大規模言語モデル(LLM)の時代におけるイノベーションと安全性・プライバシーのバランス
LLMの時代におけるイノベーションと安全性・プライバシーのバランス
ジェネレーティブAIアプリケーションの安全性とプライバシーメカニズムの実装ガイド
AI時代は、大規模な言語モデル(LLM)を技術の最前線に押し上げました。これは2023年の話題の中心であり、今後も長年にわたってそのような存在であるでしょう。LLMは、ChatGPTなどの裏にあるパワーハウスとなるAIモデルです。これらのAIモデルは、膨大な量のデータと計算能力によって支えられ、人間のようなテキスト生成から自然言語理解(NLU)のタスクの支援まで、驚くべき能力を引き出すことができます。彼らは、無数のアプリケーションやソフトウェアサービスの基盤となり、少なくともそれらが補完される形で構築されるようになりました。
しかし、他の革新的な技術と同様に、LLMの台頭は重要な問題を提起します。「技術の進歩と安全性、プライバシーの必要性をどのようにバランスさせるのか?」。これは単なる哲学的な問いではなく、積極的かつ綿密な行動を必要とする挑戦です。
安全性とプライバシー
LLMを使用したアプリケーションにおいて安全性とプライバシーを優先するために、個人データ(個人を特定できる情報、PIIとも呼ばれる)の拡散や有害なコンテンツの制御など、重要な領域に焦点を当てます。これは、独自のデータセットを使用してLLMを調整する場合でも、テキスト生成のタスクにLLMを単に使用する場合でも重要です。なぜ重要なのでしょうか?重要な理由はいくつかあります。
- ユーザーの個人情報の保護を義務付ける政府の規制(GDPR、CCPA、HIPAA Privacy Ruleなど)の遵守
- LLMプロバイダーのエンドユーザーライセンス契約(EULA)または利用規約(AUP)の遵守
- 組織内で設定された情報セキュリティポリシーの遵守
- ファインチューニング後のモデルにおけるバイアスや偏りの可能性の緩和
- LLMの倫理的な使用とブランドの評判の維持
- 将来のAI規制に備える
ファインチューニングの考慮事項
LLMのファインチューニングの準備をする際、最初のステップはデータの準備です。研究、教育、個人のプロジェクト以外では、トレーニングデータにPII情報が含まれている可能性があります。ここでは、データ内にこれらのPIIエンティティが存在するかを特定し、次にこれらのPIIエンティティが適切に匿名化されるようにデータをスクラブする必要があります。
- Zipperを使用してサーバーレスアプリを高速に構築:TypeScriptで記述し、その他のすべてをオフロードする
- VoAGIニュース、9月20日:ExcelでのPython:これがデータサイエンスを永遠に変えるでしょう•新しいVoAGI調査!
- 「セキュアな会話:ChatGPTの使用時にプライバシーとデータを保護する 🛡️」

テキスト生成の考慮事項
LLMを使用したテキスト生成においては、いくつかの点に注意する必要があります。まず、有害なコンテンツを含むプロンプトがLLMに伝播しないように制限すること、そしてプロンプト自体にPIIエンティティが含まれていないことを確認します。さらに、いくつかの場合では、これらの検証を「LLMによって生成されたテキスト」または「機械生成テキスト」に対して実行することが適切かもしれません。これにより、安全性とプライバシーの理念を確保するための二重の保護層が得られます。三番目の側面は、プロンプト自体の意図を判断することであり、これによってプロンプトのインジェクション攻撃などがある程度抑制される可能性があります。ただし、この記事では主にPIIと有害性に焦点を当て、意図の分類とLLMへの影響については別の議論で説明します。

実装
この問題に対するソリューションを実装するために、2つのステップを踏みます。まず、テキスト内のPIIエンティティを特定し、これらのエンティティを適切に匿名化することができる名前エンティティ認識(NER)モデルを使用します。PIIエンティティには、人名、場所や住所、電話番号、クレジットカード番号、社会保障番号などが通常含まれます。次に、テキスト分類モデルを使用して、テキストが有害か中立かを分類します。有害なテキストの例には、虐待、卑語、嫌がらせ、いじめなどがあります。
PII NERモデルの場合、最も一般的な選択肢は、特定のPIIエンティティを検出するためにファインチューニングできるBERT Baseモデルです。また、医療記録の非識別化のためにファインチューニングされたRobust DeID(非識別化)プリトレーニングモデルや、主に個人の健康情報(PHI)に焦点を当てたRoBERTaモデルなど、事前にトレーニングされたトランスフォーマーモデルをファインチューニングすることもできます。実験を開始するためのより簡単なオプションは、spaCy ER(EntityRecognizer)を使用することです。
import spacynlp = spacy.load("en_core_web_lg")text = "Applicant's name is John Doe and he lives in Silver St. \ and his phone number is 555-123-1290"doc = nlp(text)displacy.render(doc, style="ent", jupyter=True)これにより、以下の結果が得られます

spaCyのEntityRecognizerは、3つのエンティティ(人物、場所または住所、他のタイプに該当しない数値)を識別できました。spaCyは、検出されたエンティティの開始位置と終了位置(テキスト内の文字位置)も提供しており、これを使用して匿名化を実行することができます。
ent_positions = [(ent.start_char, ent.end_char) for ent in doc.ents]for start, end in reversed(ent_positions): text = text[:start] + '#' * (end - start) + text[end:]print(text)これにより、以下の結果が得られます
Applicant's name is ######## and his he lives in ###################and his phone number is ###-123-1290しかし、明らかな問題がいくつかあります。spaCy ERのデフォルトのエンティティリストは、すべてのタイプのPIIエンティティを網羅していません。たとえば、この場合、555-123-1290をPHONE_NUMBERとして検出したいのに、CARDINALの一部として検出してしまい、エンティティの検出が不完全になってしまいます。もちろん、トランスフォーマーベースのNERモデルと同様に、spaCyも独自のカスタム名エンティティのデータセットでトレーニングすることで、より堅牢なモデルにすることができます。ただし、より目的に特化したデータ保護および非識別化のためのツールキットであるオープンソースのPresidio SDKを使用します。
PresidioによるPIIの検出と匿名化
Presidio SDKは、長いサポートされるPIIエンティティのリストを持つ、PIIの検出能力の完全なセットを提供します。Presidioは主にパターンマッチングを使用し、spaCyおよびStanzaのML機能と組み合わせていますが、Presidioはカスタマイズ可能であり、トランスフォーマーベースのPIIエンティティ認識モデルやAzure Text Analytics PII検出などのクラウドベースのPII機能と連携して使用することもできます。また、テキストからPIIエンティティを削除および隠すための組み込みのカスタマイズ可能な匿名化ツールも備えています。
from presidio_analyzer import AnalyzerEnginetext="""Applicant's name is John Doe and his he lives in Silver St.and his phone number is 555-123-1290."""analyzer = AnalyzerEngine()results = analyzer.analyze(text=text, language='en')for result in results: print(f"PII Type={result.entity_type},", f"Start offset={result.start},", f"End offset={result.end},", f"Score={result.score}")これにより、以下の結果が得られます
PII Type=PERSON, Start=21, End=29, Score=0.85PII Type=LOCATION, Start=50, End=60, Score=0.85PII Type=PHONE_NUMBER, Start=85, End=97, Score=0.75および

前にも見たように、テキストの匿名化は非常に簡単なタスクです。なぜなら、テキスト内の各エンティティの開始と終了オフセットを持っているからです。しかし、Presidioの組み込みのAnonymizerEngineを使用してこれを行います。
from presidio_anonymizer import AnonymizerEngineanonymizer = AnonymizerEngine()anonymized_text = anonymizer.anonymize(text=text,analyzer_results=results)print(anonymized_text.text)これにより、
応募者の名前は<PERSON>で、彼の住所は<LOCATION>で、電話番号は<PHONE_NUMBER>です。となります。
これまでのところは素晴らしいですが、もし匿名化を単なる覆い隠しにしたい場合はどうなりますか。その場合、AnonymizerEngineにカスタム設定を渡すことができ、PIIエンティティを簡単なマスキングで行うことができます。たとえば、エンティティをアスタリスク(*)の文字でマスクします。from presidio_anonymizer import AnonymizerEnginefrom presidio_anonymizer.entities import OperatorConfigoperators = dict()# `results`は`AnalyzerEngine`によるPIIエンティティの検出の出力であると仮定しています。for result in results: operators[result.entity_type] = OperatorConfig("mask", {"chars_to_mask": result.end - result.start, "masking_char": "*", "from_end": False})anonymizer = AnonymizerEngine()anonymized_results = anonymizer.anonymize( text=text, analyzer_results=results, operators=operators)print(anonymized_results.text)
となります。
応募者の名前は********で、彼の住所は**********で、電話番号は************です。
匿名化に関する考慮事項
テキスト内のPIIエンティティを匿名化する場合にはいくつかの注意点があります。
- Presidioのデフォルトの
AnonymizerEngineは、PIIエンティティ(<PHONE_NUMBER>など)をマスクするためにパターン<ENTITY_LABEL>を使用します。これは特にLLMの微調整に問題を引き起こす可能性があります。PIIをエンティティの種類のラベルで置き換えることで、意味を持つ単語が導入され、言語モデルの振る舞いに影響を与える可能性があります。
- 疑名化はデータ保護の有用なツールですが、トレーニングデータに対して疑名化を行う際は注意が必要です。たとえば、すべての
NAMEエンティティを疑名「John Doe」で置き換えるか、すべてのDATEエンティティを01-JAN-2000で置き換えると、微調整データに極端なバイアスが生じる可能性があります。
- LLMがプロンプト内の特定の文字やパターンに反応する方法について注意してください。特定のLLMは、モデルの最大の効果を得るために、非常に特定のプロンプトのテンプレート方法が必要な場合があります。たとえば、Anthropicはプロンプトタグの使用を推奨しています。これを意識することで、どのように匿名化を実行したいかを決定するのに役立ちます。
匿名化されたデータがモデルの微調整に与える一般的な副作用として、文脈の喪失、意味の漂流、モデルの幻覚などがあります。モデルのパフォーマンスに対する否定的な影響を最小限に抑えつつ、ニーズに適した匿名化レベルを見つけるために反復して実験することが重要です。
テキスト分類による有害性検出
テキストが有害なコンテンツを含んでいるかどうかを特定するために、バイナリ分類アプローチを使用します。テキストが中立的な場合は0、有害な場合は1とします。私はDistilBERTベースモデル(小文字)をトレーニングすることにしました。これはBERTベースモデルの蒸留版です。トレーニングデータにはJigsawデータセットを使用しました。
モデルのトレーニング方法やモデルのメトリクスの詳細については触れませんが、テキスト分類タスク用のDistilBERTベースモデルのトレーニングに関するこの記事を参照してください。私が書いたモデルトレーニングスクリプトはこちらでご覧いただけます。モデルはHuggingFace Hubでtensor-trek/distilbert-toxicity-classifierとして利用できます。いくつかのサンプルテキストを推論に通してモデルが何を示してくれるかをチェックしてみましょう。
from transformers import pipeline
text = ["これは傑作でした。完全に原作に忠実ではありませんが、始めから終わりまで魅了されました。私のお気に入りの3作品の中でもかもしれません。",
"私はその鳥を殺したいと思っています。嫌いです。"]
classifier = pipeline("text-classification", model="tensor-trek/distilbert-toxicity-classifier")
result = classifier(text)
print(result)
結果は次のようになります —
[{'label': 'NEUTRAL', 'score': 0.9995143413543701}, {'label': 'TOXIC', 'score': 0.9622979164123535}]
モデルはテキストをかなり高い信頼度でNEUTRALまたはTOXICとして正しく分類しています。このテキスト分類モデルは、以前に議論したPIIエンティティ分類と組み合わせて、LLM駆動のアプリケーションやサービス内でプライバシーと安全性を強制するメカニズムを作成するために使用できます。
全体をまとめる
PIIエンティティ認識メカニズムを介してプライバシーに取り組み、テキストの有害性を分類することで安全性に取り組みました。組織の安全性とプライバシーの定義に関連する他のメカニズムを考えることができます。たとえば、医療機関はPIIではなくPHIに関心を持つ場合などです。最終的には、導入したいコントロールに関係なく、この全体的な実装アプローチは同じままです。
それを念頭に置いて、今はすべてを実行する時です。プライバシーと安全性のメカニズムをLLMと組み合わせて、生成AI機能を導入したいアプリケーションに使用することが目的です。人気のあるLangChainフレームワークのPythonフレーバー(JavaScript/TSでも利用可能)を使用して、2つのメカニズムを含む生成AIアプリケーションを構築します。次は、全体的なアーキテクチャの概要です。
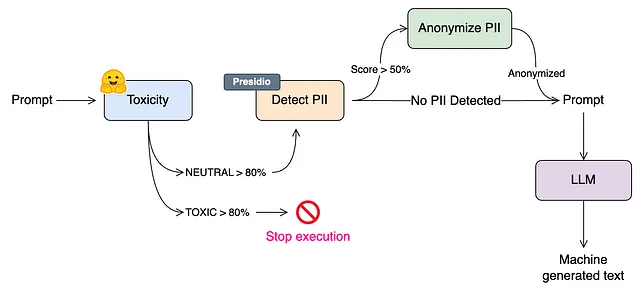
上記のアーキテクチャでは、まず、テキストがモデルの正確性が80%以上の有害なコンテンツを含んでいるかをチェックします。そうである場合、LangChainアプリケーション全体の実行はそこで停止し、適切なメッセージがユーザーに表示されます。テキストが主に中立的に分類される場合、次のステップでPIIエンティティの識別を行います。各エンティティの検出の信頼度スコアが50%以上の場合、テキスト内のこれらのエンティティを匿名化します。テキストが完全に匿名化されたら、それをLLMへのプロンプトとして渡してモデルによるさらなるテキスト生成を行います。正確性の閾値(80%と50%)は任意の値です。PIIおよび有害性の検出器の正確性をデータでテストし、ユースケースに最適な閾値を決定する必要があります。閾値が低いほど、システムは厳格になり、閾値が高いほど、これらのチェックの強制力は弱まります。
より保守的なアプローチとしては、PIIエンティティが検出された場合に実行を停止することが考えられます。これは、PIIデータを処理することが認証されていないアプリケーションに役立ちます。いかなる場合でも、PIIを含むテキストが入力としてアプリケーションに渡されることを防ぎたい場合です。
LangChainの実装
LangChainで動作するようにするために、PrivacyAndSafetyChainというカスタムチェーンを作成しました。これは、LangChainでサポートされているLLMとチェーンすることができます。以下は、その概要です。
from langchain import HuggingFaceHub
from langchain import PromptTemplate, LLMChain
from PrivacyAndSafety import PrivacyAndSafetyChain
safety_privacy = PrivacyAndSafetyChain(verbose=True, pii_labels=["PHONE_NUMBER", "US_SSN"])
template = """{question}"""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = HuggingFaceHub(repo_id=repo_id, model_kwargs={"temperature": 0.5, "max_length": 256})
chain = (
prompt
| safety_privacy
| {"input": (lambda x: x['output']) | llm}
| safety_privacy
)
try:
response = chain.invoke(
{"question": """以下のテキストから「ジョン・ドウの住所、電話番号、SSNは何ですか?」という質問に対する回答を生成してください。ジョン・ドウはスプリングフィールドの1234エルムストリートに住んでおり、最近誕生日を迎えた彼は今年で43歳になりました。彼は若い頃の思い出を親しい友人と電話で共有することがよくあります。電話番号は(555) 123-4567です。その間、ある日の夜、彼は[email protected]から旧友の再会を思い出すメールを受け取りました。彼が古い文書を探っている間に、338-12-6789という番号が彼のSSNとしてリストに記載されている紙を見つけ、それをより安全な場所に保管することを思い出しました。"""
}
)
except Exception as e:
print(str(e))
else:
print(response['output'])
デフォルトでは、PrivacyAndSafetyChain はまず有毒コンテンツの検出を行います。もし有毒コンテンツが検出された場合、前述のようにチェーンはエラーとなり、停止します。有毒コンテンツが検出されない場合は、入力されたテキストをPIIエンティティ認識器に渡し、どのマスキング文字を使用するかに基づいて、チェーンは検出されたPIIエンティティでテキストを匿名化します。以下は、前述のコードの出力です。有害なコンテンツがないため、チェーンは停止しませんでした。そして、PHONE_NUMBER と SSN を検出し、正しく匿名化しました。
> 新しい PrivacyAndSafetyChain チェーンに入る...PrivacyAndSafetyChain を実行中...有害コンテンツのチェック中...PIIのチェック中...> チェーンの実行終了.> 新しい PrivacyAndSafetyChain チェーンに入る...PrivacyAndSafetyChain を実行中...有害コンテンツのチェック中...PIIのチェック中...> チェーンの実行終了.1234 Elm Street, **************, ***********
結論
この記事の最も重要なポイントは、大規模言語モデルを革新し続ける中で、革新と安全性、プライバシーのバランスを取ることが不可欠であるということです。LLMに対する熱狂と、それらを可能な限りの使い方で統合しようとする我々の欲望は否応なく存在します。しかし、データプライバシーの侵害、意図しないバイアス、または誤用などの潜在的な落とし穴も同様に現実的であり、直ちに対処する必要があります。この記事では、LLMに進む前にPIIと有害なコンテンツを検出するメカニズムを確立する方法と、LangChainを使用した実装について説明しました。
まだ研究と開発の余地はたくさんあります。もしかしたら、より良いアーキテクチャ、より信頼性の高いデータプライバシーと安全性を確保するためのシームレスな方法が存在するかもしれません。この記事のコードは簡潔にするために短縮されていますが、GitHubリポジトリをチェックしていただき、各ステップの詳細なノートブックと議論したカスタムLangChainの完全なソースコードをご覧ください。それを使用し、フォークし、改善し、前進して革新してください!
参考文献
[1] Jacob Devlin, Ming-Wei Chang et. al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[2] Victor Sanh, Lysandre Debut et. al DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
[3] Dataset — Jigsaw Multilingual Toxic Comment Classification 2020
特に記載がない限り、すべての画像は著者によるものです
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
