「LLMプロンプティングにおける思考の一端:構造化されたLLM推論の概要」
LLMプロンプティングにおける思考の一端:構造化されたLLM推論の概要' 'An Introduction to Structured LLM Reasoning in LLM Prompting
Chain-of-Thoughts(CoT)、Tree-of-Thoughts(ToT)、Graph-of-Thoughts(GoT)など、これらの思考は何でしょうか?

スマートフォンやスマートホームの時代において、指示に従うだけでなく、私たちと同じように複雑な論理に取り組むAIを想像してみてください。まるでSFのような話ですね。しかし、ChatGPTで遊んだことがあるなら、おそらくこの驚くべき能力を直接目にしたことでしょう。AIの推論において著名な存在であるHector Levesqueさえも、一度Geoffrey HintonというAIの伝説に対して「なぜそんな愚かな方法(ニューラルネットワークを指して)が推論に対処できるのか?」とコメントしたほど驚愕していました。
この話は、AIの進歩の重大な側面を示していますが、その真髄は大規模言語モデル(LLM)と推論の微妙なダンスに見出されます。このダンスの入り口は「Prompt Engineering」です。これは、LLMに提供されるテキスト入力を最適化し、望ましい出力を引き出すための技術と科学です。その核心は、ChatGPT、Bard、Claude、LLamaなどの言語モデルが異なるプロンプトにどのように反応するかの微妙なニュアンスを理解し、この知識を活用して特定の結果を達成することにあります。
LLMを広範な知識の貯蔵庫と考えてください。質問や声明(プロンプト)のフレーズの仕方によって、その貯蔵庫にアクセスする方法が決まります。人間が質問の仕方に基づいて異なる回答をすることがあるように、LLMも入力に基づいて異なる応答をすることがあります。
この記事では、LLMの推論を向上させるために設計されたさまざまなプロンプトエンジニアリングフレームワークについて簡潔な概要を紹介します。以下が含まれます:
- 「プログラマーの生産性を10倍にするための5つの無料のAIツール」
- 「Amazon SageMakerを使用して、Rayベースの機械学習ワークフローをオーケストレーションする」
- RayはNVIDIA AIとの協業により、開発者が製品向けのLLMを構築、調整、トレーニング、スケールアップするのを支援します
- Chain-of-Thought
- Chain-of-Thought-Self-Consistency
- Tree-of-Thoughts
- Graph-of-Thoughts
- Algorithm-of-Thoughts
- Skeleton-of-Thought
- Program-of-Thoughts
Chain-of-Thought(CoT)
答えを直接出力する代わりに、中間の推論例を言語モデルに提供してその応答をガイドします。
Chain-of-Thought(CoT)プロンプティングは、大規模言語モデルの意思決定プロセスを向上させるための先駆的かつ最も影響力のあるプロンプトエンジニアリング手法の1つとして認識されています。直接の入出力の相互作用を重視する従来のプロンプティング手法とは異なり、CoTはモデルに推論を中間ステップに分割するように強制します。この手法は、複雑な課題がより管理しやすいコンポーネントに分割される人間の認知プロセスに類似しています。
例として、数学の問題を考えてみましょう。「Rogerはテニスボールを5つ所有し、その後、3つのボールを含む缶を2つ購入しました。彼は今、何個のテニスボールを所有していますか?」。個人が11と直接結論を導く代わりに、次のように理論的に考えることがあります。「最初に、Rogerは5つのボールを持っています。各缶には3つのボールが入っており、2つの缶の合計は6つのボールです。値を合計すると、5 + 6で11になります。」このようなステップバイステップの分析的推論を入力プロンプトに統合することで、モデルの応答の正確さが向上し、さらなるトレーニングデータセットの追加や基本的なモデル構成の変更なしに達成されます。
Chain-of-Thought-Self-Consistency(CoT-SC)
複数の思考の連鎖を構築し、それぞれを評価し、最も効果的かつ一貫性のある連鎖を選択します。
Chain of Thoughtフレームワークからの後続の進化形であるCoT-Self-consistency。この手法は、クエリに対して複数の並行した推論経路を引き起こし、最終的な回答を決定する前に重み付けメカニズムを適用します。このアプローチは、従来の機械学習で見られるアンサンブル技術に類似していますが、大規模言語モデルの思考シーケンスに適用されます。
思考の木(ToT)
思考の連鎖を木形式で展開します。これにより、一つのルートアイデアから派生する複数の推論の枝を探索し、バックトラッキングが可能になります。
思考の木(ToT)は、複雑な問題をより管理しやすい部分に分解することで、LLM推論に対するより構造化されたプロンプトフレームワークを提供します。連鎖的に推論するCoTとは異なり、ToTは問題解決の戦略を木形式で整理します。各ノードは「思考」と呼ばれ、最終的な答えに向かう一歩となる、一貫した言語の連続です。ToTでは、これらの離散的な「思考」ユニットに問題を分割することにより、クロスワードパズルの一連の単語から数学の方程式の一部まで、問題の各フェーズが系統的に対処されるようになっています。
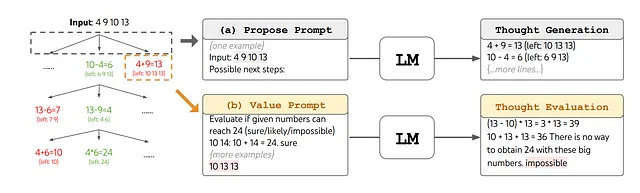
ToTの操作的な強みは、その方法論的な組織化にあります。まず、システムは問題を分解し、現在の状態から潜在的な推論ステップまたは「思考」候補のリストを生成します。次に、これらの思考を評価し、各思考が目的の解決策につながる可能性をシステムが評価します。Breadth-first search(BFS)やDepth-first search(DFS)などの標準的な探索アルゴリズムを使用して、この木をナビゲートし、思考の最も効果的なシーケンスを特定するのにモデルを支援します。
ToTの重要性は、その総合的な設計、適応性、効率性にあります。Chain-of-ThoughtのプロンプトはToTフレームワーク内の特定のインスタンスと見なすことができます。モジュール化された性質から、問題の初期分解から使用される検索アルゴリズムまで、個々のコンポーネントは独立して動作できます。
思考のグラフ(GoT)
ツリー構造を直接非循環グラフに進化させます。これにより、特定の思考ルートを固めたり、複数の思考を一つにまとめることができます。
グラフの思考(GoT)フレームワークは、CoTやToTの手法からの高度な進化を表します。GoTフレームワークの中心には、アイデアを有向非循環グラフ(DAG)の頂点として概念化することがあります。この文脈では、各頂点は入力刺激によって引き起こされる、予備的な、中間的な、または終端的な思考または解決策に対応します。このグラフ内の有向辺は、これらの思考間の相互依存関係を示しています。具体的には、思考t1からt2へのエッジが延びている場合、t2がt1に基づいて構想されたことを意味します。この体系化により、ノードは「計画」や「結果」といった異なるカテゴリに分類される可能性があります。
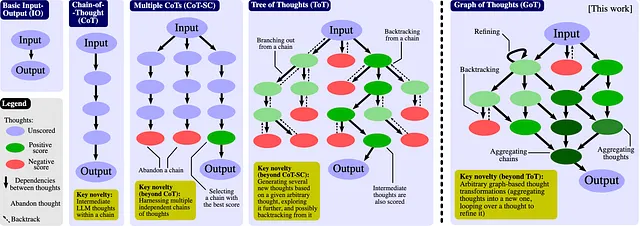
GoTの新しさは、これらの思考に変換を適用し、推論プロセスをさらに洗練する能力にあります。基本的な変換には、いくつかの思考を統合して一つにまとめることができる「集約」、単一の思考に継続的な反復を行い、その精度を向上させる「洗練」、既存の思考から生じる新しい思考の構想を容易にする「生成」が含まれます。これらの変換は、推論経路の統合に重点を置いたものであり、CoTやToTのような以前のモデルと比較してより複雑な視点を提供します。
さらに、GoTはスコアリングとランキングを通じて評価の次元を導入します。個々の思考は、頂点で表される各個人的な思考に対して、関連性と品質に基づいた評価を受けます。重要なことは、この関数が推論の全体的な連鎖を考慮し、グラフ内の他の頂点との関係で文脈化されるスコアを割り当てることです。このフレームワークはまた、それぞれのスコアに基づいて思考を階層化するシステムに能力を持たせ、どのアイデアが優先度または実装を要するかを判断する際に重要な機能を提供します。
思考のアルゴリズム(AoT)
1つの進化するコンテキストチェーンを維持し、Tree-of-Thoughtのような冗長なクエリの必要性を排除します。可変の推論パスを探索します。
ToTとGoTは、グラフ形式の多くの推論パスを生成する検索ベースのメカニズムを通じて、LLM推論の課題に取り組んでいます。ただし、数百ものLLMクエリに頼ることがあり、単一の問題に対して計算上の効率の問題が発生します。
思考のアルゴリズム(AoT)は、動的で変更可能な推論パスを特徴とする革新的な手法を提供します。1つの進化する思考コンテキストチェーンを維持することにより、AoTは思考の探索を統合し、効率を向上させ、計算上のオーバーヘッドを削減します。
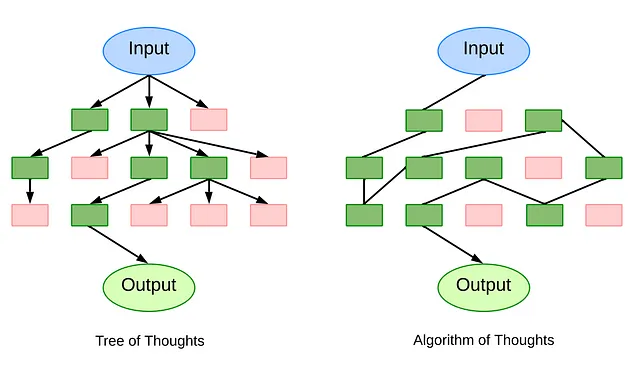
AoTの独創性は、LLMが強力であるにもかかわらず、新しいが既知の問題に直面したときに以前の解答に戻ることがあるという観察に由来しています。これを克服するために、AoTはコンテキスト内の例を取り込み、深さ優先探索(DFS)や幅優先探索(BFS)などの時間をかけて検証された検索アルゴリズムから引用します。アルゴリズムの振る舞いを模倣することにより、AoTは成功した結果を得ることと失敗した試みから洞察を得ることの重要性を強調します。
AoTの基盤は、以下の4つの主要な要素にあります:1)複雑な問題を消化しやすいサブ問題に分解し、それらの相互関係と個別に対処できる容易さの両方を考慮すること。2)これらのサブ問題に対して一貫した解決策を連続的かつ中断されない形で提案すること。3)明示的な外部のプロンプトに依存せずに、各解決策またはサブ問題の実現可能性を直感的に評価すること。4)コンテキスト内の例とアルゴリズムのガイドラインに基づいて、探索またはバックトラックする最も有望なパスを決定すること。
思考のスケルトン(SoT)
詳細を具体化する前に、最初に回答のブループリントを生成し、完全な回答を生成するまでの時間を短縮します。
思考のスケルトン(SoT)パラダイムは、主にLarge Language Models(LLMs)の推論能力を強化することよりも、エンドツーエンドの生成レイテンシを最小化するという重要な課題に取り組むために特別に設計されています。この方法論は、回答の予備的なブループリントを生成し、それに続く包括的な展開を行うという二段階のアプローチに基づいて運用されます。

最初の「スケルトンステージ」では、包括的な回答を生成するのではなく、モデルは簡潔な回答スケルトンを生成するように促されます。このスケルトンテンプレートを通じて促されるこの簡略化された表現は、見込みのある回答の核心要素を捉え、その後のステージの基盤を築きます。
次の「ポイント展開ステージ」では、LLMは回答スケルトンで示された各コンポーネントを系統的に拡大します。ポイント展開のプロンプトテンプレートを活用して、モデルはスケルトンの各セグメントについて同時に詳細を展開します。この二分的なアプローチは、生成プロセスを予備的なスケルトンの形成と並列化された詳細な展開に分割することで、回答生成を加速するだけでなく、出力の一貫性と精度を保つことを目指しています。
思考のプログラム(PoT)
質問応答の背後にある推論を実行可能なプログラムに定式化し、最終回答の一部としてプログラムインタープリターの出力を組み込みます。
思考のプログラム(PoT)は、LLMの推論に対する独自のアプローチであり、単に自然言語で回答を生成するだけでなく、実行可能なプログラムの作成を求めます。これにより、プログラムインタープリター(Pythonなど)で実行できる具体的な結果を生成することができます。この方法は、より直接的なモデルとは対照的であり、推論を順序立てたステップに分解し、変数と意味を関連付ける能力を強調しています。その結果、PoTは数値計算が必要な数学的な論理的な質問に特に適しており、回答の導出方法をより明確で表現豊かで確固としたものにし、精度と理解を向上させます。
ポトのプログラム実行において、最終的な答えを目指す必要はなく、最終的な答えへの中間ステップの一部となることが重要です。

AIの常に進化する領域において、Chain-of-Thoughtのような構造化推論フレームワークは、大規模言語モデルの力をどのように認識し利用するかを劇的に変えています。これらは、情報を単に反復するだけでなく、人間の認知プロセスに類似した複雑な推論にも関与するモデルへの移行を象徴しています。私たちは先を見つめると、潜在的な可能性は無限大に思えます。正確な答えだけでなく、堅牢なプログラム可能な解決策を生成することにも長けたAI、または思考プロセスを可視化する能力を持つAIを想像してみてください。これにより、AIと人間の協力がよりシームレスになります。本記事で探求された基盤となるフレームワークを基にしたこれらの進歩は、問題解決、創造性、意思決定においてLLM(大規模言語モデル)が不可欠なパートナーとなる未来を告げ、私たちの技術との共生関係においてパラダイムシフトを促します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






