LLMOps:ハミルトンとのプロダクションプロンプトエンジニアリングパターン
LLMOps Production Prompt Engineering Pattern with Hamilton
ハミルトンを使ったプロンプトのプロダクショングレードのイテレーション方法の概要

大規模言語モデル(LLM)に送信する内容は非常に重要です。細かな変化や変更が出力に大きな影響を与えるため、製品が進化するにつれて、プロンプトも進化する必要があります。LLMは常に開発・リリースされているため、LLMが変わるとプロンプトも変更する必要があります。そのため、プロンプトを「展開」するためのイテレーションパターンを設定することは重要です。そうすることで、効率的に移動できるだけでなく、プロダクションの問題が最小限に抑えられるか、回避されるようになります。この記事では、オープンソースのマイクロオーケストレーションフレームワークであるハミルトンを使用して、プロンプトの管理のベストプラクティスをガイドします。それに伴い、MLOpsパターンにアナロジーを当てはめ、トレードオフについても議論します。この記事の要点は、Hamiltonを使用しない場合でも適用可能です。
始める前にいくつかの注意事項:
- 私はHamiltonの共同創設者の一人です。
- Hamiltonについて詳しく知らない場合は、リンクを最後までスクロールしてください。
- 「コンテキスト管理」について話す記事を探している場合は、この記事ではありません。ただし、本記事は、プロンプトのイテレーションとプロダクショングレードの「プロンプトコンテキスト管理」ストーリーの具体的な手法についてお手伝いします。
- 「プロンプト」と「プロンプトテンプレート」は同じ意味で使用します。
- これらのプロンプトが使用されるのは「オンライン」のウェブサービス設定を想定しています。
- HamiltonのPDF要約機能の例を使用して、パターンを説明します。
- 私たちの信頼性は何ですか? Stitch Fixの100人以上のデータサイエンティスト向けにセルフサービスのデータ/MLOpsツールを開発するキャリアを歩んできたため、時間の経過とともに多くの障害とアプローチを目にしてきました。
プロンプトはLLMにとってハイパーパラメータがMLモデルにとっての役割を果たします
ポイント:プロンプト+LLM APIは、ハイパーパラメータ+機械学習モデルに対応します。
「Ops」の実践において、LLMOpsはまだ初歩的な段階にあります。MLOpsは少し前から存在していますが、まだ広く採用されているわけではなく、DevOpsの実践が広く知られているレベルと比較すると、知識が普及しているとは言えません。
DevOpsの実践は主に、コードをプロダクションに出荷する方法に関係しており、MLOpsの実践はコードとデータアーティファクト(統計モデルなど)をプロダクションに出荷する方法に関係しています。では、LLMOpsはどうでしょうか?個人的には、LLMのワークフローは単純にコードであり、LLM APIはプロンプトを使用して「調整」することができるデータアーティファクトであり、これは機械学習(ML)モデルとそのハイパーパラメータに似ています。
したがって、プロダクションのベストプラクティスにおいて、LLM API + プロンプトを緊密にバージョニングすることが重要です。たとえば、MLOpsの実践では、ハイパーパラメータが変更されたときにMLモデルが正しく動作し続けることを検証するためのプロセスが必要です。
プロンプトのオペレーショナライズについてどのように考えるべきですか?
はっきりさせるために、コントロールする必要があるのはLLMとプロンプトの2つの部分です。MLOpsと同様に、コードまたはモデルアーティファクトが変更された場合、どちらが変更されたかを判断できるようにしたいと思います。LLMOpsでは、LLMのワークフローとLLM API + プロンプトを分離して考えることが重要です。重要な点として、LLM(セルフホストまたはAPI)はほとんど静的であると考えるべきです。なぜなら、内部を頻繁に更新(または制御)することは少ないからです。したがって、LLM API + プロンプトの一部であるプロンプトを変更することは、新しいモデルアーティファクトを作成するのと同じ効果があります。
プロンプトの処理方法には、2つの主要な方法があります:
- プロンプトを動的な実行時変数として処理する。使用されるテンプレートは、デプロイメントに対して静的ではありません。
- プロンプトをコードとして処理する。プロンプトテンプレートは、デプロイメントに対して静的/予め決められたものです。
主な違いは、優れたプロダクションストーリーを確保するために管理する必要のある動く部品の量です。以下では、これら2つのアプローチのコンテキストでHamiltonの使用方法について詳しく説明します。
プロンプトを動的な実行時変数として処理する
プロンプトの動的なパス/ロード
プロンプトはただの文字列です。文字列はほとんどの言語でプリミティブな型ですので、非常に簡単に渡すことができます。アイデアは、コードを抽象化して、実行時に必要なプロンプトを渡すことです。具体的には、新しい「更新された」プロンプトがある場合には、プロンプトテンプレートを「ロード/再ロード」することです。
ここでのMLOpsの類似性は、新しいモデルが利用可能になるたびに、MLモデルアーティファクト(例:pklファイル)を自動で再ロードすることです。

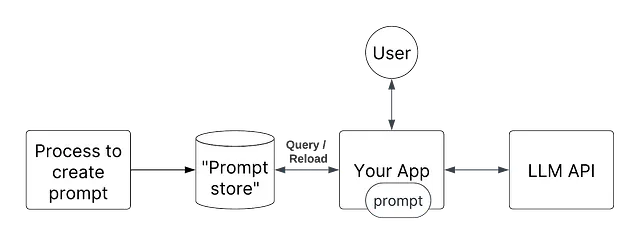
ここでの利点は、アプリケーションを再デプロイする必要がないため、非常に迅速に新しいプロンプトを展開できることです!
ただし、この反復速度の欠点は、運用の負荷が増加することです:
- アプリケーションを監視している人にとって、変更がいつ発生したのか、それがシステム全体に反映されたのかがわかりません。たとえば、新しいプロンプトを追加したばかりで、LLMがリクエストごとにより多くのトークンを返すようになり、レイテンシが急増する場合、監視している人は混乱するでしょう。素晴らしい変更ログの文化がある場合を除いては。
- ロールバックのセマンティクスには、別のシステムについて知っている必要があります。問題を修正するために、前のデプロイメントを単にロールバックすることはできません。
- 実行された内容とそのタイミングを理解するために、優れたモニタリングが必要です。たとえば、顧客サービスから調査のためのチケットを受け取った場合、どのプロンプトが使用されていたのかをどのように知ることができますか?
- プロンプトの管理と保存に使用するシステムを管理および監視する必要があります。これは、コードを提供するものの外部でメンテナンスする必要のある追加のシステムです。
- サービスを更新してプッシュするためのプロセスと、プロンプトを更新してプッシュするためのプロセスの2つを管理する必要があります。これらの変更を同期することはあなた次第です。たとえば、新しいプロンプトを処理するためにコードを変更する必要があります。それを動作させるために2つのシステムの変更を調整する必要があります。これは、管理するための追加の運用上のオーバーヘッドです。
Hamiltonとの連携方法
PDFの要約フローは、summarize_text_from_summaries_promptとsummarize_chunk_of_text_prompt関数の定義を削除した場合、次のようになります:
操作するためには、リクエスト時にプロンプトを注入するか、
from hamilton import base, driver
import summarization_shortend
# ドライバーを作成する
dr = (
driver.Builder()
.with_modules(summarization_sortened)
.build()
)
# どこかからプロンプトを取得する
summarize_chunk_of_text_prompt = """{chunked_text}のためのプロンプト"""
summarize_text_from_summaries_prompt = """プロンプト {summarized_chunks} ... {user_query}"""
# 実行し、プロンプトを渡す
result = dr.execute(
["summarized_text"],
inputs={
"summarize_chunk_of_text_prompt": summarize_chunk_of_text_prompt,
...
}
)
または、コードを変更してプロンプトを動的に読み込むようにすることもできます。つまり、Hamiltonのデータフローの一部として、外部システムからプロンプトを取得するための関数を追加します。各呼び出しでは、使用するプロンプトをクエリすることになります(パフォーマンスのためにキャッシュすることもできます)。
# prompt_template_loaders.py
def summarize_chunk_of_text_prompt(db_client: Client, other_args: str) -> str:
# ここに疑似コードがありますが、アイデアがわかります
_prompt = db_client.query("DBから最新のプロンプトXを取得", other_args)
return _prompt
def summarize_text_from_summaries_prompt(db_client: Client, another_arg: str) -> str:
# ここに疑似コードがありますが、アイデアがわかります
_prompt = db_client.query("DBから最新のプロンプトYを取得", another_arg)
return _prompt
ドライバーコード:
from hamilton import base, driver
import prompt_template_loaders # <-- プロンプト入力を提供するためにこれをロード
import summarization_shortend
# ドライバーを作成する
dr = (
driver.Builder()
.with_modules(
prompt_template_loaders, # <-- Hamiltonが上記の関数を呼び出す
summarization_sortened,
)
.build()
)
# 実行し、プロンプトを渡す
result = dr.execute(
["summarized_text"],
inputs={
# このバージョンではプロンプトを渡す必要はありません
}
)
プロンプトの使用状況のログ記録とフローのモニタリング方法
以下では、いくつかのモニタリング方法を説明します。
- 実行結果をログに記録します。Hamiltonを実行し、情報を任意の場所に送信します。
result = dr.execute(
["summarized_text", "summarize_chunk_of_text_prompt", ... # 抽出する他のもの
"summarize_text_from_summaries_prompt"],
inputs={
# このバージョンではプロンプトを渡す必要はありません
}
)
my_log_system(result) # 任意のシステムに保存するためのデータを送信します
注意: 上記の場合、Hamiltonでは名前で「関数」(すなわち、ダイアグラムのノード)を要求することで、任意の中間出力をリクエストすることができます。データフロー全体のすべての中間出力を取得したい場合は、それを行い、ログを任意の場所に記録することができます。
- Hamiltonの関数内にロガーを使用します(このアプローチの強力さについては、構造化ログに関する私の以前のトークを参照してください)。
import logging
logger = logging.getLogger(__name__)
def summarize_text_from_summaries_prompt(db_client: Client, another_arg: str) -> str:
# ここに疑似コードがありますが、アイデアがわかります
_prompt = db_client.query("DBから最新のプロンプトYを取得", another_arg)
logger.info(f"使用されるプロンプトは [{_prompt}] です")
return _prompt
- Hamiltonを拡張してこの情報を出力します。Hamiltonを使用して、関数(つまり、ノード)が実行されたときに関数内にログステートメントを挿入する必要はありません。これにより、開発とプロダクションの設定でロギングを切り替えることができるため、再利用性が向上します。GraphAdaptersを参照するか、モニタリングのために関数をラップするための独自のPythonデコレータを作成します。
上記のいずれのコードでも、サードパーティのツールを容易に組み込んでコードと外部API呼び出しを追跡および監視することができます。
プロンプトをコードとして扱う
静的な文字列としてのプロンプト
プロンプトは単なる文字列であるため、ソースコードと一緒に保存することもできます。アイデアは、実行時に使用可能なプロンプトのセットが固定されて決定論的であるため、コード内に複数のプロンプトバージョンを保存することです。
ここでのMLOpsの類似性は、モデルを動的にリロードする代わりに、MLモデルをコンテナに埋め込む/参照をハードコードするということです。デプロイされた後、アプリには必要なすべてが備わっています。デプロイメントは不変であり、一度立ち上がると何も変わりません。これにより、デバッグや何が起こっているのかを確認することがはるかに簡単になります。

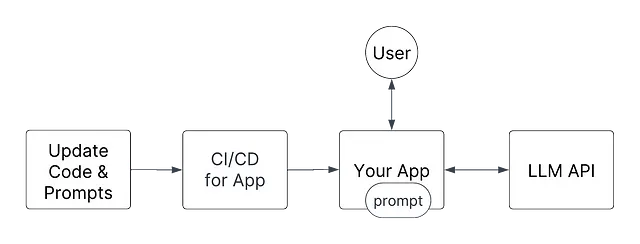
このアプローチには多くの運用上の利点があります:
- 新しいプロンプトがプッシュされるたびに、新しいデプロイメントが強制されます。新しいプロンプトに問題がある場合、ロールバックのセマンティクスが明確になります。
- ソースコードとプロンプトの両方に対してプルリクエスト(PR)を提出することができます。変更内容と、これらのプロンプトがどのように影響し、どのように対話するかのダウンストリームの依存関係を確認することが簡単になります。
- CI/CDシステムにチェックを追加して、不良なプロンプトが本番環境に反映されないようにすることができます。
- 問題をデバッグするのが簡単です。作成された(Docker)コンテナを取得するだけで、顧客の問題を迅速かつ簡単に再現できます。
- メンテナンスや管理する他の「プロンプトシステム」はありません。運用を簡素化します。
- 追加のモニタリングと可視性を追加することもできます。
Hamiltonとの連携方法
プロンプトはデータフロー/有向非巡回グラフ(DAG)に関数としてエンコードされます:
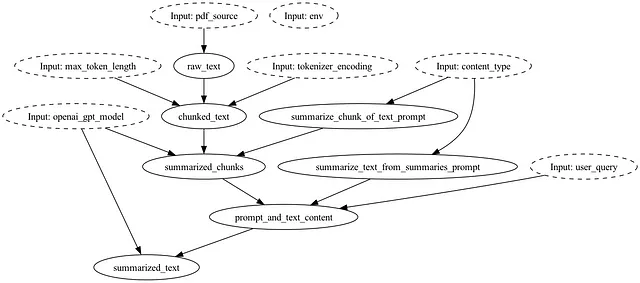
このコードをgitと組み合わせることで、データフロー(つまり「チェーン」)全体の軽量なバージョン管理システムを持つことができますので、gitのコミットSHAが与えられた場合に世界がどの状態にあったかを常に識別することができます。任意の時点で複数のプロンプトを管理し、アクセスするための2つの強力な抽象化機能をHamiltonは提供しています:@config.whenとPythonモジュール。これにより、古いプロンプトバージョンをすべて保存し、コードを介して使用するバージョンを指定することができます。
@config.when(ドキュメント)
Hamiltonには、関数に対する注釈であるデコレータの概念があります。 @config.whenデコレータは、データフロー内の関数、つまり「ノード」の代替実装を指定することができます。この場合、代替プロンプトを指定します。
from hamilton.function_modifiers import [email protected](version="v1")def summarize_chunk_of_text_prompt__v1() -> str: """テキストのチャンクを要約するためのV1プロンプト。""" return f"このテキストを要約してください。推論とともにキーポイントを抽出してください。\n\nコンテンツ:"@config.when(version="v2")def summarize_chunk_of_text_prompt__v2(content_type: str = "an academic paper") -> str: """テキストのチャンクを要約するためのV2プロンプト。""" return f"このテキストを{content_type}から要約してください。推論とともにキーポイントを抽出してください。\n\nコンテンツ:"@config.whenで注釈が付けられた関数を追加し続けることができるため、Hamilton Driverに渡された構成値に関連付けられたプロンプトの実装を使用して、それらの間を切り替えることができます。 Driverをインスタンス化する際に、構成値に関連付けられたプロンプトの実装を使用してデータフローが構築されます。
from hamilton import base, driver
import summarization
# ドライバを作成
dr = (
driver.Builder()
.with_modules(summarization)
.with_config({"version": "v1"}) # V1を選択します。V2を使用する場合は "v2" を使用してください。
.build()
)
モジュールの切り替え
@config.whenを使用する代わりに、異なるプロンプトの実装を異なるPythonモジュールに配置することもできます。そして、Driverの構築時に、使用したいコンテキストに応じた正しいモジュールを渡します。
ここでは、V1のプロンプトが1つのモジュールに収められています:
# prompts_v1.py
def summarize_chunk_of_text_prompt() -> str:
"""テキストのチャンクを要約するためのV1のプロンプト。"""
return f"このテキストを要約してください。理由とともにキーポイントを抽出してください。\n\n内容:"
ここでは、V2が1つのモジュールに収められています(わずかに異なる点に注目してください):
# prompts_v2.py
def summarize_chunk_of_text_prompt(content_type: str = "an academic paper") -> str:
"""テキストのチャンクを要約するためのV2のプロンプト。"""
return f"{content_type}からこのテキストを要約してください。理由とともにキーポイントを抽出してください。\n\n内容:"
以下のドライバコードでは、いくつかのコンテキストに基づいて使用する正しいモジュールを選択します。
# run.py
from hamilton import driver
import summarization
import prompts_v1
import prompts_v2
# 正しいモジュールを渡してドライバを作成します。
dr = (
driver.Builder()
.with_modules(
prompts_v1, # または prompts_v2
summarization,
)
.build()
)
モジュールのアプローチを使用すると、プロンプトのセットを一括でカプセル化してバージョン管理することができます。コードの過去のバージョン(gitを使用して)を確認したり、正式なプロンプトバージョンを確認する場合は、適切なコミットに移動して適切なモジュールを確認するだけで済みます。
どのようにして使用されたプロンプトをログに記録し、フローを監視しますか?
コードを追跡するためにgitを使用している場合、使用されているプロンプトを記録する必要はありません。代わりに、デプロイされているgitのコミットSHAを知っていれば、コードとプロンプトのバージョンを同時に追跡できます。
フローを監視する場合も、上記の方法と同様に、利用可能なモニタリングフックがあります。ここでは繰り返しませんが、以下の方法があります:
- Hamiltonの外部で中間出力をリクエストし、自分でログに記録します。
- 関数内部からログに記録するか、フレームワークレベルで行うためのPythonデコレータ/GraphAdapterを作成します。
- コードとLLM APIの呼び出しを監視するためのサードパーティツールを統合します。
- または、上記すべてを使用します!
プロンプトのA/Bテストはどうですか?
MLの取り組みにおいては、変更のビジネスへの影響を測定することが重要です。同様に、LLM + プロンプトでも、重要なビジネスメトリクスに対して変更をテストし、測定することが重要になります。MLOpsの世界では、トラフィックを分割してビジネス価値を評価するために、MLモデルのA/Bテストを行います。A/Bテストに必要なランダム性を確保するために、ランタイムでどのモデルを使用するかはコインを投げるまでわかりません。ただし、それらのモデルを取り出すには、それぞれに基準を満たすためのプロセスが必要です。プロンプトの場合も同様に考える必要があります。
上記の2つのプロンプトエンジニアリングパターンは、プロンプトのA/Bテストを行うことを妨げるものではありませんが、テスト中の複数のプロンプトを並列にテストするために、テスト中のプロンプトテンプレートの数に応じてプロセスを管理する必要があります。コードパスも調整している場合は、コード内にそれらを配置することで、何が起こっているかを判断しデバッグするのが簡単になります。また、この目的のために@config.whenデコレータ/Pythonモジュールの切り替えを利用することもできます。一方、動的にロード/パスインしてから使用されたプロンプトをログ/監視/可視化スタックに依存することになると、どのプロンプトがどのコードパスに対応するかを心理的にマッピングする必要があります。
複数のプロンプトをA/Bテストする場合、2つのプロンプトがフロー内にある場合など、すべてのものを個別にテストするのではなく、変更を包括的にA/Bテストしたい場合は、プロンプトをコードに配置することで運用が簡単になります。なぜなら、どのコードパスに2つのプロンプトが属しているかを心理的なマッピングなしで把握できるからです。
注意:複数のプロンプトをA/Bテストする場合は、フローに複数のプロンプトがあるため、複雑になります。たとえば、ワークフローに2つのプロンプトがあり、LLMsを変更している場合、プロンプトごとに個別にA/Bテストするのではなく、変更を包括的にA/Bテストしたい場合があります。私たちのアドバイスは、プロンプトをコードに配置することで、運用が簡単になるということです。なぜなら、どのコードパスに2つのプロンプトが属しているかを心理的なマッピングなしで把握できるからです。
概要
この記事では、Hamiltonを使用して本番環境でプロンプトを管理するための2つのパターンを説明しました。最初のアプローチでは、プロンプトを動的なランタイム変数として扱います。二番目のアプローチでは、プロンプトをプロダクション設定のコードとして扱います。運用の負担を軽減することを重視する場合は、プロンプトをコードとしてエンコードすることをお勧めします。ただし、変更速度が重要な場合を除きます。
要約すると:
- プロンプトを動的なランタイム変数として扱う。外部システムを使用してプロンプトをHamiltonのデータフローに渡すか、Hamiltonを使用してデータベースから取得します。デバッグやモニタリングでは、特定の呼び出しに使用されたプロンプトを判別できることが重要です。オープンソースのツールを統合するか、DAGWorksプラットフォームのようなものを使用して、コードの呼び出しに使用された内容を知ることができます。
- プロンプトをコードとしてエンコードする。プロンプトをコードとしてエンコードすると、gitで簡単にバージョン管理できます。変更管理は、プルリクエストとCI/CDチェックを使用して行うことができます。Hamiltonの
@config.whenやドライバレベルでのモジュール切り替えなどの機能ともうまく連携し、どのバージョンのプロンプトが使用されるかを明確に示します。このアプローチは、DAGWorksプラットフォームなどのモニタリングやトラッキングツールの使用を強化します。
あなたの声を聞かせてください!
これらの内容に興味がある場合や強い意見がある場合は、コメントを残すか、Slackチャンネルに立ち寄ってください!以下は、称賛・クレーム・チャットを行うためのいくつかのリンクです:
- 📣 Slackのコミュニティに参加する – 質問にお答えしたり、開始のお手伝いをするために喜んでお手伝いします。
- ⭐️ GitHubで私たちを評価する。
- 📝 問題が見つかった場合は、問題を報告してください。
- 📚 ドキュメントを読む。
- ⌨️ ブラウザでHamiltonについてインタラクティブに学ぶ。
他のHamiltonのリンク/投稿
- tryhamilton.dev – ブラウザでの対話型チュートリアル!
- Hamilton + Lineage in 10 minutes
- PandasでHamiltonを使用する方法(5分で学ぶ)
- RayでHamiltonを使用する方法(5分で学ぶ)
- ノートブック環境でHamiltonを使用する方法
- Hamiltonに関する一般的な背景と紹介
- Hamiltonでデータフローを作成する利点(Hamiltonに関するユーザーポスト!)
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






