Macでの安定したDiffusion XLと高度なCore ML量子化
MacでのDiffusion XLとCore ML量子化
Stable Diffusion XLは昨日リリースされ、素晴らしいです。大きな(1024×1024)高品質の画像を生成することができます。新しいトリックにより、プロンプトへの適合性が向上しました。最新のノイズスケジューラの研究により、非常に暗いまたは非常に明るい画像を簡単に生成することができます。さらに、オープンソースです!
一方、モデルはより大きくなり、したがって一般的なハードウェアでの実行が遅くなり、困難になりました。Hugging Faceのdiffusersライブラリの最新リリースを使用すると、16 GBのGPU RAMでCUDAハードウェア上でStable Diffusion XLを実行できるため、Colabの無料層で使用することができます。
過去数か月間、人々がさまざまな理由でローカルでMLモデルを実行することに非常に興味を持っていることが明確になってきました。これにはプライバシー、利便性、簡単な実験、または利用料金がかからないことなどが含まれます。AppleとHugging Faceの両方でこの領域を探索するために、私たちは一生懸命取り組んできました。私たちはApple SiliconでStable Diffusionを実行する方法を示したり、Core MLの最新の進化を利用してサイズとパフォーマンスを改善するための6ビットのパレット化を紹介したりしました。
Stable Diffusion XLでは、次のようなことを行いました:
- 「テキスト分析の未来を明らかにする BERTを使用したトレンディなトピックモデリング」
- 「責任ある生成AIのための3つの新興プラクティス」
- ソフトウェア開発の進化:ウォーターフォールからアジャイル、デボップスそして更に先へ
- ベースモデルをCore MLにポートし、ネイティブのSwiftアプリで使用できるようにしました。
- Appleの変換および推論リポジトリを更新し、興味のあるファインチューニングを含むモデルを自分で変換できるようにしました。
- Hugging Faceのデモアプリを更新し、Hubからダウンロードした新しいCore ML Stable Diffusion XLモデルの使用方法を示しました。
- ミックスビットパレット化という、重要なサイズ削減を実現しながら品質の損失を最小限に抑える高度な圧縮技術を探索しました。あなた自身のモデルにも同じ技術を適用することができます!
すべてがオープンソースで、今日すぐに利用できます。始めましょう。
目次
- Hugging Face HubからSD XLモデルを使用する
- ミックスビットパレット化とは何ですか?
- ミックスビットレシピはどのように作成されますか?
- ファインチューニングモデルの変換
- 公開リソース
Hugging Face HubからSD XLモデルを使用する
このリリースの一環として、Core MLで2つの異なるバージョンのStable Diffusion XLを公開しました。
apple/coreml-stable-diffusion-xl-baseは、量子化なしの完全なパイプラインです。apple/coreml-stable-diffusion-mixed-bit-palettizationには(他のアーティファクトと共に)UNetがミックスビットパレット化レシピで置き換えられた完全なパイプラインが含まれており、パラメータあたりの圧縮率が4.5ビットに相当します。サイズは4.8 GBから1.4 GBに減少し、71%の削減が行われ、品質は私たちの意見ではまだ素晴らしいです。
どちらのモデルもAppleのSwiftコマンドライン推論アプリ、またはHugging Faceのデモアプリを使用してテストすることができます。以下は、新しいStable Diffusion XLパイプラインを使用した後者の例です:
以前のStable Diffusionのリリースと同様に、コミュニティがさまざまなドメイン用の新しいファインチューニングバージョンを作成することが予想され、それらの多くがCore MLに変換されます。このフィルタをチェックして、さまざまなモデルを探索することができます!
Stable Diffusion XLは、macOS 14のパブリックベータを実行しているApple Silicon Macで動作します。現在、CPU + GPUコンピュートユニット向けに設計されたORIGINALアテンション実装が使用されています。なお、リファイナーステージはまだ移植されていません。
参考までに、異なるデバイスで達成したパフォーマンスの数字を以下に示します:
ミックスビットパレット化とは何ですか?
先月、16ビットの重みをパラメータあたりわずか6ビットに変換する事後トレーニングの量子化手法である6ビットパレット化について説明しました。これにより、モデルサイズが重要に削減されますが、ビット数が減少するにつれてモデルの品質がますます影響を受けるため、それ以上の削減は難しいです。
モデルサイズをさらに削減するオプションの1つは、トレーニング時の量子化を使用することです。これは、モデルを微調整する間に量子化テーブルを学習することで行われます。これは非常に有効ですが、変換したいモデルごとに微調整フェーズを実行する必要があります。
代わりに、ミックスビットパレット化という異なる代替手法を探索しました。各パラメータごとに6ビットを使用する代わりに、モデルを調べて各レイヤーごとにどれだけの量子化ビットを使用するかを決定します。各レイヤーが全体の品質低下にどれだけ寄与しているかを基に判断し、一部の入力に対して量子化モデルと元のモデルのPSNR(ピーク信号対雑音比)を比較し、float16モードで測定します。我々はいくつかのビット深度でレイヤーごとに探索します:1 (!), 2, 4, 8。たとえば、2ビットを使用するとレイヤーの品質が著しく低下する場合、4などに移動します。一部のレイヤーは品質を保持するのに重要な場合には16ビットモードで保持されるかもしれません。
この方法を使用すると、平均して2.8ビットなどの効果的な量子化を実現でき、試した組み合わせごとの劣化の影響を測定することができます。これにより、目標の品質とサイズの予算に最適な量子化をよりよく知ることができます。
この方法を説明するために、次のような量子化の「レシピ」を考えてみましょう。これらのレシピは、分析実行の結果から取得したものです(後で生成方法を説明します):
{
"model_version": "stabilityai/stable-diffusion-xl-base-1.0",
"baselines": {
"original": 82.2,
"linear_8bit": 66.025,
"recipe_6.55_bit_mixedpalette": 79.9,
"recipe_4.50_bit_mixedpalette": 75.8,
"recipe_3.41_bit_mixedpalette": 71.7,
},
}これが教えてくれるのは、PSNR(float16で測定した)によると、元のモデルの品質は約82 dBであるということです。素朴な8ビットの線形量子化を行うと、品質は66 dBまで低下します。しかし、平均してパラメータごとに6.55ビットで圧縮するレシピがあり、PSNRは80 dBを保ちます。2番目と3番目のレシピはモデルのサイズをさらに削減しますが、8ビットの線形量子化よりもまだ大きなPSNRを保ちます。
視覚的な例として、同じシードで3つのレシピを実行した場合のプロンプト「サーフィンする犬の高品質写真」の結果は次のとおりです:
一部の初期的な結論:
- 私たちの意見では、すべての画像はリアルさの観点で良質です。6.55と4.50のバージョンはこの点で16ビットバージョンに近いです。
- 同じシードは同等の構成を生成しますが、同じ詳細を保持しません。たとえば、犬の品種は異なるかもしれません。
- 圧縮を増やすとプロンプトへの適合性が低下する可能性があります。この例では、攻撃的な3.41のバージョンではボードが失われます。PSNRは全体的にどれだけピクセルが異なるかを比較するだけであり、画像内の被写体には関心がありません。結果を調べ、使用ケースに応じて評価する必要があります。
この技術はStable Diffusion XLに最適です。なぜなら、前のバージョンに比べてパラメータの数が3倍に増えたにもかかわらず、ほぼ同じUNetサイズを維持できるからです。しかし、これに限定されるものではありません!この方法は、Stable Diffusion Core MLモデルに適用することができます。
ミックスビットレシピはどのように作成されるのですか?
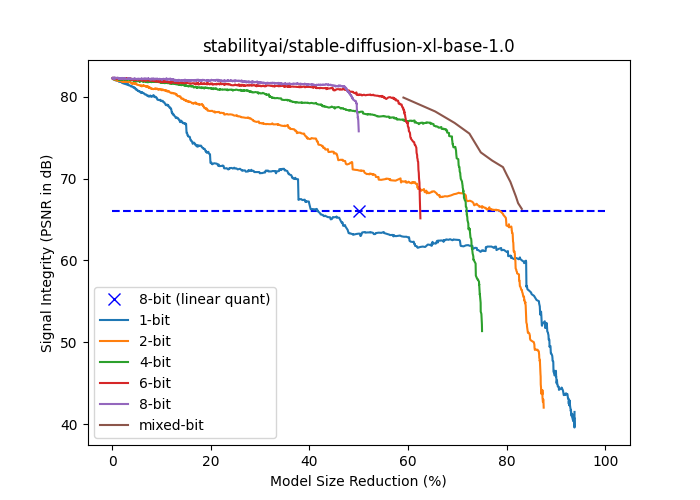
次のプロットは、stabilityai/stable-diffusion-xl-base-1.0の信号強度(dBでのPSNR)とモデルサイズの削減率(float16サイズの%)を示しています。 {1,2,4,6,8}ビットの曲線は、固定ビット数のパレットを使用してより多くのレイヤーを徐々にパレット化して生成されます。レイヤーはエンドツーエンドの信号強度への孤立した影響の昇順で並べ替えられ、累積圧縮の影響ができるだけ遅れるようになっています。ミックスビットのカーブは、レイヤーの孤立したエンドツーエンド信号の完全性への影響がある閾値を下回った場合に、より高いビット数に戻ることに基づいています。パレット化に基づいたすべての曲線は、1ビットを除くすべてのモデルサイズで線形8ビット量子化を上回る性能を発揮します。
混合ビットのパレット化は、分析と適用の2つのフェーズで実行されます。
分析フェーズの目標は、混合ビットカーブ(図の他のすべてのカーブよりも上にある茶色のカーブ)でポイントを見つけることです。これにより、希望する品質とサイズのトレードオフを選択できます。前のセクションで説明したように、層を反復処理して、与えられたPSNR閾値以上の結果をもたらす最低ビット深度を選択します。さまざまな閾値に対してプロセスを繰り返し、異なる量子化戦略を得ます。このプロセスの結果は、各層の使用するビット数を詳細に記述したJSON辞書である量子化レシピのセットです。パラメータの少ない層は無視され、シンプルさのためにfloat16で保持されます。
適用フェーズでは、単にレシピを処理して、JSON構造で指定されたビット数でパレット化を適用します。
分析は時間のかかるプロセスであり、GPU(mpsまたはcuda)が必要です。複数回の推論を実行する必要があるためです。処理が完了すると、レシピの適用は数分で行うことができます。
これらの各フェーズに対してスクリプトを提供しています:
mixed_bit_compression_pre_analysis.pymixed_bit_compression_apply.py
ファインチューニングモデルの変換
以前にStable DiffusionモデルをCore MLに変換したことがある場合、コマンドラインコンバータを使用したXLの場合も非常に似たプロセスです。モデルがXLファミリーに属することを示す新しいフラグがあり、それが該当する場合は--attention-implementation ORIGINALを使用する必要があります。
プロセスの概要については、リポジトリまたは以前のブログ記事の手順を確認し、上記のフラグを使用することを確認してください。
混合ビットのパレット化の実行
Stable DiffusionまたはStable Diffusion XLモデルをCore MLに変換した後、上記で言及したスクリプトを使用して、オプションで混合ビットのパレット化を適用できます。
分析プロセスが遅いため、最も人気のあるモデル用のレシピを用意しています:
- Stable Diffusion 1.5用のレシピ
- Stable Diffusion 2.1用のレシピ
- Stable Diffusion XL 1.0ベース用のレシピ
これらをダウンロードしてローカルで試してみることができます。
さらに、Stable Diffusion XLの分析から得られた3つの最良のレシピをUNetのCore MLバージョンにも適用し、ここで公開しています。自由に試してみて、どのように機能するかを確認してください!
最後に、前述のように、4.5ビットのレシピを使用する完全なStable Diffusion XL Core MLパイプラインを作成しました。
公開リソース
apple/ml-stable-diffusion(Appleによるもの)。Swift(およびPython)の変換および推論ライブラリ。huggingface/swift-coreml-diffusers。Appleのパッケージをベースに構築されたHugging Faceデモアプリ。- Stable Diffusion XL 1.0ベース(Core MLバージョン)。上記のリポジトリや他のサードパーティのアプリを使用して実行可能なモデル。
- 混合ビットのパレット化(Core ML)を使用したStable Diffusion XL 1.0ベース。UNetを平均して4.5ビットの効果的なパレット化で量子化した同じモデル。
- 混合ビットのパレット化を適用した追加のUNet。
- 人気のあるモデル用に事前計算された混合ビットのパレット化レシピ。すぐに使用できます。
mixed_bit_compression_pre_analysis.py。混合ビットの分析とレシピ生成を実行するスクリプト。mixed_bit_compression_apply.py。分析フェーズで計算されたレシピを適用するスクリプト。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






