モデルの解釈のマスタリング:パーシャル依存プロットの包括的な解説
Mastering Model Interpretation Comprehensive Explanation of Partial Dependency Plots
解釈可能なAIの世界での旅の開始。
モデルの解釈方法を知ることは、それが奇妙なことをしていないかを理解するために重要です。モデルをよりよく知っていれば、プロダクション時の振る舞いに驚かされる可能性は低くなります。
また、モデルに対するドメイン知識が豊富であれば、ビジネスユニットに対してより良いセールスができるでしょう。最悪の事態は、実際に自分が何を売っているのかわからないことに気付かれることです。
私は、入力変数から予測がどのように行われたかを説明する必要がないモデルを開発したことはありません。少なくとも、ビジネスに対してどの特徴が肯定的または否定的に寄与したのかを明示することが不可欠でした。
モデルの動作を理解するためのツールの1つは、Partial Dependence Plot(PDP)です。この記事で探求していきます。
- People Analyticsは新しい大きなトレンドであり、それを知っておくべき理由があります
- 学習トランスフォーマーコード入門:パート1 – セットアップ
- 細かいところに悪魔が潜んでいる:ボックスから飛び出してPower BIのチャンピオンになろう
PDPとは何ですか
PDPは、モデルの特徴量の値がモデルの出力とどのように関連しているかを示すためのグローバルな解釈手法です。
これはデータを理解するための方法ではなく、モデルに関する洞察を生成するものであり、この方法からは目的変数と特徴量の因果関係を推論することはできません。ただし、モデルに関する因果関係についての推論を行うことは可能です。
これは、この方法によってモデルを調査するため、特徴量の変化に伴ってモデルがどのような振る舞いをするかを正確に見ることができるためです。
動作原理
まず、PDPでは1つまたは2つの特徴量のみを調査することができます。この記事では、単一特徴量の分析に焦点を当てます。
モデルが訓練された後、プロービングデータセットを生成します。このデータセットは以下のアルゴリズムに従って作成されます:
- 興味のある特徴量の各ユニークな値を選択します
- 各ユニークな値について、特徴量の値をそのユニークな値に設定したデータセット全体のコピーを作成します
- 次に、この新しいデータセットを使用してモデルで予測を行います
- 最後に、各ユニークな値のモデルの予測を平均します
例を挙げましょう。以下のデータセットがあるとします:

次に、Feature 0にPDPを適用する場合、特徴量の各ユニークな値ごとにデータセットを繰り返します:

その後、モデルを適用すると以下のようになります:

そして、各値の平均出力を計算し、以下のようなデータセットが得られます:

あとは、このデータをラインプロットでプロットするだけです。
回帰問題の場合、各特徴量値の平均出力を計算することは簡単です。分類問題では、各クラスの予測確率を使用して値を平均化します。この場合、データセット内の各特徴量とクラスのペアに対してPDPが得られます。
数学的な解釈
PDPの解釈は、モデルの予測出力に対する特徴量の周辺効果を評価するために1つまたは2つの特徴量を周辺化しているというものです。これは以下の式で表されます:

ここで、$f$は機械学習モデル、$x_S$は分析したい特徴のセット、$x_C$は平均化する他の特徴のセットです。上記の関数は以下の近似を用いて計算できます:
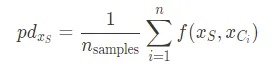
PDPの問題点
PDPにはいくつかの制限があります。まず、各特徴の値ごとに出力を平均化するため、データセットのすべての値に対してプロットが表示されます。その値が一度しか出現しない場合でもです。
そのため、データセットのごく一部の領域で特定の動作が表示されることがありますが、その値がより頻繁に出現する場合に起こる可能性がある動作を代表しているわけではありません。したがって、PDPを表示する際には、特徴の分布を常に確認することが役立ちます。
もう一つの問題は、値が互いに打ち消し合う特徴を持つ場合に発生します。たとえば、特徴が次のような分布を持つ場合:

この特徴のPDPを計算すると、次のような結果になります:

特徴の影響はゼロではないことに注意してくださいが、平均ではゼロです。これにより、特徴が無効であると誤解する可能性がありますが、実際にはそうではありません。
このアプローチのもう一つの問題は、分析している特徴が平均化する特徴と相関している場合です。これは、相関する特徴がある場合、データセットの各値に対して興味のある特徴の各値を強制することになるため、現実にはあり得ない点が作成されるためです。
雨の量と空の雲の量のデータセットを考えてみてください。雨の量の値を平均化すると、空に雲がない状態で雨が降ったという点が作成されることになりますが、これは現実にはあり得ない点です。
PDPの解釈
PDPの解釈方法を見てみましょう。以下の画像をご覧ください:

x軸には特徴0の値、y軸には各特徴値に対するモデルの平均出力があります。-0.10未満の値では、モデルの予測値は非常に低くなり、その後予測値が上昇し、特徴値が0.09を超えると予測値が急激に上昇します。
したがって、特徴とターゲット予測の間には正の相関関係があると言えますが、この相関関係は線形ではありません。
ICEプロット
ICEプロットは、特徴の値が互いに打ち消し合う問題を解決しようとします。基本的に、ICEプロットでは、各値に対してモデルが行った個々の予測をプロットします。
PythonでのPDPの実装
PythonでPDPを実装しましょう。そのために、必要なライブラリを最初にインポートします:
import numpy as npimport matplotlib.pyplot as pltfrom tqdm import tqdmfrom sklearn.datasets import load_diabetesfrom sklearn.ensemble import RandomForestRegressorsklearnからdiabetesデータセットを使用します。ループの進捗状況を表示するためにtqdmライブラリを使用します。
次に、データセットを読み込み、Random Forest Regressorに適合させます:
X, y = load_diabetes(return_X_y=True)rf = RandomForestRegressor().fit(X, y)次に、データセットの各特徴について、その特徴を固定した場合のモデルの平均予測値を計算します:
features = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
features_averages = {}
for feature in tqdm(features):
features_averages[feature] = ([], [])
# 各特徴量のユニークな値ごとに
for feature_val in np.unique(X[:, feature]):
features_averages[feature][0].append(feature_val)
# データセットから特徴量を削除する
aux_X = np.delete(X, feature, axis=1)
# データセットの各行に特徴量の値を追加する
aux_X = np.hstack((aux_X, np.array([feature_val for i in range(aux_X.shape[0])])[:, None]))
# 平均予測値を計算する
features_averages[feature][1].append(np.mean(rf.predict(aux_X)))
次に、各特徴量のPDPをプロットします:
for feature in features_averages:
plt.figure(figsize=(5,5))
values = features_averages[feature][0]
predictions = features_averages[feature][1]
plt.plot(values, predictions)
plt.xlabel(f'特徴量: {feature}')
plt.ylabel('目標変数')
例えば、Feature 3のプロットは以下の通りです:

結論
これで、黒箱モデルをビジネス部門に理解させるために、ツールボックスにもうひとつのツールが追加されました。
しかし、理論を忘れてしまわないようにしましょう。現在開発中のモデルを取り上げ、PDPの可視化を適用してみてください。モデルが何をしているのかを理解し、仮説をより正確に立てることができます。
また、これは唯一の解釈可能性の手法ではありません。実際に、相関する特徴量に対してより優れた結果を得る他の手法もあります。次の投稿では、これらの手法について詳しく説明します。
参考文献
https://ethen8181.github.io/machine-learning/model_selection/partial_dependence/partial_dependence.html
https://scikit-learn.org/stable/modules/partial_dependence.html
https://christophm.github.io/interpretable-ml-book/pdp.html
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
