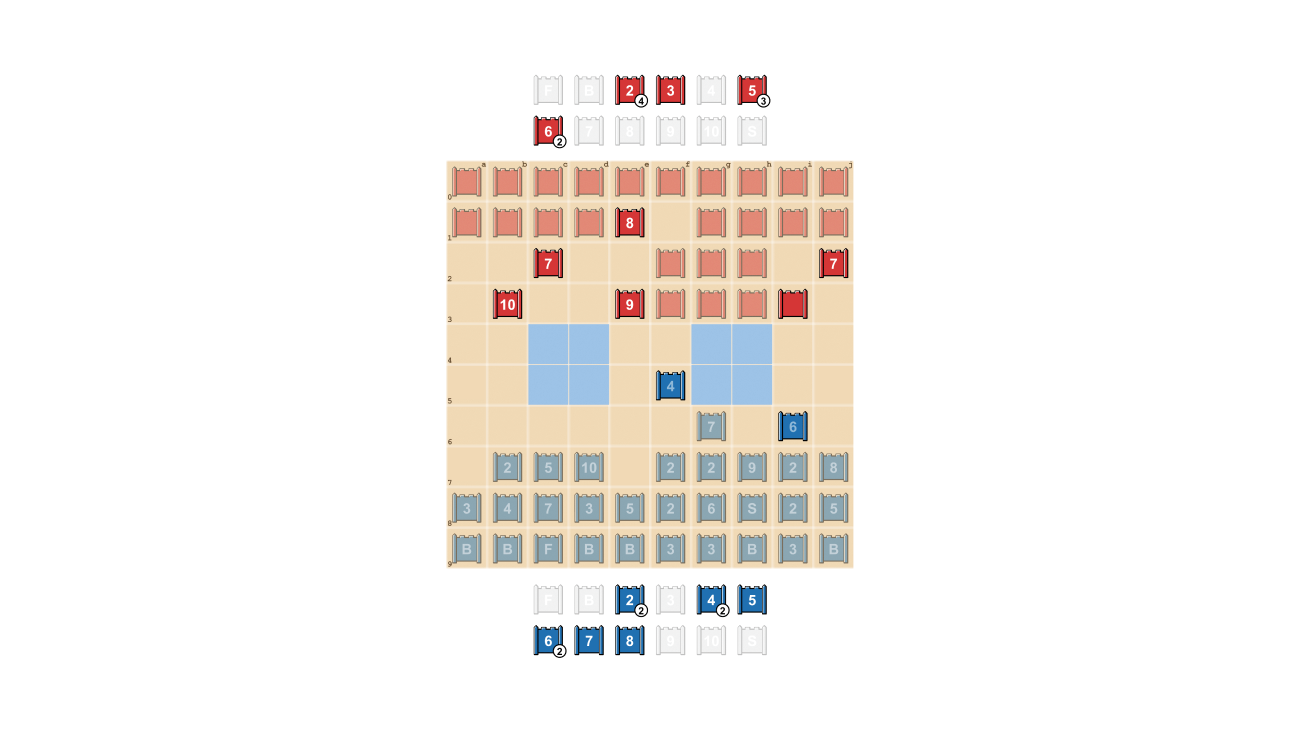
これらの取り組みにより、DeepNashは重要な物質的不利に立たされました。対戦相手はランク7以上のすべての駒を残し、DeepNashは7と8を失いました。それにもかかわらず、DeepNashは相手のトップランクの情報を手に入れたことにより、勝利の可能性を70%と評価し、勝利しました。
ブラフの技術
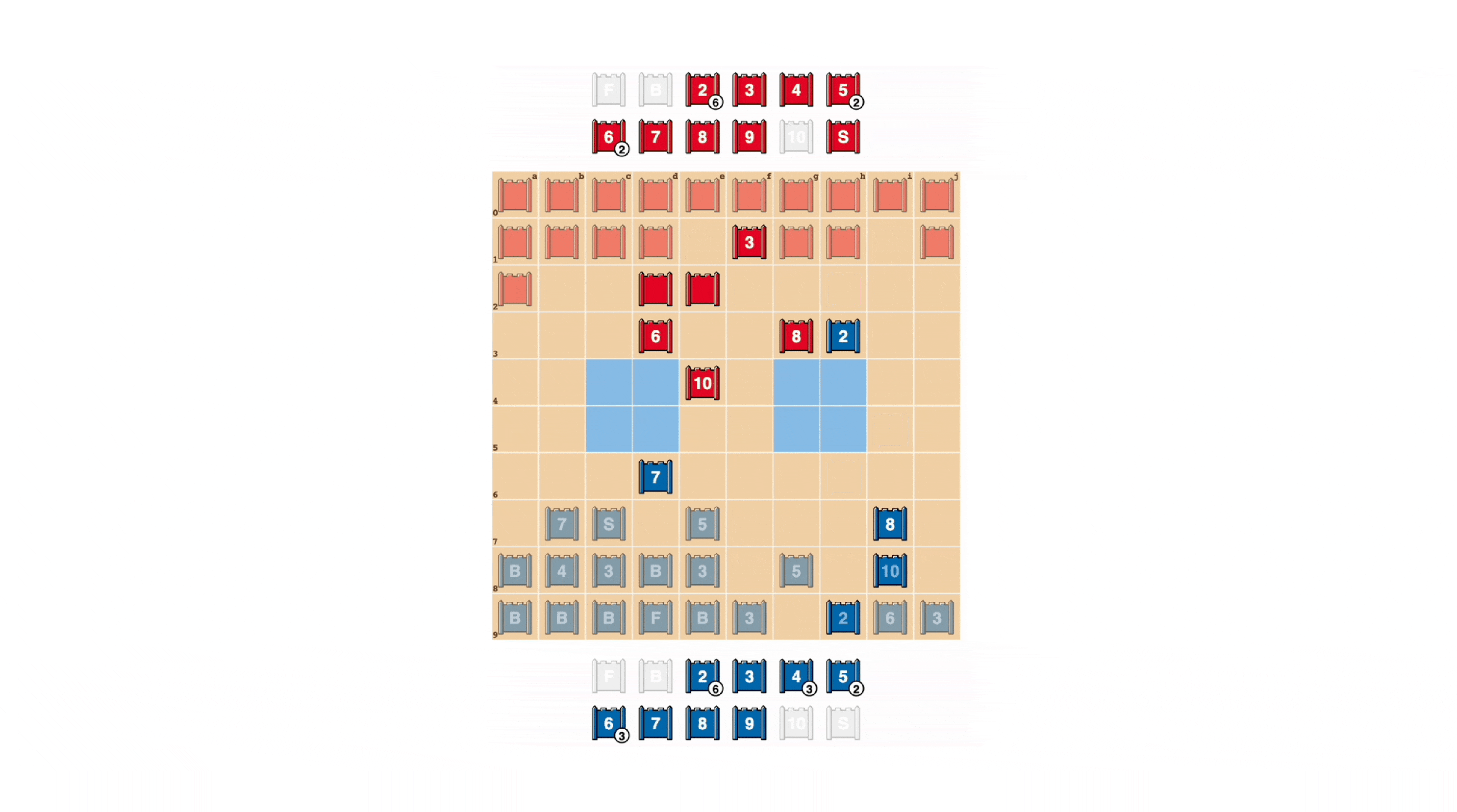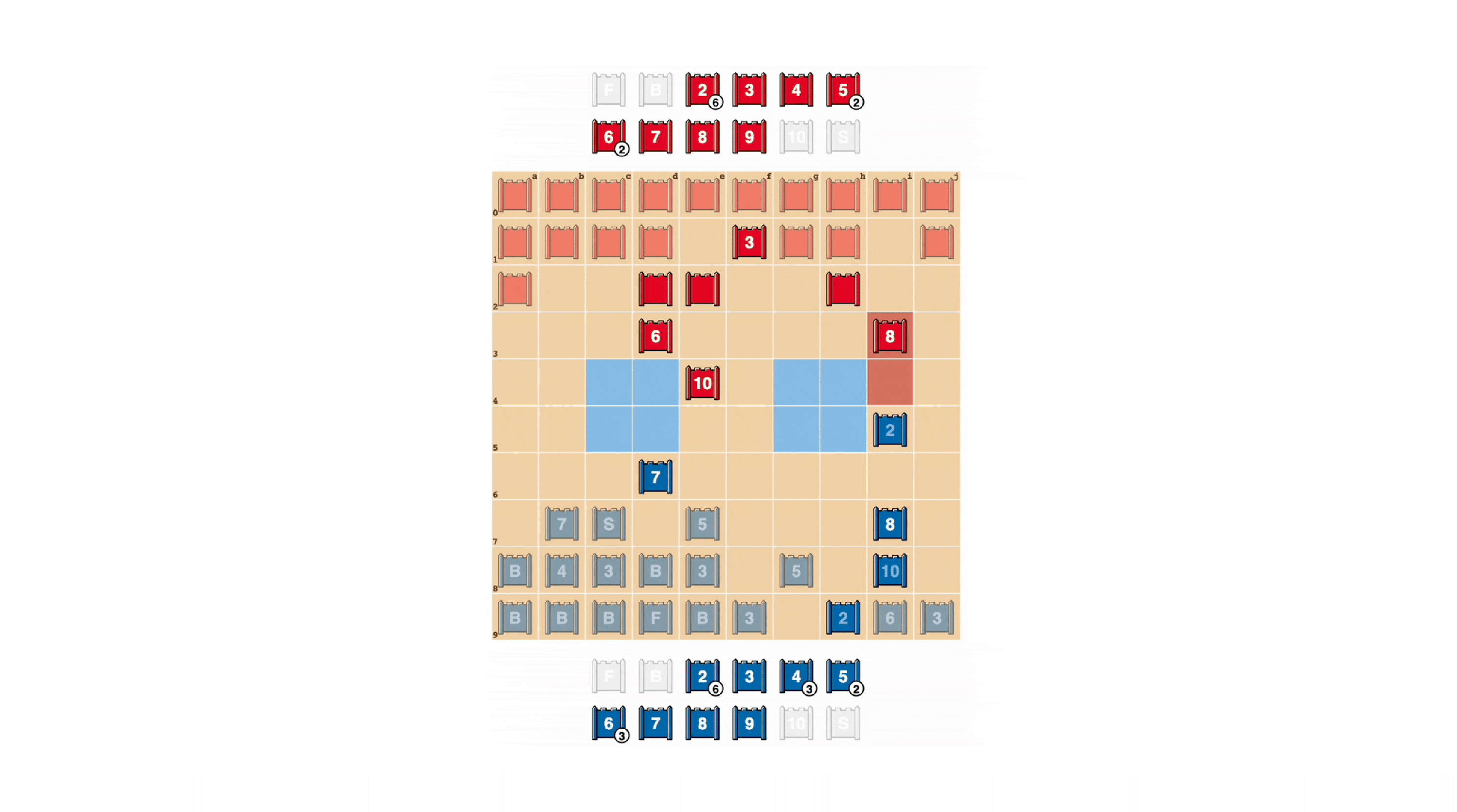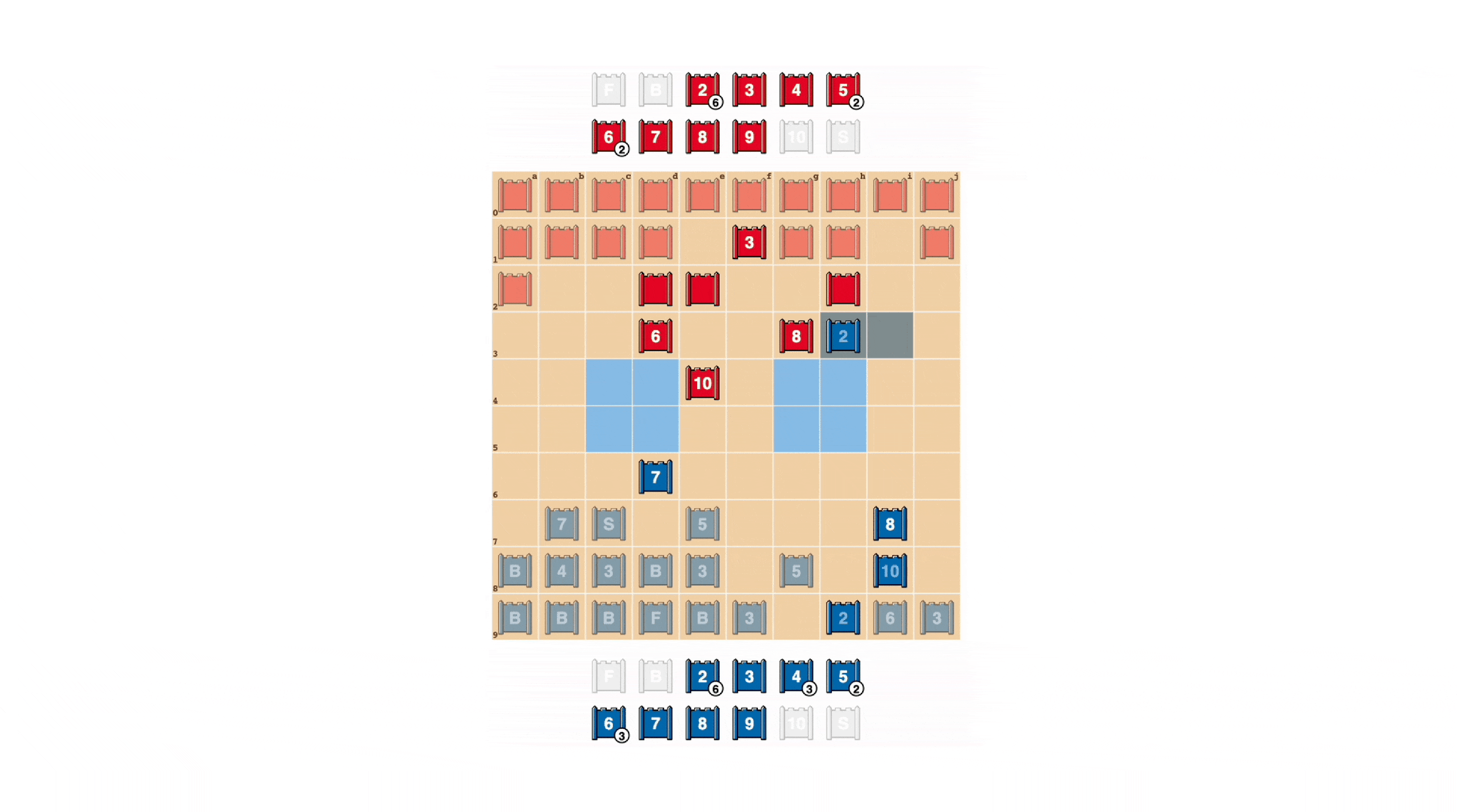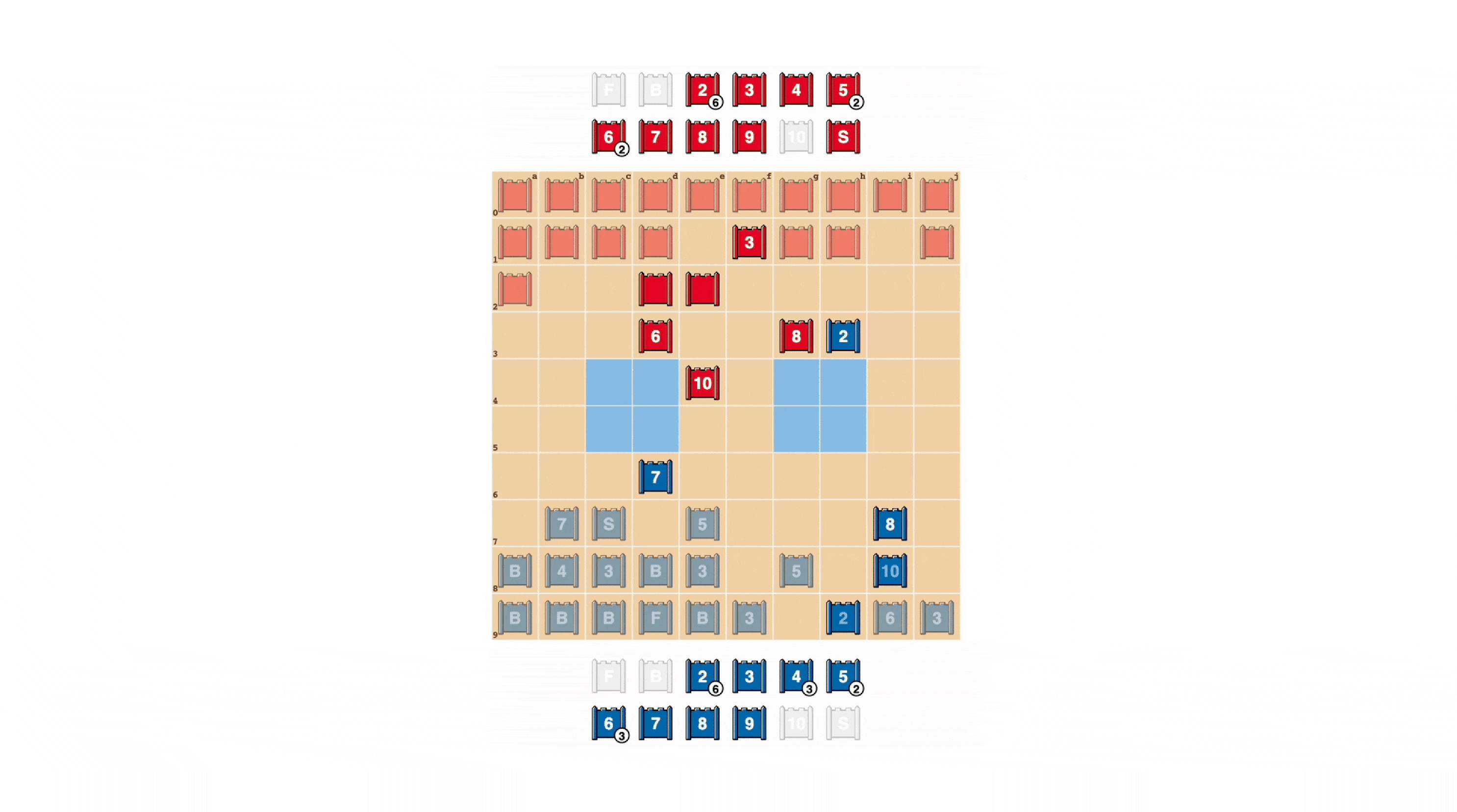
ポーカーと同様に、優れたStrategoプレーヤーは時には弱いときでも強さを装う必要があります。DeepNashはさまざまなブラフの戦術を学びました。以下の例では、DeepNashは相手には知られていない弱いスカウトである2を、高いランクの駒であるかのように使い、相手の知られた8を追います。人間の対戦相手は、追ってくるものがおそらく10であると考え、スパイによる待ち伏せに誘います。このDeepNashの戦術は、わずかな駒をリスクにさらすことで、対戦相手のスパイ、重要な駒を排除することに成功しました。
DeepNashが(匿名化された)人間のエキスパートと対戦した完全なゲームの4つのビデオを見ることで、さらに詳しくご覧ください:Game 1 , Game 2 , Game 3 , Game 4。
“DeepNashのプレイのレベルは私を驚かせました。経験豊富な人間のプレーヤーに対して試合に勝つために必要なレベルに近い人工のStrategoプレーヤーについて聞いたことがありませんでした。しかし、DeepNashと対戦してみた後、Gravonプラットフォームで後に達成したトップ3のランキングには驚きませんでした。人間のワールドチャンピオンシップに参加することが許されれば、非常にうまくいくと思います。” – Vincent de Boer、論文共著者および元Strategoワールドチャンピオン
将来の展望
Strategoのような厳密に定義された世界のためにDeepNashを開発しましたが、私たちの新しいR-NaDメソッドは、完全または不完全な情報を持つ他の二人対戦の零和ゲームに直接適用することができます。R-NaDは、不完全な情報と膨大な状態空間によって特徴付けられる大規模な現実世界の問題に対しても、一般化の可能性を秘めています。
また、R-NaDが、他の人間やAI参加者がお互いの意図や環境で何が起こっているかを把握していない、ドライバーの所要時間と関連する車両の排出物を削減するための交通管理の大規模最適化など、情報の多い領域でAIの新しい応用を開拓するのに役立つことを期待しています。
私たちは、不確実性に対して頑健な一般化可能なAIシステムを作成することで、AIの問題解決能力を私たちの不確実な世界にさらに向けることを望んでいます。
私たちの論文を読んでDeepNashについてもっと詳しく知ることができます。
R-NaDを試してみたり、私たちの新しく提案されたメソッドで作業することに興味のある研究者には、私たちのコードをオープンソースにしました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- あなたのオープンソースのLLMプロジェクトはどれくらいリスクがあるのでしょうか?新たな研究がオープンソースのLLMに関連するリスク要因を説明しています
- このAI研究は、大規模言語モデル(LLM)における合成的な人格特性を説明しています
- HuggingFace Researchが紹介するLEDITS:DDPM Inversionと強化された意味的なガイダンスを活用したリアルイメージ編集の次なる進化
- MITの科学者たちは、生物学の研究のためのAIモデルを生成できるシステムを構築しました
- Covid-19への闘いを加速する:研究者がAIによって生成された抗ウイルス薬を検証し、将来の危機における迅速な薬剤開発の道を開拓
- 新しいGoogle AI研究では、ペアワイズランキングプロンプティング(PRP)という新しい技術を使用して、LLMの負担を大幅に軽減することを提案しています
- トロント大学の研究者たちは、3300万以上の細胞リポジトリ上で生成事前学習トランスフォーマーに基づいたシングルセル生物学のための基礎モデルであるscGPTを紹介しました