LLM黙示録:オープンソースクローンの復讐
LLM Apocalypse Revenge of the Open Source Clone

「私たちはあまりにも多くのものにアクセスしていました。あまりにも多くのお金と機器があり、少しずつ、私たちは気が狂っていきました。」
フランシス・フォード・コッポラは、AI企業があまりにも多くのお金を使って道に迷ってしまうことのための比喩をしていたわけではありませんが、そうであったかもしれません。『黙示録 Now』は壮大であると同時に、GPT-4のような長く、困難で高価なプロジェクトでした。LLMの開発は、あまりにも多くのお金と機器に重心を置いていると私は提案します。そして、「私たちは一般的な知能を発明したばかりだ」という煽り文句の一部は、少し狂気じみています。しかし、今度はオープンソースコミュニティが得意とすることを行う番です。彼らは、はるかに少ないお金と機器を使用して無料で競合するソフトウェアを提供することです。
OpenAIは、110億ドル以上の資金を調達し、GPT-3.5のトレーニングランには500万〜600万ドルかかると推定されています。OpenAIはGPT-4について非常に少ない情報しか開示していませんが、GPT-3.5よりも小さくないと安全に想定できます。現在、世界中でGPUの不足が起こっていますが、最新の暗号化通貨ではないため、変化があります。生成的AIスタートアップは、彼らの製品を動力付けるLLMのIPを所有していない場合でも、巨額の評価で1億ドル以上のシリーズAラウンドを獲得しています。LLMのブームは高速であり、お金は流れています。
ダイスが投げられたように見えていました。マイクロソフト/オープンAI、アマゾン、Googleのような深いポケットを持った企業だけが、数千億のパラメーターモデルをトレーニングできる余裕がありました。より大きなモデルは、より良いモデルだと思われていました。GPT-3に何か問題があった場合は、より大きなバージョンがあればすべてうまくいくでしょう!競合するために小規模な企業は、はるかに多くの資本を調達する必要がありました。または、ChatGPTマーケットプレイスで一般的な統合を構築することになりました。さらに制約のある研究予算を持つ学術界は、脇役に甘んじました。
幸いにも、スマートな人々とオープンソースプロジェクトのグループがこれを制限ではなく、挑戦として捉えました。スタンフォード大学の研究者たちは、7億のパラメーターモデルであるアルパカをリリースしました。その性能はGPT-3.5の1750億のパラメーターモデルに匹敵するものでした。OpenAIが使用したような規模のトレーニングセットを構築するためのリソースがなかったため、彼らはよく訓練されたオープンソースLLMのLLaMAを選択し、一連のGPT-3.5プロンプトと出力に対して微調整しました。基本的に、モデルはGPT-3.5が行うことを学びましたが、これはその行動を複製するために非常に効果的な戦略であることがわかりました。
Alpacaは、オープンソースの非商用LLaMAモデルを使用しているため、コードとデータの両方で非商用利用のみにライセンスされています。そして、OpenAIは、彼らのAPIを使用して競合製品を作成することを明示的に禁止しています。これにより、異なるライセンスの可能性があるAlpacaのプロンプトとアウトプットに別のオープンソースLLMを微調整するという魅力的な見通しが生まれます。
ここには、さらに別個の皮肉があります。主要なLLMのすべてが、インターネットで利用可能な著作権のあるテキストと画像でトレーニングされ、著作権者に一銭も支払われなかったという点です。企業は、使用が「変形的」であるという主張で米国の著作権法の「公正使用」例外を主張しています。しかし、彼らが無料のデータで構築したモデルの出力については、彼らは本当に誰も同じことを彼らにしたくありません。私は権利保有者が賢くなると、これが変わると予想しています。そして、いつか裁判になるかもしれません。
これは、制限付きのオープンソースの著者が、CoPilotのようなコードの生成AI製品の生成AIに対して、彼らのコードがライセンスに従って使用されていないという理由で反対することで提起されたものとは別個のポイントです。個々のオープンソースの著者にとって問題なのは、立場(実質的なコピー)を示し、損害を被ったことを示す必要があることです。そして、モデルが出力コードを入力(著者によるソースコードの行)にリンクするのが難しく、経済的な損失がないため(無料であるべきです)、事件を起こすのははるかに困難です。これは、利益を得るクリエーター(写真家など)には当てはまらず、彼らのビジネスモデル全体が彼らの作品をライセンス/販売することにあるため、Getty Imagesのような集約者によって代表される人々によって表現されます。
LLaMAの別の興味深い点は、それがMetaから出てきたことです。最初にリリースされたのは研究者だけであり、その後BitTorrentを通じて世界にリークされました。Metaは、オープンAI、マイクロソフト、Google、Amazonとは根本的に異なるビジネスに取り組んでおり、クラウドサービスやソフトウェアを販売しようとしているわけではありません。そのため、非常に異なるインセンティブを持っています。過去には、そのコンピュートデザインをオープンソース化し(OpenCompute)、コミュニティによって改善されたことがあります。彼らはオープンソースの価値を理解しています。
Metaは、最も重要なオープンソースAI貢献者の1つになる可能性があります。それは膨大なリソースを持っているだけでなく、優れた生成AI技術が普及すれば利益があります。それによって、より多くのコンテンツをソーシャルメディアで収益化することができます。Metaは、他にも3つのオープンソースAIモデルをリリースしています。ImageBind(多次元データインデックス)、DINOv2(コンピュータビジョン)、Segment Anythingです。後者は、画像内のユニークなオブジェクトを識別し、非常に寛容なApacheライセンスの下でリリースされています。
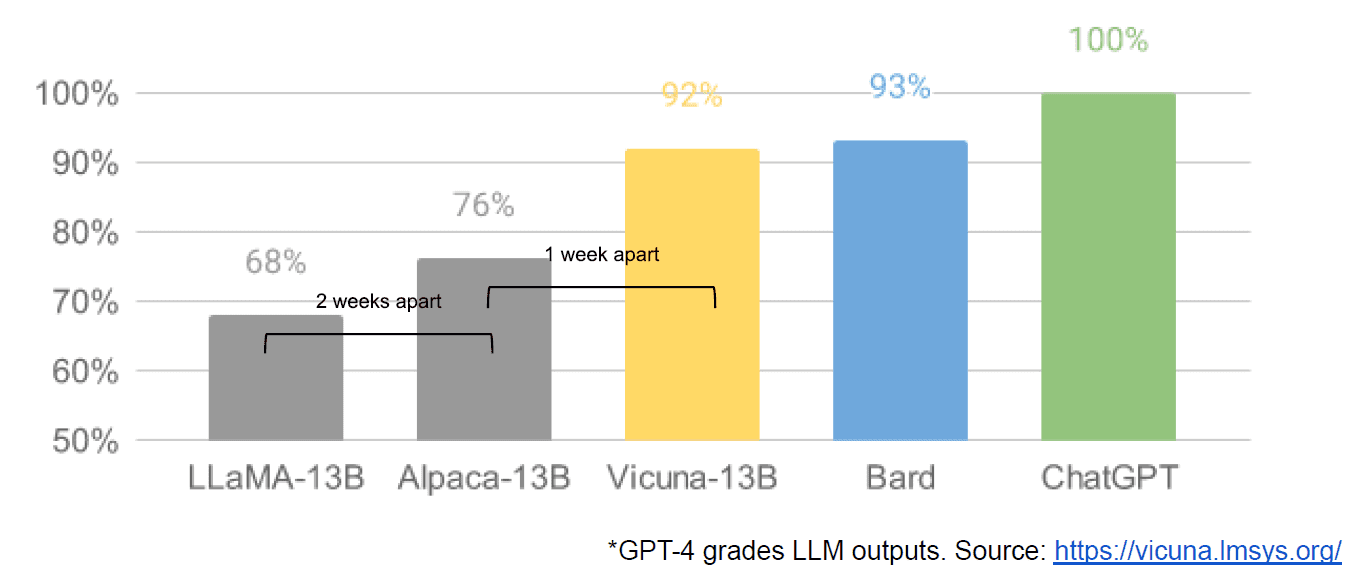
最後に、Googleの内部文書「私たちには堀がなく、OpenAIにもありません」というものがリークされたという噂がありました。それはクローズドモデルとコミュニティが製造する遥かに小さく、安価なモデルが、それらのクローズドソースの相当物と同じかそれ以上の性能を発揮するという革新に対する否定的な見方をしています。この記事のソースがGoogle内部であることを検証する方法はないため、「噂」と言わざるを得ません。しかし、次のグラフが含まれていることは間違いありません。
テキストから画像を合成するStable Diffusionは、オープンソースの生成AIが専有モデルよりも速く進化してきたもう1つの例です。そのプロジェクトの最近のイテレーション(ControlNet)は、Dall-E2の機能を上回るように改良されました。これは、世界中の多くの人々がいたるところでいじくり回して、単一の機関が追いつくのが難しいほどの進歩のペースをもたらしたものです。その中には、Stable Diffusionをより高速にトレーニングし、安価なハードウェアで実行できるようにする方法を見つけた人々がいました。それにより、より多くの人々による短い反復サイクルが可能になりました。
そして、私たちは完全なサイクルに戻ってきました。お金や設備があまりにも多すぎないことが、普通の人々のコミュニティ全体で巧妙なイノベーションを生み出すようになりました。AI開発者であるには、どんな時代でも素晴らしいですね。Mathew Lodgeは、AI For CodeスタートアップのDiffblueのCEOです。彼はAnacondaやVMwareなどの企業で25年以上にわたって製品リーダーシップの多様な経験を持っています。Lodgeは現在、Good Law Projectの理事会の一員であり、Royal Photographic Societyの副議長も務めています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






