Ludwig – より「フレンドリーな」ディープラーニングフレームワーク
Ludwig - A friendly deep learning framework.
低コード、宣言的フレームワークで簡単にDeep Learningを実現

背景 – Deep Learningは複雑すぎる?
私は、産業用途のDeep Learningから遠ざかってきました。関心がないわけではなく、人気のあるDeep Learningフレームワークが扱いにくいと感じているためです。PytorchやTensorFlowは研究目的には素晴らしいツールであることは認めますが、APIはユーザーフレンドリーではありません。クライアントに素早いコンセプトの証明を提供する必要がある場合、Pytorchテンソルをいじくることはしたくないものです。
ロンドンで開催されたAIサミットに参加していると、私のDeep Learningの問題に対する解決策を提供しているというチームに出くわしました。彼らは、「TensorFlowとAutoMLの中間点」と説明される別のアプローチを利用しており、Ludwigと呼ばれるフレームワークを活用しています。
Ludwigとは何ですか?
Uberによって開発されたLudwigは、Deep Learningモデルを構築するためのオープンソースフレームワークです。宣言的であり、TensorFlowのように複雑なモデルをレイヤーごとに構築する代わりに、構成ファイルでモデルの構造を宣言するだけです。これはあまりにも良いと感じましたので、自分自身で確認する必要がありました。この記事の残りの部分では、Kaggleから取り上げたプロジェクトを例にLudwigの経験を詳しく説明します。途中でその強み、痛点について議論し、使用する価値があるかどうかについての結論を述べます。
注意 – Ludwigは初めにUberによって開発されましたが、Apache 2.0ライセンスのオープンソースライブラリです。プロジェクトはLinux Foundation AI&Dataによってホストされています。私はUberまたはLudwigの開発者と商業的な関係はありません。
- 精度を超えて:長期的なユーザー維持のための偶然性と新規性の推奨事項の受け入れ
- Python から Julia へ:特徴量エンジニアリングと機械学習
- 人間の脳血管のアトラスは、アルツハイマー病における変化を強調します
プロジェクト – 需要予測
プロジェクト概要: 小売業者WOMartの各店舗における最終30日間の注文を予測する。
あなたのクライアントであるWOMartは、ウェルネスとフィットネスに必要な製品の包括的な範囲を提供する、主要な栄養補助食品小売チェーンです。
WOMartは、100以上の都市にある350以上の小売店を持つマルチチャネル流通戦略を採用しています。
データ
データセットには、与えられた店舗での1日の販売に関する22,265の観測値がありました。データセットの詳細については省略しますが、ここでいくつかの記述統計を確認できます。
注意: データはオープンデータコモンズライセンスの下で任意の目的に使用できます。
- データへのリンク
- データのライセンス
データ辞書:
手法の概要
ここでは手法について詳しく説明しません。これはこの記事の主目的ではありません。高いレベルで問題をフレームワークする方法について説明します。
私は、予測問題を「疑似」シーケンス-シーケンスDeep Learning問題としてフレームワークしました。この方法では、360日の時系列データポイントを利用して、その後の30日の顧客注文を予測します。いくつかのカテゴリ変数を組み込み、注文の各日について個別の予測を生成する必要があるため、やや異常なセットアップになりました。そのため、問題を説明するために「疑似」シーケンス-シーケンスという用語を使用しています。後半では、特徴量エンジニアリングの詳細について説明します。
この他にも、モデル開発には標準的な手法を用いました。データをトレーニングデータセットとホールドアウトデータセットに分割し、特徴量とラベルの再スケーリングを行いました。モデルのトレーニングはトレーニングデータで行い、ホールドアウトデータでテストを行いました。
注意:LudwigはAPI内でデータをネイティブに分割する機能を提供しています。しかし、厳格さを維持するために、独立したホールドアウトデータセットを確立しました。トレーニングデータセットは、追加のトレーニング、バリデーション、およびテストのサブセットに分割されました。ホールドアウトデータセットは完全に除外され、モデルによって生成された予測の分析にのみ使用されました。
特徴量エンジニアリング
本記事を執筆する時点では、Ludwigにおいて時系列予測に関連するシーケンス・ツー・シーケンス・モデリングはやや難しいと言えます。その理由は、特徴量エンジニアリングにあります。Ludwig APIは、シーケンスを入力として処理する優れた機能を持っていますが、時系列シーケンスを出力として処理するための一貫したアプローチが(まだ)開発されていません。複数の出力を宣言することで「疑似」シーケンス・ツー・シーケンス・モデルを開発することができますが、全体的な特徴量エンジニアリングの経験はかなり「hacky」に感じられます。
シーケンス特徴量:時間とともに変化しない特徴を除いて、予測特徴量はすべて「Ludwig形式」のシーケンスにエンジニアリングしました。各入力シーケンスは、あらかじめ定義された時間枠にわたる各「時系列」特徴量の水平スタッキングです。各特徴量シーケンスはストアレベルで決定され、データフレームの1つのセルにカプセル化されています(実際には見た目が乱雑です)。
シーケンスラベル:シーケンスラベルについては、モデルの各ポイントを個別にラベルとして宣言する必要があります。これにより、予測する注文の各日について1つのストアあたり30のラベルを宣言することになりました。
以下は、特徴量エンジニアリングのプロセスの例です:
データの例:太字の値はシーケンスラベルを構築するために使用され、通常の値はシーケンス特徴量を構築するために使用されます。
特徴量エンジニアリングの例:Order_sequenceは「Ludwig形式」のシーケンスです。ラベルは個別に返され、後でモデルの出力(ラベル)として宣言されます。
モデルのアーキテクチャ
Ludwig API では、比較的複雑でカスタマイズ可能なモデルを、宣言的にアーキテクトすることができます。Ludwigは.yamlファイルを介してこれを行います。多くのデータサイエンティストがこの記事を読んでいるかもしれないことを理解しており、.yamlファイルを使用したことがないかもしれませんが、一般的にはソフトウェア開発で構成に使用されます。最初に見ると怖いかもしれませんが、非常に使いやすいです。モデルを構築するために作成したファイルの主要な部分を見ていきましょう。

構成に入る前に、Ludwigのディープラーニングフレームワークの中心にあるエンコーダー、コンバイナー、デコーダーについて簡単に紹介することが価値があります。Ludwigで構成するほとんどのモデルは、主にこのアーキテクチャに従います。これを理解することで、要素を積み重ねて迅速にディープラーニングモデルを構築するプロセスを簡素化できます。
モデルの宣言
ファイルの最上部で、使用するモデルタイプを宣言します。Ludwigは、ツリーベースのモデルと深層ニューラルネットワークの2つのオプションを提供しています。私は後者を選択しました。
model_type: ecdデータ分割の宣言
データセットを分割するには、分割パーセンテージ、分割タイプ、および分割する列または変数を宣言することで、ネイティブに分割することができます。私の場合、ストアがデータセットのどこかにしか表示されないようにしたかったので、ハッシュ分割が完璧でした。
ベストプラクティスとして、ワンホットエンコーディングや正規化などの初期の特徴量エンジニアリングを実行している場合は、Ludwig APIの外部でホールドアウトセットを構築することをお勧めします。これにより、データ漏洩が防止されるはずです。
model_type: ecdsplit: type: hash column: Store_id probabilities: - 0.7 - 0.15 - 0.15#...省略されたセクション...モデルの入力の宣言
名前、タイプ、エンコーダーで入力を宣言します。モデルへの入力のタイプに応じて、エンコーダーのさまざまなオプションがあります。エンコーダーは、入力をモデルが解釈できるように変換する方法です。エンコーダーの選択は、データとモデリングタスクに応じて異なります。
model_type: ecdsplit: type: hash column: Store_id probabilities: - 0.7 - 0.15 - 0.15input_features: - name: Sales type: sequence encoder: stacked_cnn reduce_output: null - name: Order type: sequence encoder: stacked_cnn reduce_output: null - name: Discount type: sequence encoder: stacked_cnn reduce_output: null - name: DayOfWeek type: sequence encoder: stacked_cnn reduce_output: null - name: MonthOfYear type: sequence encoder: stacked_cnn reduce_output: null - name: Holiday type: sequence encoder: stacked_cnn reduce_output: null - name: Store_Type type: category encoder: dense - name: Location_Type type: category encoder: dense - name: Region_Code type: category encoder: dense#...省略されたセクション...コンバイナの宣言
名前が示すように、コンバイナはエンコーダの出力をまとめるものです。Ludwig APIには様々なコンバイナが用意されており、それぞれ特定のユースケースに適したものがあります。コンバイナの選択は、モデルの構造や特徴間の関係に依存する場合があります。たとえば、エンコーダの出力を単に連結したい場合は「concat」コンバイナを使用したり、特徴が順序を持つ場合は「sequence」コンバイナを使用したりすることができます。
model_type: ecdsplit: type: hash column: Store_id probabilities: - 0.7 - 0.15 - 0.15input_features: - name: Sales type: sequence encoder: stacked_cnn reduce_output: null - name: Order type: sequence encoder: stacked_cnn reduce_output: null # ...省略された部分... - name: Location_Type type: category encoder: dense - name: Region_Code type: category encoder: densecombiner: type: sequence main_sequence_feature: Order reduce_output: null encoder: # ...省略された部分...深層学習の多くの側面と同様に、最適なコンバイナの選択は、データセットや問題の詳細に依存し、実験が必要な場合があります。
モデルの出力の宣言
ネットワークを最終的に仕上げるには、出力(ラベル)を宣言するだけです。Ludwigを時系列データに使用する場合の私の苦手な点は、時系列出力を(まだ)宣言できないことです。以前に述べたように、時系列の各点を個別に宣言する必要があります。これにより、30個の別々の宣言が残り、非常に乱雑に見えます。各出力には、追加の設定ができるように、損失関数を指定することができます。Ludwigには、さまざまな出力タイプに対して事前に構築された多数のオプションがありますが、Pytorchと同様にカスタム損失関数を実装できるかどうかはわかりません。
model_type: ecdsplit: type: hash column: Store_id probabilities: - 0.7 - 0.15 - 0.15input_features: - name: Sales type: sequence encoder: stacked_cnn reduce_output: null - name: Order type: sequence encoder: stacked_cnn reduce_output: null# ...省略された部分... - name: Location_Type type: category encoder: dense - name: Region_Code type: category encoder: densecombiner: type: sequence main_sequence_feature: Order reduce_output: null encoder: type: parallel_cnnoutput_features: - name: Order_sequence_label_2019-05-02 type: number loss: type: mean_absolute_error - name: Order_sequence_label_2019-05-03 type: number loss: type: mean_absolute_error#...省略された部分... type: mean_absolute_error - name: Order_sequence_label_2019-05-30 type: number loss: type: mean_absolute_error - name: Order_sequence_label_2019-05-31 type: number loss: type: mean_absolute_error#...省略された部分...トレーナーの宣言
Ludwigのトレーナー設定は、Ludwigが合理的なデフォルトを提供しているためオプションですが、高度なカスタマイズが可能です。モデルのトレーニング方法の詳細に制御を提供します。これには、使用される最適化手法の指定、トレーニングエポック数、学習率、早期停止の基準など、他のパラメータが含まれます。
model_type: ecdsplit: type: hash column: Store_id probabilities: - 0.7 - 0.15 - 0.15input_features: - name: Sales type: sequence encoder: stacked_cnn reduce_output: null - name: Order type: sequence encoder: stacked_cnn reduce_output: null# ...省略された部分... - name: Location_Type type: category encoder: dense - name: Region_Code type: category encoder: densecombiner: type: sequence main_sequence_feature: Order reduce_output: null encoder: type: parallel_cnnoutput_features: - name: Order_sequence_label_2019-05-02 type: number loss: type: mean_absolute_error - name: Order_sequence_label_2019-05-03 type: number loss: type: mean_absolute_error#...省略された部分... type: mean_absolute_error - name: Order_sequence_label_2019-05-30 type: number loss: type: mean_absolute_error - name: Order_sequence_label_2019-05-31 type: number loss: type: mean_absolute_errortrainer: epochs: 200 learning_rate: 0.0001 early_stop: 20 evaluate_training_set: true validation_metric: mean_absolute_error validation_field: Order_sequence_label_2019-05-31使用例によっては、これらのパラメータを自分自身で定義することが有益である場合があります。例えば、モデルの複雑さやデータセットのサイズに基づいて学習率やエポック数を調整したい場合があります。同様に、早期停止は、検証セットでのモデルのパフォーマンスが改善しなくなった場合にトレーニングプロセスを停止することで、過剰適合を防止する有用なツールとなります。
モデルのトレーニング
LudwigのPython実験APIを使用して、モデルのトレーニングを簡単に行うことができます。以下はスクリプトの例です。
その他の設定
前述のもの以外にも、Ludwigには多数の可能な設定があります。これらはすべて非常によく文書化され、構造化されています。ドキュメントを読んで自分自身に慣れることをお勧めします。
モデルのパフォーマンス分析 – 簡単な概要
この記事の目的は、Ludwigフレームワークのいくつかの機能を実用的な例プロジェクトを通じて探索することです。モデルのパフォーマンスを示すこともこの記事の一部ですが、メトリックの詳細に踏み込む必要はありません。議論は、モデルの分析から生成されたいくつかのチャートを提示することに限定します。総合的なスクリプトは、記事の結論にリンクされた私のGitHubで入手できます。



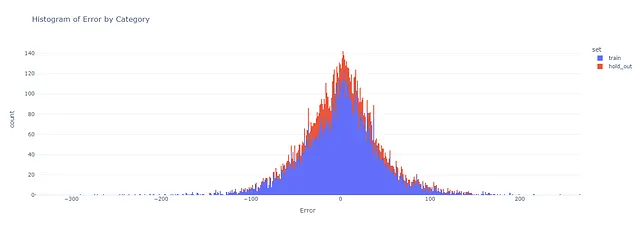
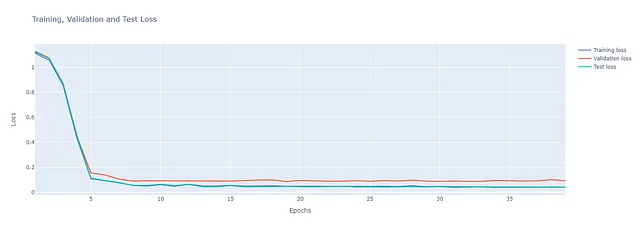
私の評価
最初はLudwigについて懐疑的でしたが、自分で実験してみた結果、その能力に納得し、約束どおりの結果を出すと信じています。いくつか本当に印象的な機能を紹介したいと思います。
コーディング体験:コーディング体験は、複雑なレゴセットを構築するような感覚です。コンポーネントや異なるアーキテクチャを試して、自分にぴったりのモデルを見つけることができます。
ドキュメント:ドキュメントは明確でよく構成されています。異なるアーキテクチャを実装したり、モデルの設定を変更する方法を理解するのは非常に簡単でした。ほとんどのドキュメントが最新であるように見えるのも嬉しいところです。
バックエンド:バックエンドの体験は優れています。ライブラリの開発者たちは、GPU上で深層ニューラルネットワークをトレーニングするために通常行う必要がある多くの設定を抽象化することに成功しました。私はGoogle Collabでモデルをトレーニングしましたが、Ludwigは自動的にワークロードをGPUに移動させました。
Ludwigのもう1つの素晴らしい点は、バックエンドが高度に構成可能であることです。たとえば、大規模なワークロードを実行し、GPUのクラスターが必要な場合は、これも設定できます!
実験トラッキング:Ludwigは、実験の実行間でモデルアーティファクトを追跡するために使用できる実験APIを提供しています。商用規模のMLOpsには素晴らしいMLflowとの統合もあると思います。
Pet Peeves
フレームワークの改善点がいくつかありますので、それらについても説明します。
可視化:Ludwigは、データセット全体でのトレーニング損失を追跡するための可視化APIを提供しています。ただし、現時点では機能が特に優れておらず、使用方法も直感的ではありません。Google Collabで実行してみましたが、うまくいきませんでした。最終的には、Ludwigが各実験の実行後に保存するtraining_statistics.jsonファイルを解析するためのPython関数をスクリプト化して、自分自身で損失曲線の可視化を作成しました。
サポート:Ludwigのコミュニティは、TensorFlowやPytorchのそれに比べてまだそれほど広範ではないようです。GitHubでいくつかの問題が提起され、支援を提供するスレッドもありますが、大部分の場合、自分自身で問題を解決する必要があるように感じます。一方、ChatGPTは2021年まで一定レベルのサポートを提供しています。
透明性:Ludwigは、深層学習モデルの構築のより困難な側面を排除することに優れています。ただし、これは透明性の犠牲になることがあり、ログがやや難解でデバッグが困難になることがあります。
結論
私の意見では、Ludwigは、商業的な設定でも学習目的でも、深層学習を利用し始めたい人にとって、優れたツールです。最新の研究目的にはあまりにも高度すぎるかもしれませんが、明確に定義された問題を迅速に解決するのに適しています。深層学習のある程度の理解は必要ですが、概念を理解したら、Ludwigへの参加のハードルは、TensorFlowやPytorchよりもかなり低くなります。
エンドツーエンドのノートブックは、私のGitHubリポジトリで利用可能ですので、自由に試してください。
LinkedInで私をフォローする
VoAGIでもっと私の知見を得るために登録してください:
私の紹介リンクでVoAGIに参加する — John Adeojo
私はデータサイエンスのプロジェクトや経験、専門知識を共有して、あなたの旅を支援します。あなたは…
johnadeojo.medium.com
AIやデータサイエンスをビジネスに統合することに興味がある場合は、無料の初回相談を予約することをお勧めします:
オンライン予約 | データ中心のソリューション
無料の相談で、ビジネスが野心的な目標を達成するのを支援する私たちの専門知識を発見してください。私たちのデータサイエンティストと…
www.data-centric-solutions.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
