「LoRAアダプターにダイブ」
LoRAアダプターにダイブ
パラメータ効率のチューニング(PEFT)の探索:LoRAを使ったファインチューニングの直感的な理解

大規模言語モデル(LLM)が世界中で注目を浴びています。この1年間で、それらができることが大幅に向上し、狭い範囲で制限されたアプリケーションから、流暢なマルチターンの会話にまで進化しました。
これらのモデルは、ソースをそのままコピーする抽出的要約から、読者のスタイルの好みや既存の知識に合わせて要約を完全に書き換える抽象的要約を提供するようになったことは驚くべきことです。さらに驚くべきことは、これらの新しいモデルが新しいコードを生成するだけでなく、既存のコードを説明できることです。魅力的です。
これらの大規模モデルは、ゼロショットまたはフューショットの方法でクエリされたときにも、驚くほどの結果を生み出すことがよくあります。これにより、迅速な実験と即座の結果の表示が可能になりますが、多くのタスクでは最高のパフォーマンスと効率を実現するためにモデルをファインチューニングする必要があります。しかし、彼らの数十億のパラメータをすべてファインチューニングすることは実用的ではありません。さらに、モデルのサイズを考慮すると、過学習せずにそのような巨大なモデルをトレーニングするだけの十分なラベル付きデータがあるのでしょうか?
パラメータ効率のチューニング(PEFT)が救世主です:あなたはわずかなウェイトのみを調整することで素晴らしいパフォーマンスを実現できます。数十億のパラメータを複数のマシンで調整する必要がないため、ファインチューニングのプロセス全体がより実用的で経済的になります。PEFTと量子化を使用することで、数十億のパラメータを持つ大規模モデルを単一のGPU上でファインチューニングすることができます。
このミニシリーズは、PEFTと具体的なLoRA [2]を探求したい経験豊富なMLプラクティショナー向けです:
- 第1の記事では、パラメータ効率のファインチューニング(PEFT)の動機について探求します。ファインチューニングの仕組みがどのように機能するのか、既存のプラクティスのどの側面を保持し、一般化し、洗練された方法で適用することができるのかを見直します。私たちは実践的になり、基礎から手を動かして、探求するために選んだ手法であるLoRAの簡単さを示します。
- 第2の記事では、LoRAを適用する際の適切なハイパーパラメータの値を見つけるために、関連する設計上の決定を見直します。途中でパフォーマンスの比較のためのベースラインを確立し、LoRAを使用して適用できるコンポーネント、その影響、適切なサイズを見直します。
- 単一のタスクのトレーニングおよびチューニングされたモデルを基に、第3の記事では複数のタスクのチューニングについても考えます。また、デプロイメントについてはどうでしょうか?単一のモデルエンドポイントを使用して複数のタスクに対する推論を行うために、単一のタスクのためにトレーニングしたアダプターの比較的小さなフットプリントを活用してホットスワッピングメカニズムを実装する方法についても考えます。
- 最初の3つの記事の過程で、PEFTを使用したトレーニング、チューニング、デプロイメントの直感的な把握を開発しました。そして、第4の記事に移行すると、非常に実践的になります。教育モデルから離れて、「これまでに何を学んだのか、それを実世界のシナリオにどのように適用するのか?」という問いに答えます。そして、目標を達成するためにHugging Faceによって確立された実装を使用します。これには、GPUメモリの効率的な使用のためにLoRAと量子化を結びつけたQLoRAを使用することも含まれます。
準備はできましたか?今日は、なぜこれがすべてうまくいくのかから始めましょう。
事前トレーニングとファインチューニングの効果について
Aghajanyanらの研究[1]では、事前トレーニング中にニューラルネットワークのレイヤーがどのように変化するかについて興味深い観察結果が示されています。これは特定のファインチューニングタスクに限らず、広く適用可能です。
具体的には、事前トレーニングによって表現の固有次元(ID)が最小化されることを示しています。彼らの研究から抜粋した次の2つの図は、この効果を示しています:
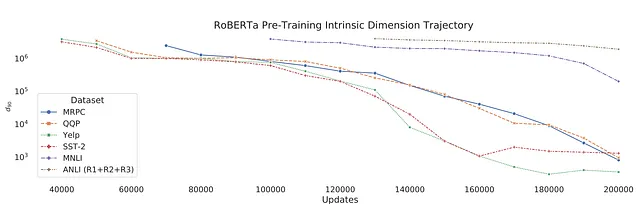
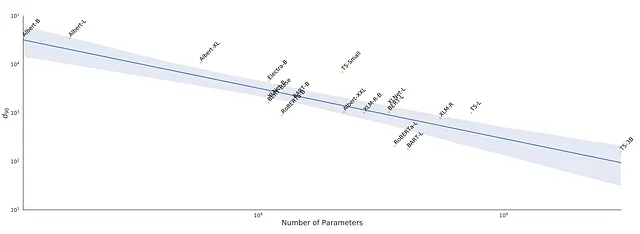
著者たちは、すべてのパラメータを微調整するのではなく、各モデルをパラメータの小さなランダムなサブセットで訓練しました。パラメータの数は、完全な微調整のパフォーマンスの90%に一致するように選ばれました。この次元数、つまり90%のパフォーマンスを達成するために必要な次元数を、上記の図の2つのy軸でd90として示しています。
最初の図では、事前学習の期間の増加に伴い、x軸上でd90が減少することが示されています。つまり、90%の完全な微調整のパフォーマンスを達成するために必要なパラメータの数が減少します。それ自体が、知識を圧縮する方法としての事前学習の効果を示しています。
2番目の図でも、容量の増加に伴い、微調整モデルでd90を達成するために必要なパラメータの数が減少しています。興味深いですね。これは、より大きなモデルが訓練データ(モデルが見る世界)のより良い表現を学び、使用しやすい階層的な特徴を作り出すことを示しています。
著者が指摘している具体的な例の1つは、RoBERTa Large(354M)のd90が約207のパラメータであることです。バム!上記の図でその例を見つけ、さらに、より小さいRoBERTa Base(123M)が90%のパフォーマンスを達成するために、ここでは896のパラメータが必要となることを確認してください。興味深いですね。
このトピックについての議論から、明示的に指摘する価値があるいくつかのことがあることを学びました:
- IDの効果を微調整中に利用していますが、上記のグラフと数値はすべて事前学習に関するものです。私たちは単に微調整の数値を使用して、結果としてのダウンストリームへの影響を具体的にします。
- より大きなモデルを使用することは、そのサイズに対してIDが低下するだけでなく、絶対的にも結果として生じます。PEFTへの移行でも同様の効果が見られます。
[1]では、上記の図2、図3を見つけることができ、引用された結果は表1から取られています。
結論として、事前学習中に学習された表現は、モデルが学んだ知識を圧縮し、これらのより意味的な表現を使用してダウンストリームモデルを微調整することを容易にします。PEFTでは、これを基にさらに進めていきます。ただし、パラメータをランダムに選択してパフォーマンスの90%を目指すのではなく、より指向性のあるアプローチを使用して、トレーニングするパラメータを選択し、完全な微調整のパフォーマンスにほぼ匹敵することを目指します。ワクワクします!
何を調整する?
非常に少数のパラメータで作業できることがわかりました。しかし、どれを調整すべきですか?モデルのどこですか?次の記事では詳細に踏み込みますが、今のところ、2つの一般的なアプローチを考えるために、考えを発展させ、問題をフレームに乗せましょう:

タスクに基づく割り当て:微調整を使用する場合、事前学習からの知識を保持し、「壊滅的な忘却」を避けたいと考えています。私たちは、ダウンストリームのタスク固有の学習が微調整モデルのタスクヘッド、つまり分類器、およびその直下のレイヤー(緑で示されている)で行われるべきであり、下部のレイヤーや埋め込みでは、言語の使用に関する一般的な知識を保持したいと考えています(赤で示されています)。しばしば私たちは、パーレイヤーの学習率でモデルを誘導したり、下部のレイヤーを完全に凍結したりします。
これは、ダウンストリームのタスクに必要な基本的な知識をモデルが学習することを期待している場所と、事前トレーニングからの既存の知識を保持する場所に基づいています。
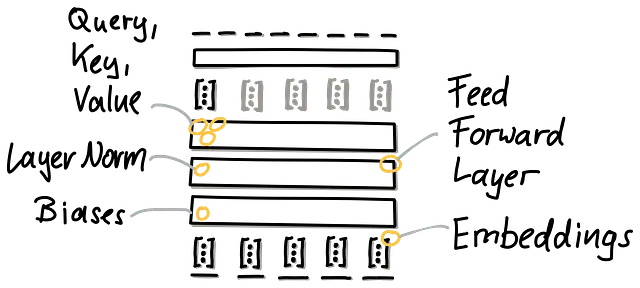
アーキテクチャに基づいて:一方、アーキテクチャのコンポーネント、そのパラメータ、およびそれらの可能な影響を見直すこともできます。上のイラストでは、例えばLayerNormとバイアスが、低容量ですがモデル全体に広がっています。これらはモデルに影響を与えるための中心的な位置にありますが、比較的少数のパラメータしか持っていません。
一方、埋め込みからのパラメータもあります。これらはタスクには近くありませんが、入力には近い位置にあります。また、埋め込みには多くのパラメータがあります。したがって、効率を考えると、これらはPEFTを含むあらゆる種類のファインチューニングにおいて最初の選択肢ではありません。
そして最後に、トランスフォーマーアーキテクチャに付属している大きな線形モジュール、つまりアテンションベクトルとフィードフォワードレイヤーがあります。これらには大量のパラメータがあり、どのレイヤーを適応するかを決めることができます。
次の記事で適切なパラメータの選択を詳しく見直します。この記事では、問題をどのように分割しても、調整したいパラメータのグループが得られることになります。この記事の残りでは、いくつかの線形モジュールがあります。
アダプタの使用による効率化
全体の線形モジュールとそのすべてのパラメータを調整する代わりに、より効率的になりたいと考えています。使用するアプローチは、アダプタを挿入することです。これらの新しいモジュールは比較的小型であり、適応したいモジュールの後に配置されます。アダプタは線形モジュールの出力を修正できます。つまり、事前トレーニングされた出力をダウンストリームタスクに有益な方法で洗練することができます。
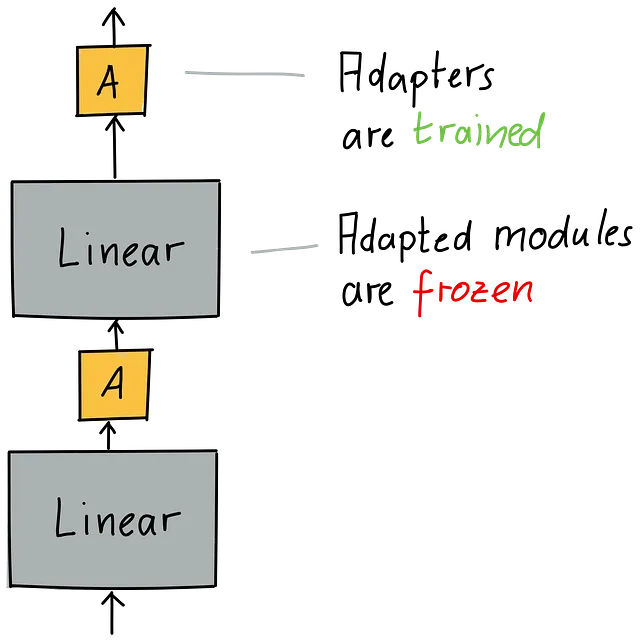
しかし、このアプローチには問題があります。それを見つけることができますか?それは、適応するモジュールとアダプタの相対的なサイズに関するものです。以下のイラストを見ると、GPUメモリが表示されます。効率化のために、モデルを可能な限り利用可能なGPUメモリにぴったり収まるようにサイズ設定します。それは、各レイヤーが同じ幅であるため、Transformerアーキテクチャの場合は特に簡単です。さらに、ダウンプロジェクトされたヘッドも完全な幅に追加されます。したがって、Transformerのコンポーネントの均一な幅に基づいてバッチサイズを選択できます。
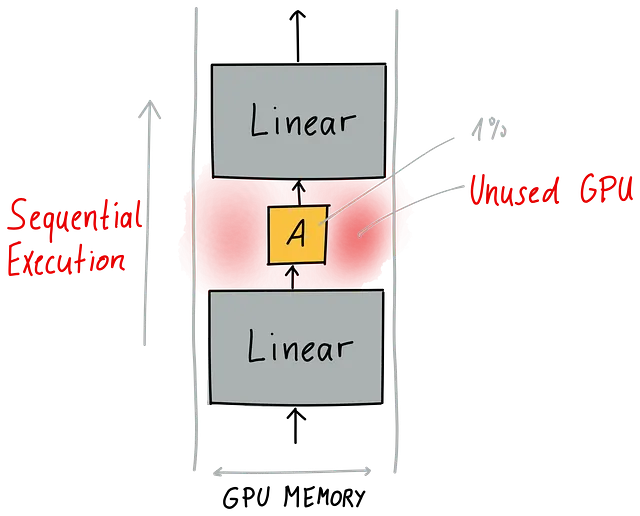
しかし、大きな線形レイヤーの後に非常に小さなアダプタを挿入すると、問題が発生します。以下のイラストで見られるように、メモリ使用が非効率になります。
バッチサイズは線形レイヤーの幅に合っていますが、非常に小さなアダプタがあるため、ほとんどのGPUは小さなアダプタの実行を待たなければなりません。これにより、GPUの利用率が低下します。また、イラストでは、アダプタの面積は実際のダイアグラムでは1%程度であるはずなのに、20%程度に見えます。
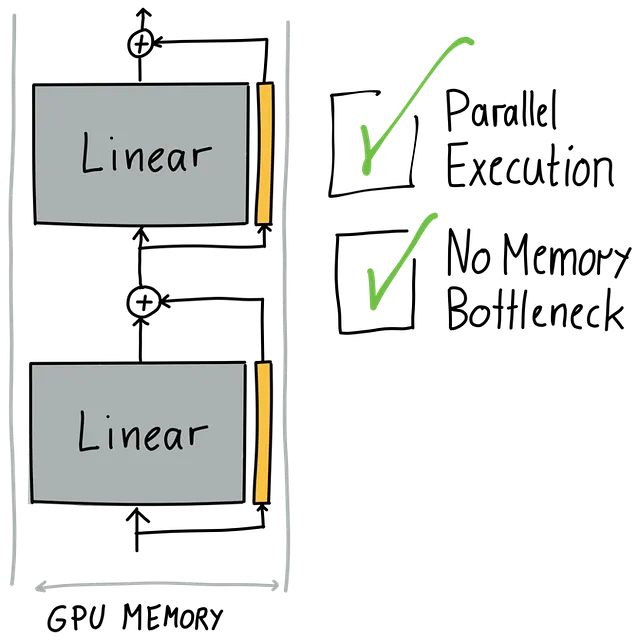
これに対処する一つの方法は、適応を並列化し、両方のパスを出力に寄与させるために加算で接続することです。これにより、メモリボトルネックがなくなり、元の線形モジュールとアダプタを並列に実行し、以前に見たギャップを回避することができます。
ただし、並列実行でも、全くアダプターがない場合と比べて負荷は増えます。トレーニングにおいてはそのようなことが当てはまりますが、推論においても同様です。これは理想的ではありません。また、そのようなアダプターはどのくらいの大きさであるべきでしょうか?
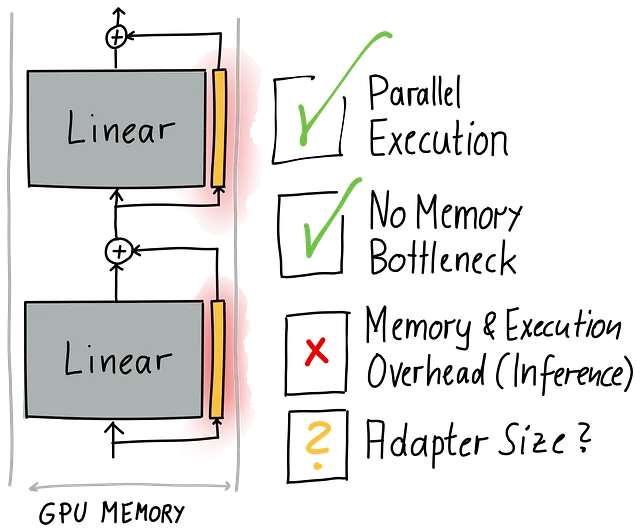
推論時の非効率性については、第3の記事で取り扱います。ちょっとだけネタバレをすると、大丈夫です。モジュールの重みと低ランク行列の積をマージします。この記事に戻りましょう。アダプターのサイズに取り組みましょう。
アダプターとしての低ランク行列
詳しく見てみましょう。
下の図では、左側がグレーの元の線形モジュールであり、右側がオレンジのアダプターです。互換性を持たせるために、入力と出力の次元が一致している必要があります。つまり、同じ入力で並列に呼び出し、出力を合計することができるようにするためです。これは残差接続を使用するのと同様です。したがって、両側の入力と出力の次元は一致する必要があります。
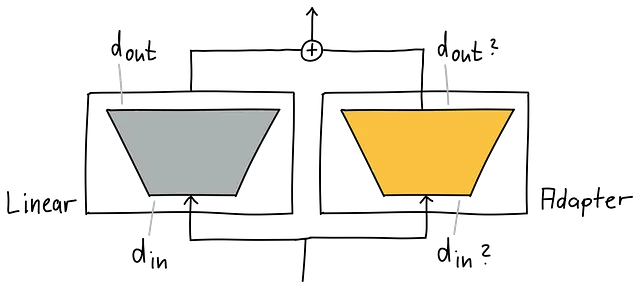
線形モジュールとアダプターは、2つの行列に変換されます。そして、対応する次元があるため、機械的に、現在互換性があります。しかし、アダプターはアダプトするモジュールと同じくらい大きいため、効率的になりませんでした。私たちには、小さくて互換性のあるアダプターが必要です。
2つの低ランク行列の積は、要件に合っています:
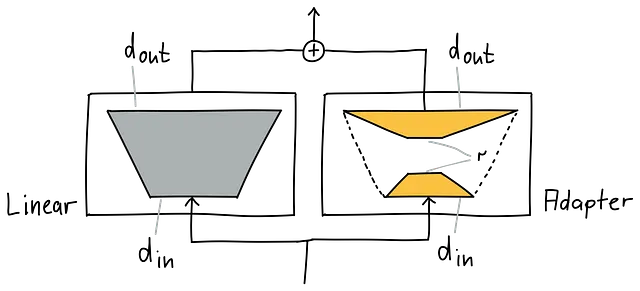
大きな行列は2つの低ランク行列に分解されます。しかし、行列自体ははるかに小さく、d_in x rとr x d_outです。特にrはd_inやd_outよりもはるかに小さいです。通常、rは1、2、4、16などの数字で、d_inやd_outは768、1024、3072、4096のような数字です。
これをまとめましょう:
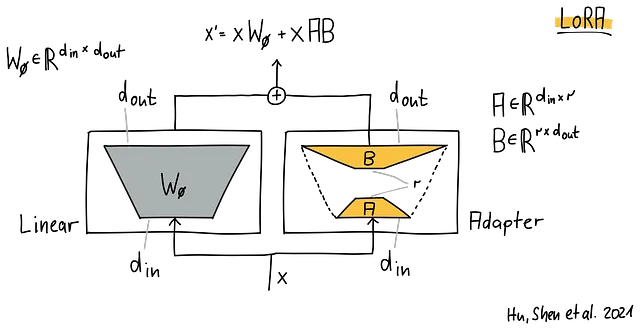
単一のxが入力として表示されます。xは元の重みW0と乗算されます。ここでW0は事前学習された重みです。xはAとBと乗算され、最終的に両方の結果が加算され、調整された出力であるx'が形成されます。
さまざまなアダプターの実装方法がありますが、LoRAではこれを最適化問題にし、2つの低ランク行列AとBは特定の下流タスクに対して学習されます。これらの少ないパラメータを学習する方が、W0のすべてのパラメータを学習するよりも効率的です。
初期化
ちょっと脇道にそれましょう。AとBをどのように初期化するか考えてみましょう。ランダムに初期化する場合、トレーニングの初めに何が起こるか考えてみてください。
各フォワードパスで、適応モジュールの出力にランダムノイズが追加され、オプティマイザが間違った初期化を少しずつ修正するのを待たなければなりません。それにより、ファインチューニングの初めに不安定性が生じます。
これを緩和するために、通常、学習率を下げたり、初期化値を小さくしたり、間違ったパラメーターの影響を制限するためにウォームアップ期間を設けたりします。例えば、LLAMAアダプター[3]の論文では、著者たちはゼロゲーティングを導入しています。アダプターのゲートの値(実際の重みと乗算される)を0から始め、トレーニングの過程でその値を増加させます。
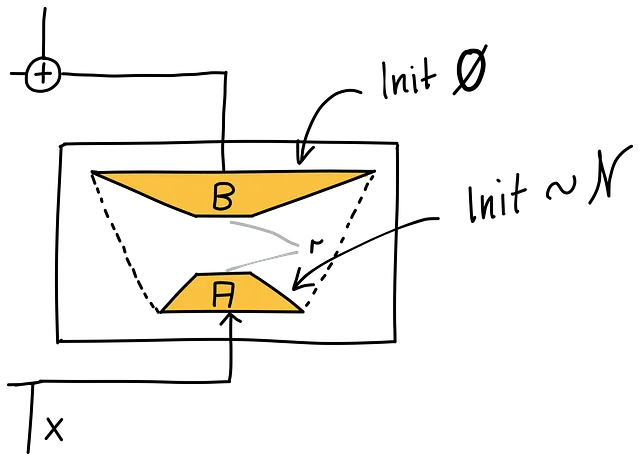
別のアプローチとして、AとBを0で初期化する方法があります。しかし、その場合は対称性を破ることができず、学習プロセスではすべてのパラメーターが1つのパラメーターとして扱われる可能性があります。
LoRAが実際に行っていることは非常に優れています。1つの行列Aをランダムに初期化し、もう1つの行列Bを0で初期化します。したがって、2つの行列の積は0ですが、バックプロパゲーションの過程で各パラメーターを個別に微分することができます。0から始めることは、帰納的なバイアスが何もしないことであり、重みを変更して損失の減少につながるまで何もしないということを意味します。そのため、トレーニングの初めには不安定性はありません。素晴らしいですね!
コードでどのように見えるか?
わかりやすい例のために、いくつかのコード抜粋をチェックしてみましょう。完全なコードは付属のノートブックにあり、以下の記事で使用するより完全な実装は同じリポジトリにあります。
まず、アダプターのセットアップ方法から始めましょう。アダプティブ化するモジュールへの参照を渡し、それをadapteeと呼ぶことにします。元のforwardメソッドへの参照を保存し、adapteeのforwardメソッドをアダプターのforwardメソッドの実装に指すようにします。
class LoRAAdapter(nn.Module): def __init__(self, adaptee, # <- アダプティブ化するモジュール r): super().__init__() self.r = r self.adaptee = adaptee # アダプティブ化するモジュールの元のforward実装へのポインタを保存します。 # そして、そのforwardメソッドをこのアダプターモジュールに指すようにします。 self.orig_forward = adaptee.forward adaptee.forward = self.forward [..]統合の仕組みを設定したので、低ランク行列のパラメーターも初期化します。0で1つの行列を初期化し、もう1つはランダムに初期化することに注意してください。
[..] # 重み行列を直接アダプティブ化するモジュールに追加します。 # パラメーターを報告するのにも、後で削除するのにも、より実用的です。 adaptee.lora_A = (nn.Parameter(torch.randn(adaptee.in_features, r)/ math.sqrt(adaptee.in_features))) adaptee.lora_B = nn.Parameter(torch.zeros(r, adaptee.out_features))そして最後に、LoRAAdapterクラスの一部として、forwardメソッドがあります。このメソッドでは、最初に入力xを使ってadapteeのforwardメソッドを呼び出します。これは元のモジュールで実行される元のパスです。しかし、その結果に、入力xをAとBで行列積することで得られたものを追加します。
def forward(self, x, *args, **kwargs): return ( self.orig_forward(x, *args, **kwargs) + x @ self.adaptee.lora_A @ self.adaptee.lora_B )このシンプルさは目に優れています。
興味深い詳細は他にもありますが、コードと一緒に説明するのが最もわかりやすいです。これらは付属のノートブックで見つけることができます:
- モデル全体を最初にフリーズする方法
- その後、分類器をアンフリーズする方法。これは私たちのダウンストリームタスクに特化しており、完全にトレーニングします。
- アダプターを追加する方法。すべてアクティブでフリーズされていません。
- モジュールの行列の次元が2つの低ランク行列
AとBと関連しているかを確認する方法。 - 小さな値
rを使用した場合、パラメーターの数はどれくらい減少しますか?
下記は元のモジュールoutput.denseのパラメータがトレーニングされていないことを示す小さな抜粋です(0でマークされています)。ただし、そのLoRA行列はトレーニング可能です(1でマークされています)。もちろん、モデルの全体的な分類器もトレーニング可能です(1でマークされています):
[..]roberta.encoder.layer.11.attention.output.LayerNorm.bias 0 768roberta.encoder.layer.11.intermediate.dense.weight 0 2359296roberta.encoder.layer.11.intermediate.dense.bias 0 3072roberta.encoder.layer.11.output.dense.weight 0 2359296roberta.encoder.layer.11.output.dense.bias 0 768roberta.encoder.layer.11.output.dense.lora_A 1 12288roberta.encoder.layer.11.output.dense.lora_B 1 3072roberta.encoder.layer.11.output.LayerNorm.weight 0 768roberta.encoder.layer.11.output.LayerNorm.bias 0 768classifier.dense.weight 1 589824classifier.dense.bias 1 768classifier.out_proj.weight 1 1536classifier.out_proj.bias 1 2[..]総パラメータ数:124,978,946、そのうち学習可能なパラメータ数:923,906(0.7392%)詳細についてはノートブックをご覧ください。
試してみましょうか?
さらに、ノートブックには、セットアップ全体が機械的に動作することを示すいくつかのテストがあります。
しかし、最初の実験を実行し、Training JobsをSageMakerに送信します。元のモデルに対して完全なファインチューニングを行い、ここで説明したようにLoRAを有効にしてトレーニングを行います。
テストでは、すべてのレイヤーのqueryとoutputパラメータを適応させ、r=2でsst-2データセット[5]上でRoBERTa Large [4]をトレーニングします。完全なファインチューニングとLoRAファインチューニングの学習率には5e-5および4e-4を使用します。
結果は次の通りです(ノートブックには詳細があります):
完全なファインチューニングの正解率:0.944LoRAファインチューニングの正解率:0.933これは…素晴らしいですね、あまり素晴らしくありませんね?何でしょうか?まず、これはセットアップ全体が機械的に動作することを明確に示しています。これは素晴らしいことです。そして90%以上の正解率は、うまく機能していることを示しています。
しかし、どれくらいうまく機能しているのでしょうか?これらの数字を何と比較すればよいのでしょうか?また、これらの2つの個別のトレーニングランはどれくらい代表的なのでしょうか?単なる幸運なのか不運なのか?LoRAの数字は従来のアプローチよりも良いのですか?それは奇妙ではありませんか。従来のアプローチをどれくらい調整しましたか?
上記の結果はいずれも信頼性がありません。2回目の実行で私たちのハイパーパラメータを使用して同様の結果が得られるかどうかはわかりません。また、私たちは半教育的な推測で選択されたハイパーパラメータを使用しました。
もちろん、もっと良い方法があります。したがって、次の記事では、ハイパーパラメータの選択により真剣に取り組み、パフォーマンスをより体系的に評価する方法を適用します:
- 比較のためのベースラインの確立
- ベースラインと実験のための適切なハイパーパラメータの探索
- 最も重要なことは:LoRAメソッドとデザイン上の決定の影響についての理解を深め、直感をデータ駆動の方法に整える
それまで、この記事を読んで楽しんでいただければ幸いです。
この記事の執筆中に、コンスタンチン・ゴンザレス、ウミト・ヨルダス、ヴァレリオ・ペローネ、エリナ・レシュクによる貴重なフィードバックをいただきました。ありがとうございました。
すべての画像は、特記されていない限り、著者によるものです。
[1] Armen Aghajanyan, Luke Zettlemoyer, Sonal Gupta. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, 2020
[2] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models, 2021
[3] Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Yu Qiao. LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention, 2023
[4] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. RoBERTa:頑健なBERT事前学習アプローチ、2019
[5] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. センチメントツリーバンクにおける意味的合成性のための再帰的深層モデル、2013
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Q-学習を用いたダイナミックプライシングのための強化学習」
- メタAIは、SeamlessM4Tを発表しましたこれは、音声とテキストの両方でシームレスに翻訳と転写を行うための基盤となる多言語・マルチタスクモデルです
- 「TADAをご紹介します 口述された説明を表現豊かな3Dアバターに変換するための強力なAI手法」
- このAI論文は、「MATLABER:マテリアルを意識したテキストから3D生成のための新しい潜在的BRDFオートエンコーダ」を提案しています
- モンテカルロ近似法:どれを選び、いつ選ぶべきか?
- 「ジェネラティブAIおよびMLモデルを使用したメールおよびモバイル件名の最適化」
- 「AIの問題を定義する方法」






