「LLMガイド、パート1:BERT」 LLMガイド、パート1:BERTについてのガイドです
LLM Guide, Part 1 BERT
BERTが最先端の埋め込みを構築する方法を理解する
イントロダクション
2017年は機械学習において歴史的な年であり、Transformerモデルが初めて登場しました。このモデルは多くのベンチマークで驚異的なパフォーマンスを発揮し、データサイエンスの多くの問題に適しています。効率的なアーキテクチャのおかげで、その後もさまざまなタスクに特化したTransformerベースのモデルが開発されてきました。
BERTはそのようなモデルの1つです。主にテキスト情報を非常に正確に表現し、長いテキストシーケンスの意味情報を保存できる埋め込みを構築する能力で知られています。その結果、BERTの埋め込みは機械学習で広く使用されるようになりました。BERTがテキスト表現を構築する方法を理解することは重要です。なぜなら、それによってNLPのさまざまなタスクに取り組むことができるようになるからです。
この記事では、オリジナルのBERT論文を参照し、BERTのアーキテクチャとその背後にある核心メカニズムを理解します。最初のセクションではBERTの概要を高レベルで説明します。その後、内部のワークフローとモデル内で情報がどのように渡されるかについて徐々に詳しく見ていきます。最後に、BERTをNLPの特定の問題を解決するために微調整する方法を学びます。
- 初めてのDeep Q学習ベースの強化学習エージェントをトレーニングする:ステップバイステップガイド
- ディープラーニングのためのPythonとC++による自動微分
- 「このGSAi中国のAI論文は、LLMベースの自律エージェントの包括的な研究を提案しています」
高レベルの概要
Transformerのアーキテクチャは、エンコーダとデコーダの2つの主要な部分で構成されています。スタックされたエンコーダの目標は、入力の意味的なコンテキストを保持する有意義な埋め込みを構築することです。最後のエンコーダの出力は、新しい情報を生成しようとするすべてのデコーダの入力に渡されます。
BERTは、スタックされた双方向エンコーダを継承したTransformerの後継モデルです。BERTのアーキテクチャのほとんどは、オリジナルのTransformerと同じです。
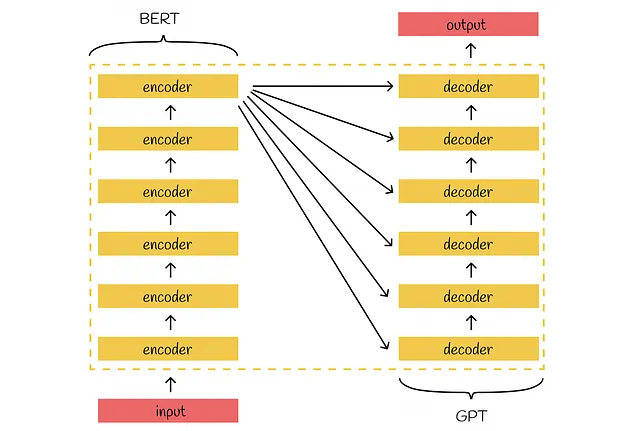
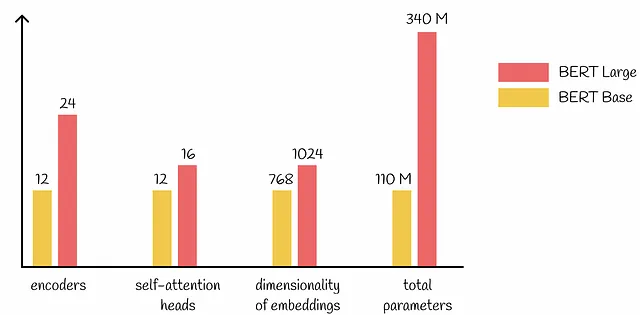
BERTのバージョン
BERTには2つの主要なバージョンが存在します:BaseとLargeです。アーキテクチャは完全に同じであり、パラメータの数だけが異なる点です。全体的に見て、BERT LargeはBERT Baseに比べてパラメータの数が3.09倍多く調整する必要があります。
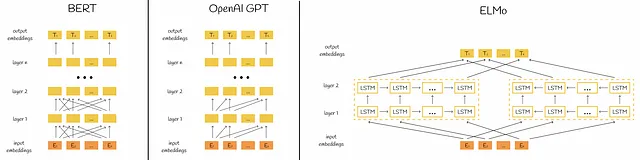
双方向表現
BERTの名前の「B」からわかるように、BERTは双方向モデルであり、情報が両方向(左から右へおよび右から左へ)に渡されるため、単語の関連性をより良く捉えることができます。明らかに、これには単方向モデルに比べてより多くのトレーニングリソースが必要ですが、同時により高い予測精度につながります。
より良い理解のために、BERTのアーキテクチャを他の人気のあるNLPモデルと比較してみましょう。
入力トークン化
BERTのトレーニング方法に入る前に、どのような形式でデータを受け入れるかを理解する必要があります。BERTは、単一の文または2つの文のペアを受け取ります。各文はトークンに分割されます。さらに、2つの特殊なトークンが入力に渡されます:
- [CLS] — 文の最初の前に渡され、シーケンスの開始を示します。同時に、トレーニング中に分類目的にも使用されます(以下のセクションで詳しく説明します)。
- [SEP] — 文の間に渡され、最初の文の終了と2番目の文の開始を示します。
2つの文を渡すことで、BERTは2つの文が含まれる入力を持つさまざまなタスクを処理することが可能になります(例:質問と回答、仮説と前提など)。
入力埋め込み
トークン化後、各トークンに対して埋め込みが構築されます。入力埋め込みをより表現力豊かにするために、BERTは各トークンに対して以下の3つの種類の埋め込みを構築します:
- トークン埋め込みはトークンの意味を捉えます。
- セグメント埋め込みは2つの可能な値のいずれかを持ち、トークンがどの文に属しているかを示します。
- 位置埋め込みはトークンの相対的な位置に関する情報を含みます。
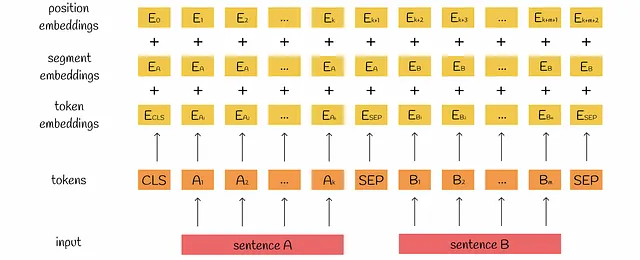
これらの埋め込みは合算され、その結果がBERTモデルの最初のエンコーダに渡されます。
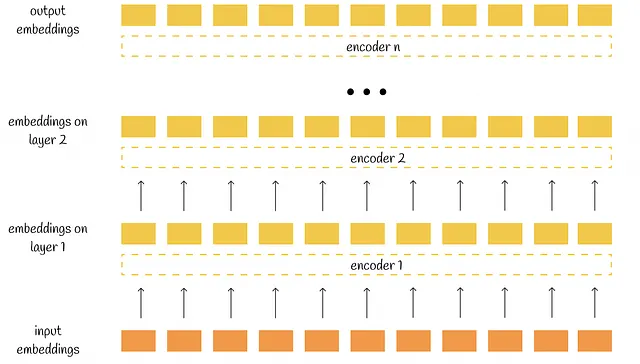
出力
各エンコーダはn個の埋め込みを入力として受け取り、同じ次元の処理された埋め込みの数として出力します。最終的に、BERTの出力全体も、それぞれの初期トークンに対応するn個の埋め込みを含みます。
トレーニング
BERTのトレーニングは2つのステージで構成されます:
- 事前トレーニング。 BERTは、未ラベルの文のペアに対して、2つの予測タスク(マスクされた言語モデリング(MLM)と自然言語推論(NLI))でトレーニングされます。各文のペアに対して、モデルはこれら2つのタスクの予測を行い、損失値に基づいて重みを更新します。
- ファインチューニング。 BERTは、事前トレーニングされた重みで初期化され、その後、ラベル付きデータ上の特定の問題に対して最適化されます。
事前トレーニング
ファインチューニングと比較して、事前トレーニングは通常、モデルが大規模なデータコーパスでトレーニングされるため、かなりの時間を要します。そのため、特定のタスクを解決するために比較的高速にファインチューニングできる事前トレーニング済みモデルのオンラインリポジトリが多数存在します。
事前トレーニングでBERTによって解決される2つの問題を詳しく見ていきます。
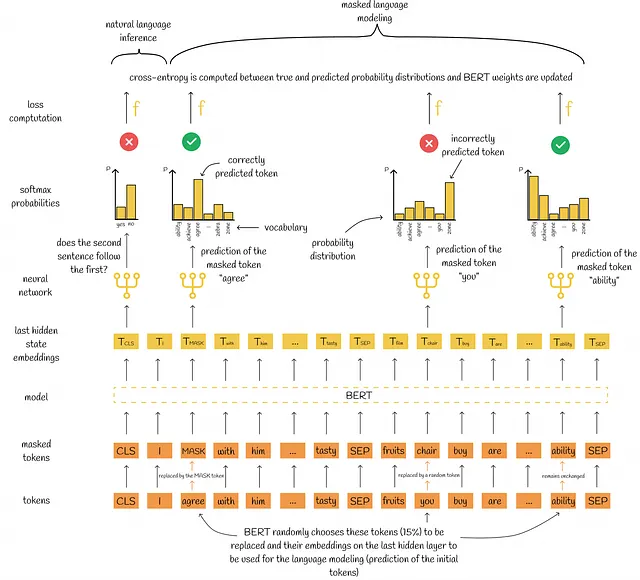
マスクされた言語モデリング
著者は、BERTを、初期テキストの一部のトークンをマスクし、それらを予測することでトレーニングすることを提案しています。これにより、BERTは周囲の文脈を利用して特定の単語を推測するための頑健な埋め込みを構築する能力を持つことができます。このプロセスは次のように行われます:
- トークン化後、トークンの15%がランダムにマスクされます。選択されたトークンはイテレーションの最後に予測されます。
- 選択されたトークンは、次の3つの方法のいずれかで置き換えられます:- トークンの80%は[MASK]トークンで置き換えられます。例:I bought a book → I bought a [MASK]- トークンの10%はランダムなトークンで置き換えられます。例:He is eating a fruit → He is drawing a fruit- トークンの10%は変更されません。例:A house is near me → A house is near me
- すべてのトークンがBERTモデルに渡され、モデルは入力として受け取った各トークンに対して埋め込みを出力します。
4. ステップ2で処理されたトークンに対応する出力埋め込みは、マスクされたトークンを予測するために独立して使用されます。各予測の結果は、語彙内のすべてのトークンにわたる確率分布です。
5. クロスエントロピー損失は、確率分布と正しいマスクされたトークンを比較することで計算されます。
6. モデルの重みはバックプロパゲーションを使用して更新されます。
自然言語推論
この分類タスクでは、BERTは2つ目の文が最初の文に続くかどうかを予測しようとします。予測全体は、両方の文からの情報を集約したとされる[CLS]トークンの最終隠れ状態の埋め込みのみを使用して行われます。
MLMと同様に、構築された確率分布(この場合は2値)は、モデルの損失を計算し、バックプロパゲーションを通じてモデルの重みを更新するために使用されます。
NLI(自然言語推論)において、著者はコーパス内で互いに続く文のペアの50%(正のペア)と、コーパスからランダムに選ばれた文のペアの50%(負のペア)を選ぶことを推奨しています。
トレーニングの詳細
論文によると、BERTはBooksCorpus(800M単語)と英語のWikipedia(2,500M単語)で事前学習されています。より長い連続したテキストを抽出するために、著者はWikipediaからはテーブル、見出し、リストを無視した読み物のみを取りました。
BERTは、256のシーケンスからなる100万のバッチでトレーニングされており、これは33億単語に相当します。各シーケンスには、128(90%の場合)または512(10%の場合)のトークンが含まれています。
元の論文によれば、トレーニングのパラメータは次のとおりです:
- オプティマイザ:Adam(学習率l = 1e-4、重み減衰L₂ = 0.01、β₁ = 0.9、β₂ = 0.999、ε = 1e-6)。
- 学習率のウォームアップは最初の10,000ステップで行われ、その後線形に減少します。
- 全てのレイヤーでDropout(α = 0.1)レイヤーが使用されます。
- 活性化関数:GELU。
- トレーニング損失は、平均MLMと平均次の文予測の尤度の合計です。
ファインチューニング
事前学習が完了すると、BERTは言葉の意味を文字通り理解し、意味をほぼ完全に表現できる埋め込みを構築できます。ファインチューニングの目的は、特定の下流タスクを解決するためにBERTの重みを徐々に修正することです。
データ形式
自己注意機構の堅牢性のおかげで、BERTは特定の下流タスクに簡単にファインチューニングできます。BERTのもう一つの利点は、双方向のテキスト表現を構築できる能力です。これにより、ペアで作業するときに2つの文の間の正しい関係を発見する確率が高くなります。以前のアプローチでは、それぞれの文を独立してエンコードし、双方向のクロスアテンションを適用していました。BERTはこれらの2つのステージを統一します。
特定の問題に応じて、BERTはいくつかの入力形式を受け入れます。BERTを使用してすべての下流タスクを解決するためのフレームワークは同じです:テキストのシーケンスを入力として取り、BERTはそれらに対してトークンの埋め込みのセットを出力し、それがモデルに供給されます。ほとんどの場合、すべての出力埋め込みが使用されるわけではありません。
一般的な問題と、それらがBERTのファインチューニングによってどのように解決されるかを見てみましょう。
文のペア分類
文のペア分類の目的は、与えられた文のペアの関係を理解することです。一般的なタスクの種類は次のとおりです:
- 自然言語推論:2番目の文が1番目の文に続くかどうかを判断する。
- 類似性分析:文の類似度を見つける。
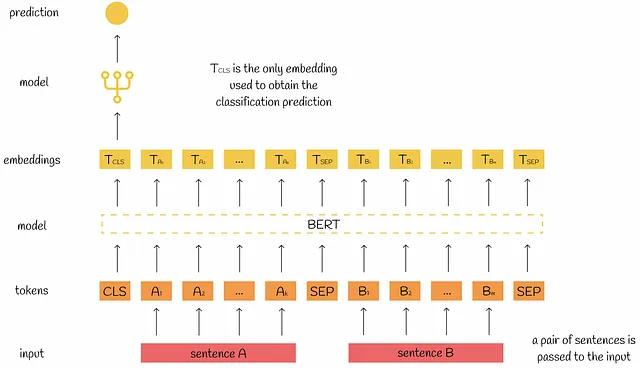
ファインチューニングでは、両方の文がBERTに渡されます。一般的なルールとして、[CLS]トークンの出力埋め込みが分類タスクに使用されます。研究者によれば、[CLS]トークンには文の関係についての主要な情報が含まれているとされています。
もちろん、他の出力埋め込みも使用できますが、通常は省略されます。
質問応答タスク
質問応答の目的は、特定の質問に対応するテキストパラグラフから回答を見つけることです。ほとんどの場合、回答はパッセージの開始と終了トークンの位置として与えられます。
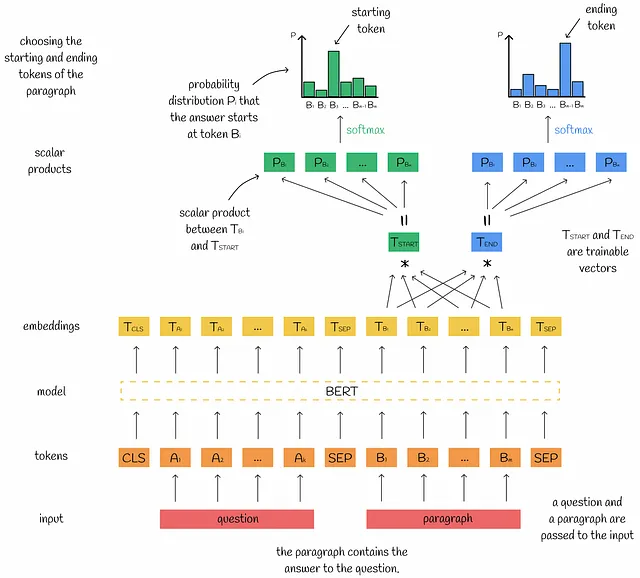
入力に関して、BERTは質問と段落を受け取り、それらのための埋め込みのセットを出力します。答えは段落内に含まれているため、私たちは段落のトークンに対応する出力の埋め込みにのみ興味があります。
答えの開始トークンの位置を見つけるために、すべての出力の埋め込みと特別な学習可能なベクトルTₛₜₐᵣₜとのスカラー積が計算されます。モデルとベクトルTₛₜₐᵣₜが適切にトレーニングされた場合、スカラー積は対応するトークンが実際に開始トークンである可能性に比例するはずです。スカラー積を正規化するために、それらはsoftmax関数に渡され、確率として考えることができます。最も高い確率に対応するトークン埋め込みが開始トークンとして予測されます。真の確率分布に基づいて、損失値が計算され、逆伝播が実行されます。ベクトルTₑₙ𝒹に対しても同様のプロセスが実行され、終了トークンが予測されます。
単文分類
従来の下流タスクと比較して、ここではBERTには単一の文のみが渡されます。この構成で解決される典型的な問題は次のとおりです:
- 感情分析:文がポジティブな態度かネガティブな態度かを理解する。
- トピック分類:内容に基づいて文をいくつかのカテゴリに分類する。
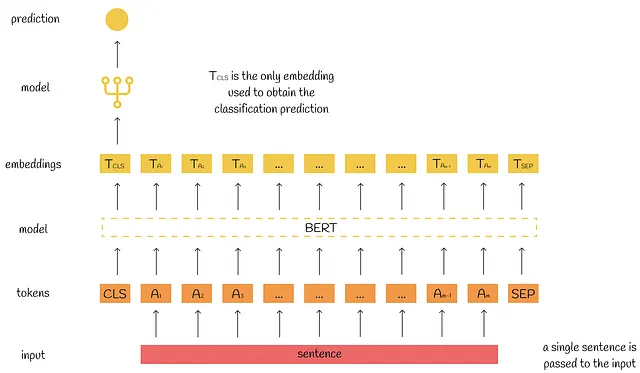
予測のワークフローは文ペア分類と同じです:[CLS] トークンの出力埋め込みが分類モデルの入力として使用されます。
単文タギング
名前付き実体認識(NER)は、シーケンスの各トークンをそれぞれのエンティティの1つにマッピングすることを目指す機械学習の問題です。
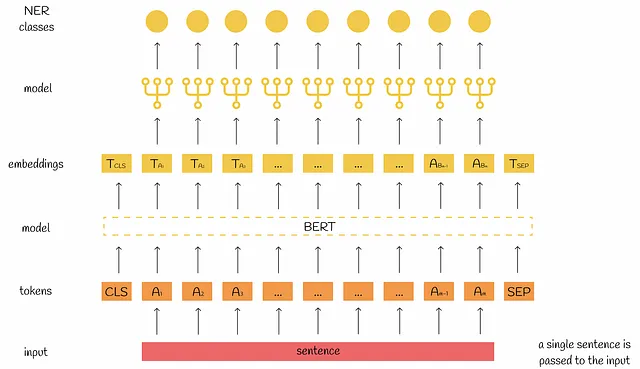
この目的のために、通常のように入力文のトークンの埋め込みが計算されます。その後、[CLS] と [SEP] を除くすべての埋め込みを個別にモデルに渡し、それぞれが与えられたNERクラスにマッピングされます(できない場合はマッピングされません)。
BERTを他の特徴量と組み合わせる
時にはテキストだけでなく数値の特徴量も扱うことがあります。テキストと非テキストの特徴量の両方から情報を組み込むことができる埋め込みを構築することは自然な望みです。以下に適用する推奨される戦略を示します:
- テキストと非テキストの特徴量の連結。たとえば、テキストの形式で人々のプロフィールの説明文で作業し、名前や年齢などの別々の特徴量がある場合、新しいテキストの説明文を以下の形式で取得できます:”私の名前は<name>です。<profile description>。私は<age>歳です”。最後に、このようなテキストの説明文をBERTモデルに入力できます。
- 埋め込みと特徴量の連結。先述の通りBERTの埋め込みを構築し、それらを他の特徴量と連結することも可能です。構成で変更される唯一の点は、下流タスクの分類モデルがより高次元の入力ベクトルを受け入れる必要があるということです。
結論
この記事では、BERTのトレーニングとファインチューニングのプロセスについて詳しく説明しました。実際には、この知識はNLPのほとんどのタスクを解決するのに十分です。なぜなら、BERTはテキストデータをほぼ完全に埋め込みに組み込むことができるからです。
最近では、SBERT、RoBERTaなどの他のBERTベースのモデルが登場しています。BERTの機能を詳細に分析し、新しい高性能モデルを派生させるための「BERTology」という特別な研究分野さえ存在しています。これらの事実は、BERTが機械学習の革命をもたらし、NLPの大幅な進歩を実現することを強化しています。
リソース
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
すべてのイメージは、特に記載がない限り、著者によるものです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






