「Amazon SageMakerを使用したフェデレーテッドラーニングによる分散トレーニングデータを用いた機械学習」
Machine Learning with Distributed Training Data using Federated Learning with Amazon SageMaker
機械学習(ML)は、さまざまな業界でソリューションを革新し、データから新しい洞察と知識を生み出しています。多くのMLアルゴリズムは大規模なデータセットで訓練され、データ中のパターンを一般化し、新しい未知のレコードが処理される際にそれらのパターンから結果を推論します。通常、データセットやモデルが単一のインスタンスで訓練するには大きすぎる場合、分散トレーニングを使用してクラスタ内の複数のインスタンスを使用し、訓練プロセス中にデータまたはモデルのパーティションをそれらのインスタンスに分散させることができます。Amazon SageMaker SDKでは、分散トレーニングのネイティブサポートが提供されており、一般的なフレームワークのサンプルノートブックも提供されています。
しかし、組織内または組織間でセキュリティやプライバシーの規制により、データが複数のアカウントまたは異なるリージョンに分散している場合、そのデータを1つのアカウントやリージョンに集中させることはできません。この場合、フェデレーテッドラーニング(FL)を使用して、全体のデータに対して一般化されたモデルを取得する必要があります。
この記事では、Amazon SageMakerでフェデレーテッドラーニングを実装する方法について説明します。
フェデレーテッドラーニングとは何ですか?
フェデレーテッドラーニングは、複数の独立したトレーニングセッションを並列して実行し、結果を集約して一般化モデル(グローバルモデル)を構築するMLの手法です。具体的には、各トレーニングセッションは独自のデータセットを使用し、独自のローカルモデルを取得します。異なるトレーニングセッションのローカルモデルは(たとえば、モデルの重み集約など)トレーニングプロセス中にグローバルモデルに集約されます。この手法は、データセットが1つのトレーニングセッションのために結合される集中型のML技術とは異なります。
クラウド上のフェデレーテッドラーニングと分散トレーニングの比較
これらの2つのアプローチがクラウド上で実行される場合、分散トレーニングは1つのアカウントの1つのリージョンで行われ、トレーニングデータは集中型のトレーニングセッションまたはジョブから開始されます。分散トレーニングプロセス中、データセットはより小さいサブセットに分割され、戦略(データ並列化またはモデル並列化)に応じて、サブセットは異なるトレーニングノードに送信されるか、トレーニングクラスタ内のノードを経由します。つまり、個々のデータはクラスタの1つのノードに必ずしも留まるわけではありません。
一方、フェデレーテッドラーニングでは、通常、複数の独立したアカウントまたはリージョンでトレーニングが行われます。各アカウントまたはリージョンには独自のトレーニングインスタンスがあります。トレーニングデータは始めから終わりまでアカウントまたはリージョン間で分散され、個々のデータはフェデレーテッドラーニングプロセス中に異なるアカウントまたはリージョン間でそれぞれのトレーニングセッションまたはジョブによってのみ読み取られます。
Flowerフェデレーテッドラーニングフレームワーク
FATE、Flower、PySyft、OpenFL、FedML、NVFlare、Tensorflow Federatedなど、フェデレーテッドラーニングのためのいくつかのオープンソースフレームワークが利用可能です。FLフレームワークを選ぶ際には、モデルカテゴリ、MLフレームワーク、デバイスまたはオペレーティングシステムのサポートを考慮することが一般的です。また、FLフレームワークの拡張性とパッケージサイズもクラウド上で効率的に実行するために考慮する必要があります。この記事では、拡張性とカスタマイズ性に優れ、軽量なフレームワークであるFlowerを使用してSageMakerを使ったFLの実装を選びます。
Flowerは、大規模なFL実験を実行するための新しい機能を提供し、豊富な異種なFLデバイスシナリオを実現する包括的なFLフレームワークです。FLは、データの共有ができないシナリオでデータのプライバシーやスケーラビリティに関連する課題を解決します。
Flower FLの設計原則と実装
Flower FLは、言語やMLフレームワークに依存しない設計であり、完全に拡張可能であり、新しいアルゴリズム、トレーニング戦略、通信プロトコルを組み込むことができます。FlowerはApache 2.0ライセンスのもとでオープンソース化されています。
FLの実装の概念的なアーキテクチャは、論文「Flower: A friendly Federated Learning Framework」で説明されており、次の図で強調されています。
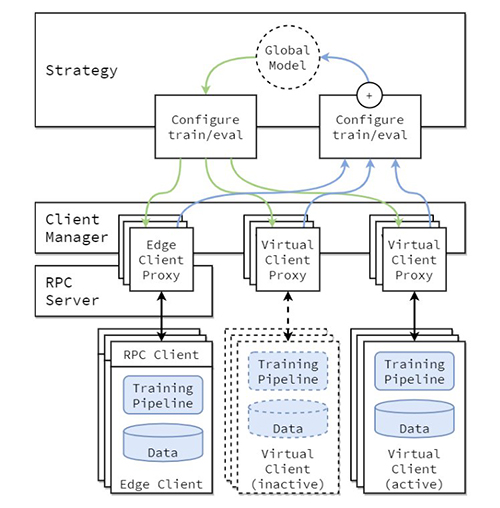
このアーキテクチャでは、エッジクライアントは実際のエッジデバイス上に存在し、RPCを介してサーバーと通信します。一方、仮想クライアントは非アクティブ時にほぼゼロのリソースを消費し、トレーニングや評価のためにクライアントが選択されるときにのみモデルとデータをメモリに読み込みます。
Flowerサーバーは戦略と設定を構築し、それらの設定辞書(または短いconfig dict)をProtoBuf表現にシリアライズし、gRPCを使用してクライアントに転送し、Python辞書に逆シリアル化します。
Flower FLの戦略
Flowerは、戦略の抽象化を通じて学習プロセスのカスタマイズを可能にします。戦略は、パラメータの初期化(サーバーまたはクライアントの初期化)、ランを初期化するために必要な利用可能なクライアントの最小数、クライアントの貢献の重み、トレーニングおよび評価の詳細を指定して、フェデレーションプロセス全体を定義します。
Flowerは、FL平均アルゴリズムと堅牢な通信スタックの広範な実装を持っています。実装された平均アルゴリズムと関連する研究論文のリストについては、以下のテーブルを参照してください。「Flower: A friendly Federated Learning Framework」から。

SageMakerを使用したフェデレーテッドラーニング:ソリューションアーキテクチャ
Flowerフレームワークを使用したSageMakerを使用したフェデレーテッドラーニングアーキテクチャは、双方向のgRPC(ファウンデーション)ストリームの上に実装されています。gRPCは、交換されるメッセージのタイプを定義し、その後、Python向けの効率的な実装を生成するためにコンパイラを使用しますが、JavaやC++などの他の言語の実装も生成できます。
Flowerクライアントは、ネットワークを介して生のバイト配列として指示(メッセージ)を受け取ります。その後、クライアントは指示をデシリアライズし、ローカルデータでトレーニングを実行します。その結果(モデルのパラメータと重み)は、シリアル化され、サーバーに送信されます。
Flower FLのサーバー/クライアントアーキテクチャは、FlowerサーバーとFlowerクライアントと同じリージョン内の異なるアカウントのノートブックインスタンスを使用してSageMakerで定義されます。トレーニングおよび評価戦略、およびグローバルパラメータは、サーバー上で定義され、その後、構成がシリアル化され、VPCピアリングを介してクライアントに送信されます。
ノートブックインスタンスクライアントは、カスタムスクリプトを実行してFlowerクライアントのインスタンス化をトリガーし、サーバーの構成をデシリアライズして読み取り、トレーニングジョブをトリガーし、パラメータの応答を送信します。
最後のステップは、サーバーで行われ、サーバーの戦略で指定された実行回数とクライアントでの実行回数が完了した際に、新しく集約されたパラメータの評価がトリガーされます。この評価は、サーバー上にのみ存在するテストデータセットで行われ、新しい改善された精度メトリックが生成されます。
以下の図は、SageMaker上のFLセットアップのアーキテクチャを示しています。
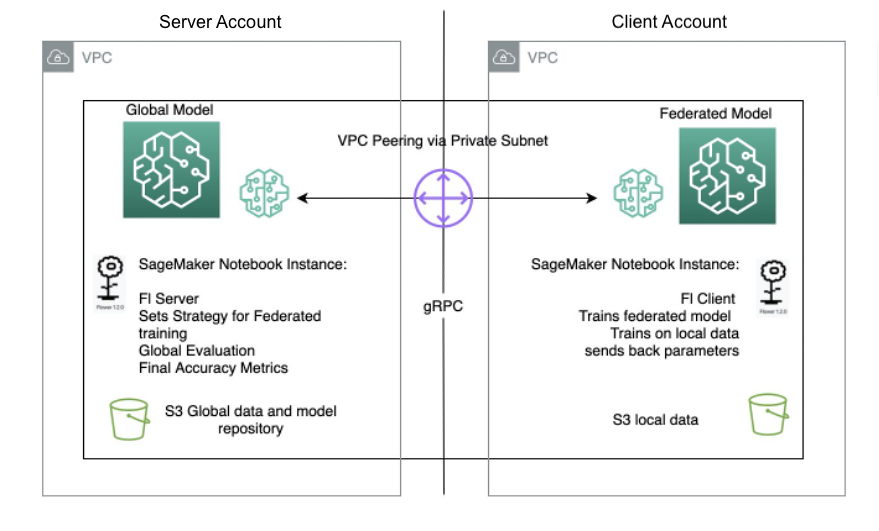
SageMakerを使用したフェデレーテッドラーニングの実装
SageMakerは、完全に管理されたMLサービスです。SageMakerを使用すると、データサイエンティストや開発者は迅速にMLモデルを構築およびトレーニングし、本番環境にデプロイすることができます。
この記事では、SageMakerを使用してノートブックエクスペリエンス環境を提供し、SageMakerトレーニングジョブを使用してAWSアカウント間でフェデレーテッドラーニングを実行する方法を示します。生のトレーニングデータは、データを所有するアカウントから出ることはなく、派生した重みのみがピアリング接続を介して送信されます。
この記事では、次の主要なコンポーネントに焦点を当てています:
- ネットワーキング – SageMakerは、デフォルトのネットワーキング構成の迅速なセットアップを可能にすると同時に、組織の要件に応じてネットワーキングを完全にカスタマイズすることもできます。この例では、リージョン内でのVPCピアリング構成を使用しています。
- クロスアカウントアクセス設定 – サーバーアカウントのユーザーがクライアントアカウントでモデルトレーニングジョブを開始できるようにするために、AWS Identity and Access Management(IAM)ロールを使用してアカウント間でアクセスを委任します。これにより、サーバーアカウントのユーザーは、SageMakerでの操作を実行するためにアカウントからサインアウトしてクライアントアカウントにサインインする必要はありません。この設定は、SageMakerトレーニングジョブを開始するためのものであり、アカウント間のデータアクセス許可や共有はありません。
- クライアントアカウントでのフェデレーテッドラーニングクライアントコードの実装とサーバーアカウントでのサーバーコードの実装 – フェデレーテッドラーニングクライアントコードをクライアントアカウントで実装するには、FlowerパッケージとSageMaker管理トレーニングを使用します。一方、Flowerパッケージを使用してサーバーコードをサーバーアカウントで実装します。
VPCピアリングの設定
仮想プライベートクラウド(VPC)ピアリング接続は、プライベートIPv4アドレスまたはIPv6アドレスを使用して、2つのVPC間のトラフィックをルーティングするためのネットワーキング接続です。どちらのVPCのインスタンスも、同じネットワーク内であるかのように通信できます。
VPCピアリング接続を設定するには、まず別のVPCとのピアリングリクエストを作成します。同じアカウント内の別のVPCとのVPCピアリング接続をリクエストすることもできますが、この場合は別のAWSアカウントのVPCと接続します。リクエストを有効にするには、VPCのオーナーがリクエストを承認する必要があります。VPCピアリングに関する詳細は、「VPCピアリング接続の作成」を参照してください。
VPC内でSageMakerノートブックインスタンスを起動する
SageMakerノートブックインスタンスは、完全に管理されたML Amazon Elastic Compute Cloud(Amazon EC2)インスタンスを介してJupyterノートブックアプリを提供します。SageMaker Jupyterノートブックは、高度なデータ探索、トレーニングジョブの作成、モデルのSageMakerホスティングへの展開、モデルのテストまたは検証などに使用されます。
ノートブックインスタンスにはさまざまなネットワーキング設定があります。このセットアップでは、ノートブックインスタンスをVPCのプライベートサブネット内で実行し、直接インターネットにアクセスしないようにしています。
クロスアカウントアクセス設定の構成
クロスアカウントアクセス設定には、IAMロールを使用してサーバーアカウントからクライアントアカウントへのアクセスを委任するための2つのステップが含まれます:
- クライアントアカウントでIAMロールを作成します。
- サーバーアカウントでロールへのアクセスを許可します。
同様のシナリオを設定するための詳細な手順については、「IAMロールを使用してAWSアカウント間でアクセスを委任する」を参照してください。
クライアントアカウントでは、FL-kickoff-client-jobという名前のIAMロールを作成し、ポリシーFL-sagemaker-actionsをロールに添付します。 FL-sagemaker-actionsポリシーには、次のようなJSONコンテンツが含まれています:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sagemaker:CreateTrainingJob",
"sagemaker:DescribeTrainingJob",
"sagemaker:StopTrainingJob",
"sagemaker:UpdateTrainingJob"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ec2:DescribeSubnets",
"ec2:DescribeVpcs",
"ec2:DescribeNetworkInterfaces"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"iam:GetRole",
"iam:PassRole"
],
"Resource": "arn:aws:iam::<client-account-number>:role/service-role/AmazonSageMaker-ExecutionRole-<xxxxxxxxxxxxxxx>"
}
]
}次に、FL-kickoff-client-jobロールの信頼ポリシーを信頼関係のトラストポリシーで変更します:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<server-account-number>:root"
},
"Action": "sts:AssumeRole",
"Condition": {}
}
]
}サーバーアカウントでは、既存のユーザー(たとえばdeveloper)にアクセスを切り替えるためのFL-kickoff-client-jobロールへの権限を追加します。これを行うには、FL-allow-kickoff-client-jobという名前のインラインポリシーを作成し、ユーザーに添付します。次は、ポリシーのJSONコンテンツです:
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::<client-account-number>:role/FL-kickoff-client-job"
}
}サンプルデータセットとデータの準備
この記事では、Centers for Medicare & Medicaid Services (CMS) が公開した医療事業者のデータにおける詐欺検出のためのキュレーションされたデータセットを使用します。データはトレーニングデータセットとテストデータセットに分割されています。データの大部分が非詐欺であるため、トレーニングデータセットのバランスを取るためにSMOTEを適用し、さらにトレーニングデータセットをトレーニングと検証のパートに分割します。トレーニングデータと検証データは、クライアントアカウントでモデルのトレーニングのためにAmazon Simple Storage Service (Amazon S3) バケットにアップロードされ、テストデータセットはサーバーアカウントでテスト目的でのみ使用されます。データの準備コードの詳細は、次のノートブックに記載されています。
SageMakerの事前に構築されたscikit-learnフレームワークとSageMakerの管理トレーニングプロセスを使用して、フェデレーテッドラーニングを使用してこのデータセット上でロジスティック回帰モデルをトレーニングします。
クライアントアカウントでフェデレーテッドラーニングクライアントを実装する
クライアントアカウントのSageMakerノートブックインスタンスで、client.pyスクリプトとutils.pyスクリプトを準備します。client.pyファイルにはクライアントのコードが含まれており、utils.pyファイルにはトレーニングに必要ないくつかのユーティリティ関数のコードが含まれています。scikit-learnパッケージを使用してロジスティック回帰モデルを構築します。
client.pyでは、Flowerクライアントを定義します。クライアントはクラスfl.client.NumPyClientから派生しています。以下の3つのメソッドを定義する必要があります:
- get_parameters – 現在のローカルモデルのパラメータを返します。ユーティリティ関数
get_model_parametersがこれを行います。 - fit – クライアントのアカウント内のトレーニングデータでモデルのトレーニング手順を定義します。また、サーバーからグローバルモデルのパラメータやその他の設定情報を受け取ります。受け取ったグローバルパラメータを使用してローカルモデルのパラメータを更新し、クライアントアカウントのデータセットでトレーニングを継続します。このメソッドは、トレーニング後のローカルモデルのパラメータ、トレーニングセットのサイズ、およびサーバーに任意の値を伝えるためのディクショナリを送信します。
- evaluate – クライアントアカウントの検証データを使用して提供されたパラメータを評価します。損失と検証セットのサイズ、および精度などの詳細をサーバーに返します。
以下は、Flowerクライアントの定義のコードスニペットです:
"""クライアントインターフェース"""
class FlowerClient(fl.client.NumPyClient):
def get_parameters(self, config):
return utils.get_model_parameters(model)
def fit(self, parameters, config):
utils.set_model_params(model, parameters)
with warnings.catch_warnings():
warnings.simplefilter("ignore")
model.fit(X_train, y_train)
return utils.get_model_parameters(model), len(X_train), {}
def evaluate(self, parameters, config):
utils.set_model_params(model, parameters)
loss = log_loss(y_test, model.predict_proba(X_test))
accuracy = model.score(X_test, y_test)
return loss, len(X_test), {"accuracy": accuracy}次に、SageMakerスクリプトモードを使用してclient.pyファイルの残りを準備します。これには、SageMakerトレーニングに渡されるパラメータの定義、トレーニングと検証データのロード、クライアントでのモデルの初期化とトレーニング、サーバーと通信するためのFlowerクライアントの設定、最後にトレーニングされたモデルの保存が含まれます。
utils.pyには、client.pyで呼び出されるいくつかのユーティリティ関数が含まれています:
- get_model_parameters – scikit-learnのLogisticRegressionモデルのパラメータを返します。
- set_model_params – モデルのパラメータを設定します。
- set_initial_params – モデルのパラメータをゼロとして初期化します。これは、サーバーがクライアントから初期モデルパラメータを起動時に要求するために必要です。ただし、scikit-learnフレームワークでは、
model.fit()が呼び出されるまでLogisticRegressionモデルのパラメータは初期化されません。 - load_data – トレーニングデータとテストデータをロードします。
- save_model – モデルを
.joblibファイルとして保存します。
FlowerはSageMakerの事前構築されたscikit-learn Dockerコンテナにインストールされていないため、requirements.txtファイルに flwr==1.3.0をリストします。
すべてのファイル(client.py、utils.py、およびrequirements.txt)をフォルダに配置し、それを tar zip します。.tar.gz ファイル(この投稿では source.tar.gz という名前)をクライアントアカウントの S3 バケットにアップロードします。
サーバーアカウントでフェデレーテッドラーニングサーバーを実装する
サーバーアカウントでは、Jupyter ノートブックでコードを準備します。これには2つのパートがあります。サーバーはまず、クライアントアカウントでトレーニングジョブを開始するためにロールを仮定し、その後、サーバーは Flower を使用してモデルをフェデレートします。
クライアントアカウントでトレーニングジョブを実行するためにロールを仮定する
Boto3 Python SDK を使用して AWS Security Token Service(AWS STS)クライアントを設定し、FL-kickoff-client-job ロールを仮定し、SageMaker クライアントを設定して、SageMaker の管理型トレーニングプロセスを使用してクライアントアカウントでトレーニングジョブを実行できるようにします。
sts_client = boto3.client('sts')
assumed_role_object = sts_client.assume_role(
RoleArn = "arn:aws:iam::<client-account-number>:role/FL-kickoff-client-job",
RoleSessionName = "AssumeRoleSession1"
)
credentials = assumed_role_object['Credentials']
sagemaker_client = boto3.client(
'sagemaker',
aws_access_key_id = credentials['AccessKeyId'],
aws_secret_access_key = credentials['SecretAccessKey'],
aws_session_token = credentials['SessionToken'],
)仮定されたロールを使用して、クライアントアカウントで SageMaker トレーニングジョブを作成します。トレーニングジョブでは、SageMaker の組み込み scikit-learn フレームワークを使用します。以下のコードスニペットのすべての S3 バケットと SageMaker IAM ロールは、クライアントアカウントに関連していることに注意してください。
sagemaker_client.create_training_job(
TrainingJobName = training_job_name,
HyperParameters = {
"penalty": "l2",
"max-iter": "10",
"server-address":"<server-ip-address>:8080",
"sagemaker_program": "client.py",
"sagemaker_submit_directory": "s3://<client-account-s3-code-bucket>/client_code/source.tar.gz",
},
AlgorithmSpecification = {
"TrainingImage": training_image,
"TrainingInputMode": "File",
},
RoleArn = "arn:aws:iam::<client-account-number>:role/service-role/AmazonSageMaker-ExecutionRole-<xxxxxxxxxxxxxxx>",
InputDataConfig=[
{
"ChannelName": "train",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://<client-account-s3-data-bucket>/data_prep/",
"S3DataDistributionType": "FullyReplicated",
}
},
},
],
OutputDataConfig = {
"S3OutputPath": "s3://<client-account-s3-bucket-for-model-artifact>/client_artifact/"
},
ResourceConfig = {
"InstanceType": "ml.m5.xlarge",
"InstanceCount": 1,
"VolumeSizeInGB": 10,
},
VpcConfig={
'SecurityGroupIds': [
"<client-account-notebook-instance-security-group>",
],
'Subnets': [
"<client-account-notebook-instance-sunbet>",
]
},
StoppingCondition = {
"MaxRuntimeInSeconds": 86400
},
)Flower を使用してローカルモデルをグローバルモデルに集約する
サーバーでモデルをフェデレートするためのコードを準備します。これにはフェデレーションの戦略とその初期化パラメータの定義が含まれます。以前に説明した utils.py スクリプトのユーティリティ関数を使用してモデルパラメータを初期化および設定します。Flower では、既存の戦略をカスタマイズするための独自のコールバック関数を定義することができます。評価および適合設定のカスタムコールバックとして FedAvg 戦略を使用します。以下のコードを参照してください。
"""モデルとフェデレーション戦略を初期化し、サーバーを開始します"""
model = LogisticRegression()
utils.set_initial_params(model)
strategy = fl.server.strategy.FedAvg(
min_available_clients = 1, # トレーニングラウンドを開始する前にサーバーに接続する必要があるクライアントの最小数
min_fit_clients = 1, # 次のラウンドのサンプルにするクライアントの最小数
min_evaluate_clients = 1,
evaluate_fn = get_evaluate_fn(model, X_test, y_test),
on_fit_config_fn = fit_round,
)
fl.server.start_server(
server_address = args.server_address,
strategy = strategy,
config = fl.server.ServerConfig(num_rounds=3) # 3 ラウンド実行
)
utils.save_model(args.model_dir, model)以下の2つの関数は、前のコードスニペットで言及されています:
- fit_round – ラウンド番号をクライアントに送信するために使用されます。このコールバックをストラテジの
on_fit_config_fnパラメータとして渡します。これは単にon_fit_config_fnパラメータの使用例を示すために行っています。 - get_evaluate_fn – サーバ上でモデルの評価に使用されます。
デモの目的で、クライアントのアカウントからフェデレーテッドされたモデルを評価し、結果をクライアントに戻すために、データ準備で設定したテストデータセットを使用します。ただし、ほとんどの実際のユースケースでは、サーバアカウントで使用されるデータは、クライアントアカウントで使用されるデータセットから分割されていないことに注意してください。
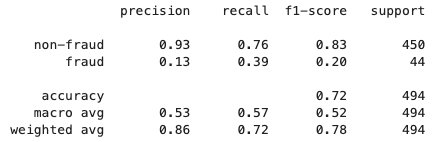
フェデレーテッド学習プロセスが終了すると、SageMakerによってmodel.tar.gzファイルがクライアントアカウントのS3バケットにモデルアーティファクトとして保存されます。同時に、model.joblibファイルがサーバアカウントのSageMakerノートブックインスタンスに保存されます。最後に、テストデータセットを使用してサーバ上の最終モデル(model.joblib)をテストします。最終モデルのテスト結果は以下の通りです:
クリーンアップ
作業が完了したら、サーバアカウントとクライアントアカウントのリソースをクリーンアップして、追加料金を避けるために以下の手順を実行してください:
- SageMakerノートブックインスタンスを停止します。
- VPCピアリング接続と対応するVPCを削除します。
- データストレージ用に作成したS3バケットを空にして削除します。
結論
この投稿では、Flowerパッケージを使用してSageMakerでフェデレーテッド学習を実装する方法について説明しました。VPCピアリングの設定、クロスアカウントアクセスのセットアップ、およびFLクライアントとサーバの実装方法を示しました。この投稿は、制限されたデータ共有でアカウント間で分散データを使用してSageMakerでMLモデルをトレーニングする必要がある方に役立ちます。この投稿でのFLはSageMakerを使用して実装されているため、SageMakerで利用できる機能はさらに多くのものがあります。
SageMakerでフェデレーテッド学習を実装することで、SageMakerが提供するすべての高度な機能を活用することができます。AWSクラウド上でフェデレーテッド学習を実現または適用する他の方法もあります。たとえば、EC2インスタンスやエッジでの利用です。これらの代替手法の詳細については、「FedMLを使用したAWSでのフェデレーテッド学習」と「エッジでのML用フェデレーテッド学習の適用」を参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
