マスク2フォーマーとワンフォーマーによるユニバーサル画像セグメンテーション
'Mask-2Former and One-Former for Universal Image Segmentation'
このガイドでは、画像セグメンテーションのための最先端のニューラルネットワークであるMask2FormerとOneFormerを紹介します。これらのモデルは、最先端モデルの簡単な実装を提供するオープンソースのライブラリである🤗 transformersで利用できます。途中で、さまざまな形式の画像セグメンテーションの違いについて学びます。
画像セグメンテーション
画像セグメンテーションは、人や車などの画像内の異なる「セグメント」を識別するタスクです。より具体的には、画像セグメンテーションは異なる意味を持つピクセルをグループ化するタスクです。詳細については、Hugging Faceのタスクページを参照してください。
画像セグメンテーションは、主に3つのサブタスクに分割できます。それぞれのサブタスクを実行するための多数の方法とモデルアーキテクチャがあります。
- インスタンスセグメンテーションは、画像内の個々の人物などの異なる「インスタンス」を識別するタスクです。インスタンスセグメンテーションは、オブジェクト検出と非常に似ていますが、境界ボックスではなく、対応するクラスラベルとともに一連のバイナリセグメンテーションマスクを出力したいという点が異なります。インスタンスはしばしば「オブジェクト」や「事物」とも呼ばれます。ただし、個々のインスタンスは重なる場合があります。
- 意味セグメンテーションは、画像の各ピクセルの「人」や「空」などの異なる「意味カテゴリ」を識別するタスクです。インスタンスセグメンテーションとは異なり、与えられた意味カテゴリの個々のインスタンスの区別はありません。たとえば、「人」のカテゴリのマスクを作成するだけであり、個々の人物のマスクを作成するわけではありません。対象カテゴリに個別のインスタンスがない「空」や「草」などの意味カテゴリは、しばしば「物」と呼ばれます(素晴らしい名前ですね)。ピクセルごとのカテゴリには重なりがないことに注意してください。
- パノプティックセグメンテーションは、Kirillov et al.によって2018年に導入され、モデルが対応するバイナリマスクとクラスラベルのセットを単に識別することで、インスタンスセグメンテーションと意味セグメンテーションを統一することを目指しています。セグメントは「物」または「物」のどちらでもなります。インスタンスセグメンテーションとは異なり、異なるセグメント間の重なりはありません。
以下の図は、3つのサブタスクの違いを示しています(このブログ投稿から取得)。
- 3Dアセット生成:ゲーム開発のためのAI#3
- Optimum+ONNX Runtime – Hugging Faceモデルのより簡単で高速なトレーニング
- どのような要素が対話エージェントを有用にするのか?

ここ数年、研究者たちは通常、インスタンスセグメンテーション、意味セグメンテーション、パノプティックセグメンテーションのいずれかに特化したいくつかのアーキテクチャを提案してきました。インスタンスセグメンテーションとパノプティックセグメンテーションは、通常、オブジェクトインスタンスごとにバイナリマスクと対応するラベルのセットを出力することによって解決されました(インスタンス検出と非常に似ていますが、インスタンスごとに境界ボックスの代わりにバイナリマスクを出力します)。これは通常「バイナリマスク分類」と呼ばれます。一方、意味セグメンテーションは、モデルがピクセルごとに1つの「セグメンテーションマップ」を出力することで解決されることが一般的でした。したがって、意味セグメンテーションは「ピクセルごとの分類」の問題として扱われました。このパラダイムを採用する人気のある意味セグメンテーションモデルには、SegFormer(詳細なブログ投稿を書いた)とUPerNetなどがあります。
ユニバーサル画像セグメンテーション
幸いなことに、2020年ごろから、インスタンスセグメンテーション、意味セグメンテーション、およびパノプティックセグメンテーションのすべてのタスクを統一されたアーキテクチャで解決できるモデルが登場し始めました。これは最初にDETRが行ったものであり、”物”クラスと”物”クラスを統一的な方法で扱うことによってパノプティックセグメンテーションを解決した最初のモデルでした。キーイノベーションは、トランスフォーマーデコーダが並列的に一連のバイナリマスクとクラスを生成することでした。これはMaskFormerの論文で改善され、”バイナリマスク分類”のパラダイムが意味セグメンテーションにも非常にうまく適用されることが示されました。
Mask2Formerは、ニューラルネットワークアーキテクチャをさらに改善することで、インスタンスセグメンテーションにも拡張します。したがって、個別のアーキテクチャから、研究者たちが現在「ユニバーサル画像セグメンテーション」と呼んでいる、すべての画像セグメンテーションタスクを解決できるアーキテクチャに進化しました。興味深いことに、これらのユニバーサルモデルはすべて「マスク分類」のパラダイムを採用しており、完全に「ピクセルごとの分類」のパラダイムを廃止しています。Mask2Formerのアーキテクチャを示す図は、以下に示されています(オリジナルの論文から取得)。
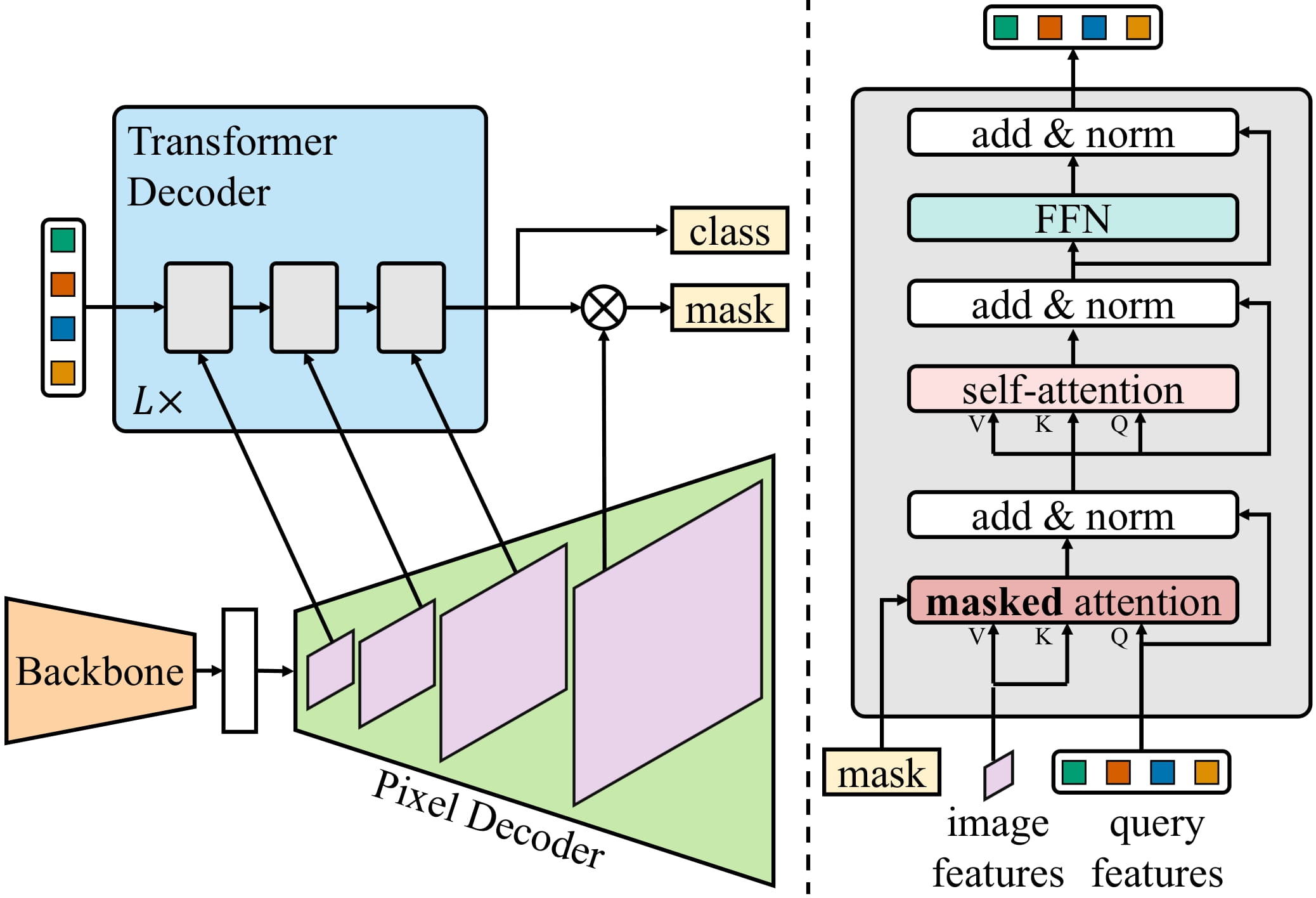
要するに、画像はまずバックボーン(この論文ではResNetまたはSwin Transformerのどちらか)に送信されて、低解像度の特徴マップのリストを取得します。次に、これらの特徴マップは、ピクセルデコーダモジュールを使用して高解像度の特徴に改善されます。最後に、トランスフォーマーデコーダは一連のクエリを受け取り、ピクセルデコーダの特徴に基づいて一連のバイナリマスクとクラスの予測を行います。
Mask2Formerは、最先端の結果を得るために、各タスクごとにトレーニングする必要があることに注意してください。これは、OneFormerモデルによって改善されました。OneFormerモデルは、データセットのパノプティックバージョンのみをトレーニングすることで、すべての3つのタスクで最先端のパフォーマンスを実現します。さらに、テキストエンコーダを追加してモデルを「インスタンス」、「セマンティック」、または「パノプティック」の入力に条件付けることで、これをさらに改善しました。このモデルは、今日でも🤗 transformersで利用できます。Mask2Formerよりも精度が高くなっていますが、追加のテキストエンコーダにより遅延が大きくなります。OneFormerの概要については、以下の図を参照してください。Swin Transformerまたは新しいDiNATモデルをバックボーンとして使用しています。

TransformersでのMask2FormerとOneFormerの推論
Mask2FormerとOneFormerの使用法は非常に簡単であり、前身であるMaskFormerと非常に似ています。COCOパノプティックデータセットでトレーニングされたハブからMask2Formerモデルをインスタンス化し、それに対応するプロセッサもインスタンス化します。作者たちはさまざまなデータセットでトレーニングされた30個以上のチェックポイントをリリースしていることに注意してください。
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")次に、COCOデータセットからおなじみの猫の画像をロードし、推論を行います。
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image
画像プロセッサを使用してモデルのために画像を準備し、モデルに入力します。
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)モデルは、一連のバイナリマスクと対応するクラスのロジットを出力します。Mask2Formerの生の出力は、画像プロセッサを使用して簡単に事後処理することで、最終的なインスタンス、セマンティック、またはパノプティックセグメンテーションの予測を得ることができます。
prediction = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
print(prediction.keys())パノプティックセグメンテーションでは、最終的なpredictionには2つの要素が含まれます。形状が(height, width)のsegmentationマップでは、各値が与えられたピクセルのインスタンスIDをエンコードしています。また、それに対応するsegments_infoも含まれます。 segments_infoには、マップの個々のセグメントに関するさらなる情報が含まれています(クラス/カテゴリIDなど)。Mask2Formerは効率化のために形状が(96, 96)のバイナリマスク提案を出力するため、target_sizes引数を使用して最終的なマスクを元の画像サイズにリサイズします。
結果を可視化しましょう:
from collections import defaultdict
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib import cm
def draw_panoptic_segmentation(segmentation, segments_info):
# 使用されているカラーマップを取得する
viridis = cm.get_cmap('viridis', torch.max(segmentation))
fig, ax = plt.subplots()
ax.imshow(segmentation)
instances_counter = defaultdict(int)
handles = []
# 各セグメントごとに、その凡例を描画する
for segment in segments_info:
segment_id = segment['id']
segment_label_id = segment['label_id']
segment_label = model.config.id2label[segment_label_id]
label = f"{segment_label}-{instances_counter[segment_label_id]}"
instances_counter[segment_label_id] += 1
color = viridis(segment_id)
handles.append(mpatches.Patch(color=color, label=label))
ax.legend(handles=handles)
draw_panoptic_segmentation(**panoptic_segmentation)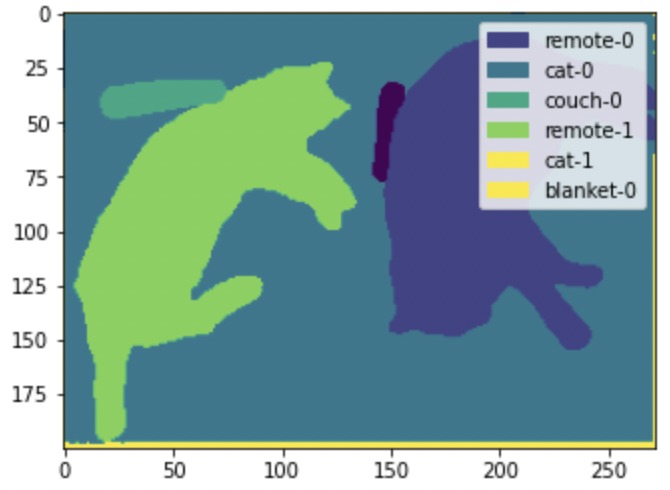
ここでは、モデルが画像の個々の猫とリモコンを検出できることがわかります。一方、セマンティックセグメンテーションでは、「猫」カテゴリ用に単一のマスクが作成されます。
OneFormerを使用して推論を実行するためには、追加のテキストプロンプトを入力として受け取るという点を除いて、同じAPIを持つデモノートブックを参照してください。
TransformersでのMask2FormerおよびOneFormerのファインチューニング
カスタムデータセットのインスタンス、意味、パノプティックセグメンテーションのいずれかに対してMask2Former/OneFormerをファインチューニングする場合は、デモノートブックをご覧ください。MaskFormer、Mask2Former、OneFormerは、類似のAPIを共有しているため、MaskFormerからのアップグレードは簡単で、最小限の変更しか必要ありません。
デモノートブックでは、モデルを読み込むためにMaskFormerForInstanceSegmentationを使用しますが、Mask2FormerForUniversalSegmentationまたはOneFormerForUniversalSegmentationに切り替える必要があります。Mask2Formerの画像処理の場合は、Mask2FormerImageProcessorに切り替える必要もあります。モデルに対応する正しいプロセッサを自動的に読み込むために、AutoImageProcessorクラスを使用してイメージプロセッサをロードすることもできます。一方、OneFormerでは、モデルのために画像とテキスト入力を準備するOneFormerProcessorが必要です。
以上です!インスタンス、意味、パノプティックセグメンテーションの違い、およびMask2FormerおよびOneFormerなどの「ユニバーサルアーキテクチャ」の使用方法について学びました。
本投稿がお役に立ち、何かを学ぶことができたことを願っています。Mask2FormerまたはOneFormerのファインチューニングの結果に満足しているかどうかをご自由にお知らせください。
このトピックが気に入った場合やもっと学びたい場合は、以下のリソースをおすすめします:
- MaskFormer、Mask2Former、OneFormerのデモノートブック。これらは、推論(可視化を含む)の広範な概要やカスタムデータのファインチューニングについて説明しています。
- Hugging Face Hubで提供されているMask2FormerおよびOneFormerの[ライブデモスペース]。これを使用して、選んだサンプル入力でモデルを簡単に試すことができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






