ビッグデータアプリケーションのクラウドストレージコストの管理
Managing Cloud Storage Costs for Big Data Applications.
クラウドベースのストレージ使用費用を削減するためのヒント

ますます増大するデータ量に対する依存度の高まりに伴い、現代の企業は高容量かつ高度にスケーラブルなデータストレージソリューションにますます依存するようになっています。多くの企業にとって、Amazon S3、Google Cloud Storage、Azure Blob Storageなどのクラウドベースのストレージサービスがこのソリューションとなり、それぞれAPIと多層ストレージなどの豊富な機能を備えており、様々なデータストレージ設計をサポートしています。もちろん、クラウドストレージサービスには関連する費用があります。この費用は、使用するストレージスペースの全体的なサイズ、クラウドストレージ内でのデータの転送、クラウドストレージ内でのデータの移動などのアクティビティなど、複数のコンポーネントで構成されています。例えば、Amazon S3の価格には、(この執筆時点で)6つの費用コンポーネントが含まれており、それらすべてを考慮する必要があります。クラウドストレージのコスト管理が複雑になることが容易に想像できます。そのため、専用の計算機(例:こちら)が開発されました。
前回の記事では、データ圧縮を使用してデータ全体のサイズを縮小することで、データストレージに関連するコストを削減することの重要性について説明しました。今回の記事では、クラウドストレージのコストの一部であるAPIリクエストのコストに焦点を当てます。このコンポーネントはしばしば見落とされがちですが、適切に管理されない場合、ビッグデータアプリケーションのコストのかなりの部分を占めることができます。具体例を示して、なぜこのコンポーネントがしばしば過小評価され、どのようにしてこのコストを抑えるかについて説明します。
免責事項
この記事の内容はAmazon S3に限らず、どのクラウドストレージサービスにも同様に適用されます。Amazon S3や他のツール、サービス、ライブラリを言及することがあっても、その使用を推奨するものではありません。最適なオプションは、あなた自身のプロジェクトの詳細に依存します。また、データを保存し、使用する方法に関するどのような設計選択肢も、自身のプロジェクトの詳細に基づいて慎重に検討する必要があります。
この記事には、Amazon EC2 c5.4xlargeインスタンス(16 vCPU、ネットワーク帯域幅「最大10 Gbps」)で実行された多数の実験が含まれています。比較可能な結果の例として、それらの出力を共有します。環境によって実験の出力が大きく異なることに留意してください。自分の設計決定のためにここで提示された結果に依存しないでください。自分自身でこれらの実験および追加の実験を実行することを強くお勧めします。
単純な思考実験
クラウドストレージから1MBのデータサンプルを取り出し、1MBのデータ出力をS3にアップロードするデータ変換アプリケーションがあるとします。Amazon EC2インスタンスで適切にアプリケーションを実行して、10億のデータサンプルを変換するように指示されたとします(データ転送費用を回避するために、S3バケットと同じリージョンのAmazon EC2インスタンスを使用します)。さて、Amazon S3は1000回のGET操作ごとに$0.0004、1000回のPUT操作ごとに$0.005(この執筆時点で)の料金を請求するとします。初見では、これらの費用はデータ変換に関連する他の費用と比較して無視できるほど低いと思われるかもしれません。しかし、簡単な計算により、私たちのAmazon S3 API呼び出しだけでも$5,400になることがわかります!!これは、コンピューティングインスタンスのコスト以上に、あなたのプロジェクトの最も支配的なコスト要因になる可能性があります。この思考実験について、記事の最後に戻ります。
大きなファイルにデータをバッチ処理する
API呼び出しのコストを削減する明白な方法は、サンプルを大きなサイズのファイルにグループ化し、サンプルのバッチで変換を実行することです。バッチサイズをNで示すと、この戦略は、マルチパートファイル転送が使用されていないと仮定すると、Nの倍数でコストを削減できる可能性があります。この技術は、PUTおよびGET呼び出しに限らず、オブジェクトファイルの数に依存するAmazon S3のすべてのコストコンポーネント(ライフサイクル移行リクエストなど)に対して費用を節約できます。
サンプルをグループ化することにはいくつかの欠点があります。例えば、サンプルを個別に保存すると、自由にアクセスできますが、サンプルをグループ化すると、アクセスがより困難になります。 (大きなファイルにサンプルをバッチ処理する場合のプロとコンについては、この記事を参照してください。)サンプルをグループ化する場合、大きさNをどのように選択するかが大きな問題となります。大きなNは、ストレージコストを削減できますが、レイテンシを導入し、計算時間を増やし、それに伴い計算コストを増やす可能性があります。最適な数を見つけるには、これらと追加の考慮事項を考慮に入れた実験が必要になる場合があります。
しかし、適用するには簡単ではありません。データには、それぞれの特定の要求と制約を持つ多数のコンシューマ(人間および人工)が存在する可能性があります。サンプルを別々のファイルに保存することで、誰もが満足するのが簡単になります。すべての人を満足させるバッチング戦略を見つけることは困難になる可能性があります。
可能な妥協:バッチ化されたPuts、個別のGets
考慮すべき妥協策として、グループ化されたサンプルが含まれた大きなファイルをアップロードする一方で、個々のサンプルにアクセスできるようにすることができます。これを行う方法の1つは、各サンプルの場所(グループ化されたファイル、開始オフセット、および終了オフセット)を保持するインデックスファイルを維持し、各コンシューマに薄いAPIレイヤーを公開することです。APIは、インデックスファイルとS3 APIを使用して実装され、オブジェクトファイルから特定の範囲を抽出できるようにします(例:Boto3のget_object関数)。この種のソリューションは、GETコールのコストを節約するわけではありません(個々のサンプルを引き続き取得するため)、より高価なPUTコールの回数が減少するため、コストを削減できます。この種の解決策は、大きなファイルオブジェクトの部分的なチャンクを抽出することを可能にするAPIに依存するため、S3とのやり取りに使用するライブラリに制限があることに注意してください。以前の記事(例:ここ)では、S3とのインターフェースの異なる方法について説明し、この機能をサポートしていないものが多数あることを説明しました。
以下のコードブロックは、PyTorchバージョン1.13を使用して、グループ化されたサンプルの大きなファイルから個々の1 MBサンプルを抽出するBoto3 get_object APIを使用する単純なPyTorchデータセットの実装方法を示しています。こちらでは、個々のファイルに保存されているサンプルを反復処理する方法とこの方法のデータ処理速度を比較します。
import os, boto3, time, numpy as npimport torchfrom torch.utils.data import Datasetfrom statistics import mean, varianceKB = 1024MB = KB * KBGB = KB ** 3sample_size = MBnum_samples = 100000# modify to vary the size of the filessamples_per_file = 2000 # for 2GB filesnum_files = num_samples//samples_per_filebucket = '<s3 bucket>'single_sample_path = '<path in s3>'large_file_path = '<path in s3>'class SingleSampleDataset(Dataset): def __init__(self): super().__init__() self.bucket = bucket self.path = single_sample_path self.client = boto3.client("s3") def __len__(self): return num_samples def get_bytes(self, key): response = self.client.get_object( Bucket=self.bucket, Key=key ) return response['Body'].read() def __getitem__(self, index: int): key = f'{self.path}/{index}.image' image = np.frombuffer(self.get_bytes(key),np.uint8) return {"image": image}class LargeFileDataset(Dataset): def __init__(self): super().__init__() self.bucket = bucket self.path = large_file_path self.client = boto3.client("s3") def __len__(self): return num_samples def get_bytes(self, file_index, sample_index): response = self.client.get_object( Bucket=self.bucket, Key=f'{self.path}/{file_index}.bin', Range=f'bytes={sample_index*MB}-{(sample_index+1)*MB-1}' ) return response['Body'].read() def __getitem__(self, index: int): file_index = index // num_files sample_index = index % samples_per_file image = np.frombuffer(self.get_bytes(file_index, sample_index), np.uint8) return {"image": image}# toggle between single sample files and large filesuse_grouped_samples = Trueif use_grouped_samples: dataset = LargeFileDataset()else: dataset = SingleSampleDataset()# set the number of parallel workers according to the number of vCPUsdl = torch.utils.data.DataLoader(dataset, shuffle=True, batch_size=4, num_workers=16)stats_lst = []t0 = time.perf_counter()for batch_idx, batch in enumerate(dl, start=1): if batch_idx % 100 == 0: t = time.perf_counter() - t0 stats_lst.append(t) t0 = time.perf_counter()mean_calc = mean(stats_lst)var_calc = variance(stats_lst)print(f'mean {mean_calc} variance {var_calc}')下の表は、サンプルグループサイズNの異なる選択肢に対するデータトラバーサルの速度をまとめたものです。
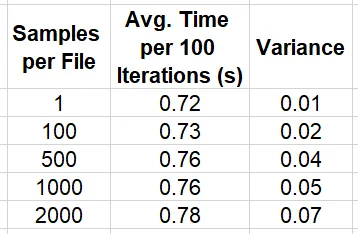
これらの結果は、個々に抽出するパフォーマンスに大きな影響を与えないように、サンプルを大きなファイルにグループ化することが比較的小さい影響しかないことを強く示唆していますが、サンプルサイズ、ファイルサイズ、ファイルオフセットの値、同じファイルからの並行読み取りの数などによって比較結果が異なることがわかりました。 Amazon S3サービスの内部動作については知りませんが、メモリサイズ、メモリアラインメント、スロットリングなどの考慮事項がパフォーマンスに影響を与えることは驚くべきことではありません。データの最適な構成を見つけるには、少しの実験が必要になることがあります。
ここで説明した節約グループ化戦略に干渉する重要な要因の1つは、マルチパートのダウンロードとアップロードの使用です。これについては、次のセクションで説明します。
マルチパートデータ転送を制御するツールを使用する
多くのクラウドストレージサービスプロバイダーは、オブジェクトファイルのマルチパートアップロードやダウンロードのオプションをサポートしています。マルチパートデータ転送では、一定の閾値より大きなファイルは複数の部分に分割され、同時に転送されます。これは、大きなファイルのデータ転送を高速化するための重要な機能です。AWSは、100 MB以上のファイルに対してマルチパートアップロードを使用することを推奨しています。次の簡単な例では、マルチパートの閾値とチャンクサイズを異なる値に設定した場合の2 GBファイルのダウンロード時間を比較します。
import boto3, timeKB = 1024MB = KB * KBGB = KB ** 3s3 = boto3.client('s3')bucket = '<bucket name>'key = '<key of 2 GB file>'local_path = '/tmp/2GB.bin'num_trials = 10for size in [8*MB, 100*MB, 500*MB, 2*GB]: print(f'multi-part size: {size}') stats = [] for i in range(num_trials): config = boto3.s3.transfer.TransferConfig(multipart_threshold=size, multipart_chunksize=size) t0 = time.time() s3.download_file(bucket, key, local_path, Config=config) stats.append(time.time()-t0) print(f'multi-part size {size} mean {mean(stats)}')この実験の結果は、以下の表にまとめられています。
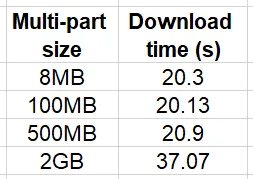
相対的な比較は、テスト環境と特にインスタンスとS3バケットの間の通信速度と帯域幅に大きく依存することに注意してください。私たちの実験は、同じ地域にあるインスタンスで実行されました。しかし、距離が増えるにつれて、マルチパートダウンロードの使用が影響を受けるようになります。
今回の議論に関するコストの影響に関しては、マルチパートデータ転送の使用により、ファイルの各部分のAPI操作に対して料金が請求されることを覚えておくことが重要です。そのため、マルチパートアップロード/ダウンロードを使用すると、データサンプルを大きなファイルにバッチ処理するコスト削減の可能性が制限されることになります。
多くのAPIは、マルチパートダウンロードをデフォルトで使用しています。これは、S3との相互作用のレイテンシを低減することが主な目的である場合には優れています。しかし、コストを制限することが懸念される場合、このデフォルトの動作はあなたにとって有利ではありません。たとえば、Boto3は、S3からファイルをアップロードおよびダウンロードするための人気のあるPython APIです。指定されていない場合、boto3 S3 API(upload_file、download_fileなど)は、8 MB以上のファイルに対してマルチパートアップロード/ダウンロードを適用するデフォルトのTransferConfigを使用します。あなたがあなたの組織でクラウドコストを制御する責任がある場合、これらのAPIがデフォルト設定で広く使用されていることに不満を感じるかもしれません。多くの場合、これらの設定が正当化されているとは考えられず、マルチパートの閾値とチャンクサイズの値を増やすか、マルチパートデータ転送を完全に無効にすることがアプリケーションのパフォーマンスにほとんど影響を与えないことがわかるでしょう。
例 — マルチパートファイル転送サイズの速度とコストへの影響
以下のコードブロックでは、シンプルなマルチプロセス変換関数を作成し、マルチパートチャンクサイズがパフォーマンスとコストに与える影響を測定します。
import os, boto3, time, mathfrom multiprocessing import Poolfrom statistics import mean, varianceKB = 1024MB = KB * KBsample_size = MBnum_files = 64samples_per_file = 500file_size = sample_size*samples_per_filenum_processes = 16bucket = '<s3 bucket>'large_file_path = '<path in s3>'local_path = '/tmp'num_trials = 5cost_per_get = 4e-7cost_per_put = 5e-6for multipart_chunksize in [1*MB, 8*MB, 100*MB, 200*MB, 500*MB]: def empty_transform(file_index): s3 = boto3.client('s3') config = boto3.s3.transfer.TransferConfig( multipart_threshold=multipart_chunksize, multipart_chunksize=multipart_chunksize ) s3.download_file(bucket, f'{large_file_path}/{file_index}.bin', f'{local_path}/{file_index}.bin', Config=config) s3.upload_file(f'{local_path}/{file_index}.bin', bucket, f'{large_file_path}/{file_index}.out.bin', Config=config) stats = [] for i in range(num_trials): with Pool(processes=num_processes) as pool: t0 = time.perf_counter() pool.map(empty_transform, range(num_files)) transform_time = time.perf_counter() - t0 stats.append(transform_time) num_chunks = math.ceil(file_size/multipart_chunksize) num_operations = num_files*num_chunks transform_cost = num_operations * (cost_per_get + cost_per_put) if num_chunks > 1: # if multi-part is used add cost of # CreateMultipartUpload and CompleteMultipartUpload API calls transform_cost += 2 * num_files * cost_per_put print(f'chunk size {multipart_chunksize}') print(f'transform time {mean(stats)} variance {variance(stats)} print(f'cost of API calls {transform_cost}')この例では、ファイルサイズを500 MBに固定し、ダウンロードとアップロードの両方に同じマルチパート設定を適用しました。より完全な分析では、データファイルのサイズとマルチパート設定を変化させる必要があります。
以下の表では、実験の結果をまとめています。
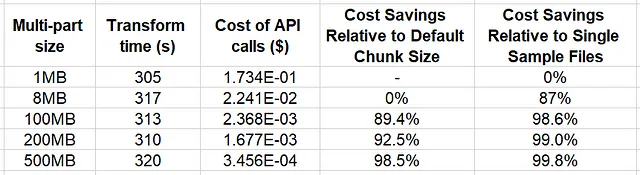
結果から、500 MB(ファイルサイズ)までのマルチパートチャンクサイズでは、データ変換時間に与える影響は最小限であることが示されています。一方、クラウドストレージAPIのコスト削減の潜在的な節約は、Boto3のデフォルトチャンクサイズ(8MB)を使用した場合に比べて、最大で98.4%に達する重要性があります。この例は、サンプルをグループ化することのコストメリットを示すだけでなく、マルチパートデータ転送設定の適切な構成による追加の節約の機会を示唆しています。
結論
本記事の冒頭で紹介した考え実験に、最後の例の結果を適用しましょう。1十億のデータサンプルに対して単純な変換を適用する場合、個々のファイルに保存する場合、コストは5,400ドルになります。データサンプルを500個ずつの2百万ファイルにグループ化し、マルチパートデータ転送を使用せずに変換を適用した場合(上記の例の最後の試行と同様)、API呼び出しのコストが10.8ドルに削減されます!!同時に、同じテスト環境を仮定した場合、全体的なランタイムに与える影響は比較的低いと予想されます(実験に基づく)。「かなり良い取引だと思いませんか?」
まとめ
クラウドベースのビッグデータアプリケーションを開発する際は、活動の全ての詳細について完全に理解することが不可欠です。本記事では、Amazon S3の価格戦略の「リクエストとデータ取得」コンポーネントに焦点を当て、このコンポーネントがビッグデータアプリケーションの全体的なコストの大きな部分になる可能性があることを示しました。データサンプルをグループ化する方法とマルチパートデータ転送を使用する方法の2つの影響を説明しました。
一つのコスト要素を最適化するだけでは、他の要素が増加し、全体的なコストが上昇する可能性があります。適切なデータストレージの設計には、すべての潜在的なコスト要因を考慮する必要があり、特定のデータニーズと使用パターンに大きく依存するでしょう。
いつも通り、コメントや修正についてはお気軽にお問い合わせください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
