「機械学習評価指標 理論と概要」
Machine Learning Evaluation Metrics Theory and Overview

新しいデータに対して適切に一般化する機械学習モデルを構築することは非常に困難です。モデルが十分に良いか、パフォーマンスを向上させるために修正が必要かを理解するために評価する必要があります。
モデルがトレーニングセットから十分なパターンを学習しない場合、トレーニングセットとテストセットの両方でパフォーマンスが低下します。これがいわゆる適合不足の問題です。
トレーニングデータのパターンについて過剰に学習すると、ノイズを含めてモデルはトレーニングセットで非常に優れたパフォーマンスを発揮しますが、テストセットではうまく機能しません。この状況が過学習です。モデルの一般化は、トレーニングセットとテストセットの両方で測定されるパフォーマンスが似ている場合に得られます。
この記事では、分類問題と回帰問題の最も重要な評価メトリックスを紹介します。これにより、モデルがトレーニングサンプルのパターンを適切に捉え、未知のデータでのパフォーマンスが良いかどうかを確認するのに役立ちます。さあ、始めましょう!
分類
対象がカテゴリカルな場合、分類問題に取り組んでいます。最適なメトリックスの選択は、データセットの特性、アンバランスかどうか、および分析の目標など、さまざまな側面に依存します。
評価メトリックスを示す前に、分類モデルのパフォーマンスを要約する重要な表である混同行列というものを説明する必要があります。
たとえば、超音波画像から乳がんを検出するモデルを訓練したいとします。悪性と良性の2つのクラスしかありません。
- 真陽性:悪性のがんと予測された末期患者の数
- 真陰性:良性のがんと予測された健康な人の数
- 偽陽性:悪性のがんと予測された健康な人の数
- 偽陰性:良性のがんと予測された末期患者の数

正解率

正解率は、分類モデルを評価するための最もよく知られたメトリックスの1つです。これは、正しい予測の割合をサンプル数で割ったものです。
正解率は、データセットがバランスしていることを認識している場合に使用されます。つまり、出力変数の各クラスには同じ数の観測値があるということです。
正解率を使用することで、「モデルはすべてのクラスを正しく予測していますか?」という質問に答えることができます。そのため、陽性クラス(悪性がん)と陰性クラス(良性がん)の正しい予測があります。
適合率

正確さとは異なり、適合率はクラスがアンバランスな場合に使用される分類の評価メトリックスです。
適合率は次の質問に答えます。「悪性がんの検出のうち、実際に正しいものはどれくらいですか?」。真陽性と陽性予測の比率で計算されます。
偽陽性の数が少ないほど、適合率は高くなります。
再現率

適合率と共に、再現率は出力変数のクラスごとに異なる観測値の数を持つ場合に適用される別のメトリックスです。再現率は次の質問に答えます。「悪性がんを持つ患者の何割を認識できましたか?」。
偽陰性に焦点を当てる場合、再現率に注意を払う必要があります。偽陰性とは、患者が悪性の癌を持っているが、私たちはそれを識別することができなかったことを意味します。そのため、未知のデータにおいて望ましい良いパフォーマンスを得るために、再現率と適合率の両方を監視する必要があります。
F1スコア
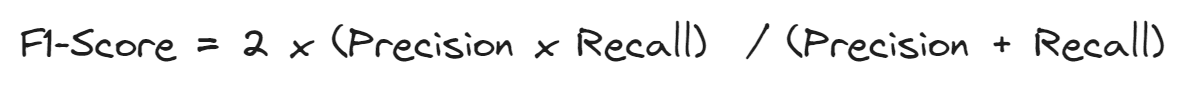
適合率と再現率の両方を監視することは混乱することがあり、これらの指標をまとめた指標があると望ましいです。それがF1スコアであり、適合率と再現率の調和平均として定義されています。
F1スコアが高いのは、適合率と再現率の両方が高い値を持っていることによるものです。再現率または適合率が低い値を持つ場合、F1スコアは罰則を受け、その結果、低い値になります。
回帰

出力変数が数値である場合、回帰問題を扱っています。分類問題と同様に、分析の目的に応じて回帰モデルの評価指標を選択することが重要です。
回帰問題の最も一般的な例は、家の価格の予測です。家の価格を正確に予測することに興味がありますか?それとも全体の誤差を最小化することだけに関心がありますか?
これらの指標では、構築ブロックは予測値と実測値の差(残差)です。
MAE
 平均絶対誤差(MAE)は、平均絶対残差を計算します。
平均絶対誤差(MAE)は、平均絶対残差を計算します。
他の評価指標と比べて、高い誤差に対してはあまり罰則がなく、すべての誤差が同様に扱われるため、この指標は外れ値に対して頑健です。また、差の絶対値はエラーの方向を無視します。
MSE
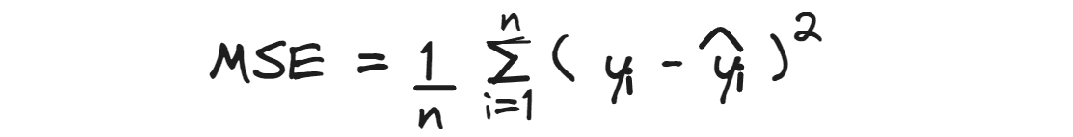
平均二乗誤差(MSE)は、平均二乗残差を計算します。
予測値と実測値の差が二乗されるため、高い誤差に対してより重みを持ちます。したがって、全体の誤差を最小化するよりも、大きな誤差を避けることが望ましい場合に有用です。
RMSE
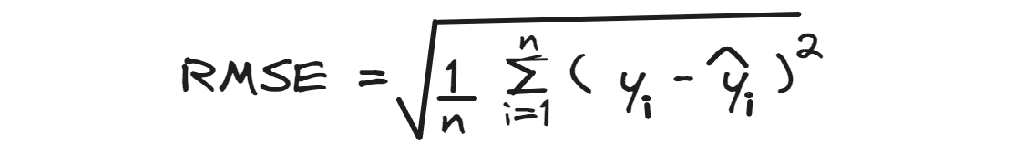
平均二乗平方根誤差(RMSE)は、平均二乗残差の平方根を計算します。
MSEを理解している場合、RMSEはMSEの平方根であることを理解するのに時間をかけます。RMSEの良い点は、指標が目標変数のスケールであるため、解釈が容易であることです。形状を除いては、MSEと非常に似ており、常に大きな差に重みを与えます。
MAPE
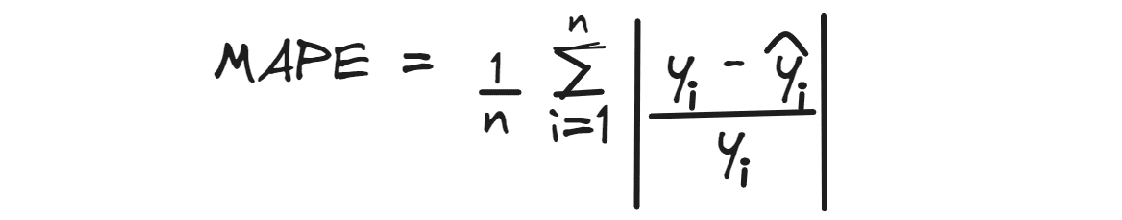
平均絶対パーセンテージ誤差(MAPE)は、予測値と実測値の平均絶対パーセント差を計算します。
MAEと同様に、誤差の方向を無視し、理想的には値が0であることが最良です。
たとえば、家の価格の予測に対して0.3のMAPE値を得た場合、平均して予測が実測値よりも30%低いことを意味します。
最後の考え
評価メトリックの概要を楽しんでいただけたことを願っています。分類と回帰モデルのパフォーマンスを評価するための最も重要な指標について説明しました。ここに挙げられていないが、問題の解決に役立った他の命を救うメトリックがある場合は、コメントに書き込んでください。Eugenia Anelloは現在、イタリアのパドヴァ大学情報工学部の研究員です。彼女の研究プロジェクトは、持続的学習と異常検出を組み合わせたものに焦点を当てています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 報告書:OpenAIがGPT-VisionというマルチモーダルLLMをリリースするための取り組みを加速中
- 「画像の補完の進展:この新しいAI補完による2Dと3Dの操作のギャップを埋めるニューラル放射場」
- 「PyTorchモデルのパフォーマンス分析と最適化—パート6」
- 機械学習の革新により、コンピュータの電力使用量が削減されています
- StableSRをご紹介します:事前トレーニング済み拡散モデルの力を活用した新たなAIスーパーレゾリューション手法
- 「11/9から17/9までの週のトップ重要なコンピュータビジョンの論文」
- 無料でGoogle Colab上でQLoraを使用してLLAMAv2を微調整する





