大規模言語モデル(LLM)の微調整
LLMの微調整
コンセプトの概要とPythonのコード例
これは、実践的な大規模言語モデル(LLM)の使用に関するシリーズの5番目の記事です。この投稿では、事前学習済みのLLMを微調整(FT)する方法について説明します。まず、FTの重要な概念と技術を紹介し、その後、PythonとHugging Faceのソフトウェアエコシステムを使用してモデルを微調整する具体的な例を示します。

このシリーズの前の記事では、プロンプトエンジニアリングをPythonコードに組み込むことで、実用的なLLMパワードアプリケーションを構築する方法を紹介しました。ほとんどのLLMの使用ケースでは、これは初めに試してみるべきアプローチです。なぜなら、他の方法と比べてリソースや技術的な専門知識をほとんど必要とせずに、多くの利点を提供してくれるからです。
ただし、既存のLLMにプロンプトを与えるだけでは対応できない状況や、より洗練された解決策が必要な場合もあります。それがモデルの微調整が役立つ場面です。
微調整とは何ですか?
微調整とは、事前学習済みモデルを取り、少なくとも1つの内部モデルパラメータ(重みなど)をトレーニングすることです。LLMの文脈では、これにより一般的なベースモデル(例:GPT-3)が特定のユースケース(例:ChatGPT)に特化したモデルに変換されることが一般的です。
- 「生成AI解放:ソフトウェアエンジニアのためのMLOpsとLLMデプロイメント戦略」
- キャンドル:Rustでのミニマリストな機械学習
- 「Flash-AttentionとFlash-Attention-2の理解:言語モデルの文脈長を拡大するための道」
このアプローチの主な利点は、モデルが教師付きトレーニングのみに依存するモデルと比べて、(はるかに)少ない手動ラベル付きの例でより良いパフォーマンスを達成できることです。
厳密に自己教師付きのベースモデルはプロンプトエンジニアリングの助けを借りてさまざまなタスクで印象的なパフォーマンスを発揮することができますが、それでも単なる単語の予測モデルであり、完全に役立つまたは正確な補完を生成しない場合があります。例えば、davinci(ベースのGPT-3モデル)とtext-davinci-003(微調整モデル)の補完を比較してみましょう。

ベースモデルは、単にGoogle検索や宿題のような一連の質問をリストアップしてテキストを補完しようとしているのに対し、微調整モデルはより役立つ回答を提供しています。text-davinci-003の微調整に使用されるフレーバーは「アライメントチューニング」で、LLMの応答をより役立つ、正直な、無害なものにすることを目指していますが、それについては後ほど詳しく説明します。
なぜ微調整するのですか?
微調整はベースモデルのパフォーマンスを向上させるだけでなく、より小さい(微調整された)モデルはしばしば大きい(より高価な)モデルよりも、それがトレーニングされたタスクのセットで優れたパフォーマンスを発揮することがあります。これはOpenAIが初代の「InstructGPT」モデルで実証されています。そこでは、1.3Bのパラメータを持つInstructGPTモデルの補完が、175Bのパラメータを持つGPT-3ベースモデルよりも好まれました(サイズは100倍小さいです)。
現在私たちが相互作用するLLMのほとんどは、GPT-3のような厳密な自己教師付きモデルではありませんが、特定のユースケース向けに既存の微調整モデルにプロンプトを与えることにはまだ欠点があります。
その一つは、LLMには有限のコンテキストウィンドウがあることです。したがって、大きな知識ベースやドメイン固有の情報が必要なタスクでは、モデルのパフォーマンスが十分でない場合があります。微調整モデルは、微調整プロセス中にこの情報を「学習」することで、この問題を回避できます。また、追加のコンテキストをプロンプトに詰め込む必要もなくなり、推論コストが低くなる可能性があります。
ファインチューニングの3つの方法
モデルをファインチューニングするためには、自己教示学習、教師あり学習、強化学習の3つの一般的な方法があります。これらは互いに排他的ではなく、これらの3つのアプローチの組み合わせを使用して単一のモデルをファインチューニングすることができます。
自己教示学習
自己教示学習は、トレーニングデータの固有の構造に基づいてモデルをトレーニングすることで構成されます。LLM(Language Model)の文脈では、これは一般的に、単語(またはトークン)のシーケンスを与えられた場合、次の単語(トークン)を予測することです。
これは現代の多くの事前学習言語モデルの開発方法ですが、モデルのファインチューニングにも使用することができます。これの潜在的な使用例は、一連の例文を与えた場合に、人の文章スタイルを模倣できるモデルを開発することです。
教師あり学習
次に、おそらく最も一般的なモデルのファインチューニング方法は、教師あり学習を介して行われます。これには、特定のタスクのための入出力ペアを使用してモデルをトレーニングすることが含まれます。例として、指示調整(instruction tuning)があります。これは、質問に対するモデルの性能を向上させることを目指しています [1,3]。
教師あり学習の鍵となるステップは、トレーニングデータセットを作成することです。これを行うための簡単な方法は、質問と回答のペアを作成し、それらをプロンプトテンプレートに統合することです [1,3]。たとえば、質問と回答のペア “アメリカ合衆国の35番目の大統領は誰ですか? – ジョン・F・ケネディ” は、以下のプロンプトテンプレートに貼り付けることができます。他の例のプロンプトテンプレートは、参考文献[4]のセクションA.2.1で入手できます。
"""以下の質問に答えてください。Q: {Question} A: {Answer}"""プロンプトテンプレートの使用は重要です。なぜなら、GPT-3などのベースモデルは本質的に「文書の補完」モデルだからです。つまり、あるテキストが与えられた場合、モデルはその文脈で(統計的に)意味をなすテキストを生成します。これは、このシリーズの以前のブログとプロンプトエンジニアリングのアイデアにさかのぼります。
プロンプトエンジニアリング — AIを問題解決に利用する方法
7つのプロンプトトリック、Langchain、およびPythonの例コード
towardsdatascience.com
強化学習
最後に、モデルのファインチューニングに強化学習(RL)を使用することができます。RLは報酬モデルを使用してベースモデルのトレーニングをガイドするものです。これはさまざまな形式で行うことができますが、基本的なアイデアは、報酬モデルをトレーニングして、言語モデルの補完をスコアリングし、それが人間のラベラーの好みを反映するようにすることです [3,4]。報酬モデルは、リインフォースメントラーニングアルゴリズム(例:Proximal Policy Optimization(PPO))と組み合わせて、事前学習済みモデルをファインチューニングするために使用できます。
RLをモデルのファインチューニングに使用する例として、OpenAIのInstructGPTモデルが示されており、これは3つの主要なステップを経て開発されました [4]。
- 高品質なプロンプト-レスポンスのペアを生成し、教師あり学習を使用して事前学習済みモデルをファインチューニングする(約13,000のトレーニングプロンプト)。注:事前学習済みモデルでステップ2に進むこともできます [3]。
- ファインチューニングされたモデルを使用して補完を生成し、人間ラベラーが好みに基づいて応答をランク付けする。これらの好みを使用して報酬モデルをトレーニングする(約33,000のトレーニングプロンプト)。
- 報酬モデルとRLアルゴリズム(例:PPO)を使用してモデルをさらにファインチューニングする(約31,000のトレーニングプロンプト)。
上記の戦略は、一般的にベースモデルよりも好ましいLLMの補完をもたらしますが、一部のタスクのパフォーマンスの低下というコストがかかることもあります。このパフォーマンスの低下は、アライメントタックスとも呼ばれます [3,4]。
教師ありファインチューニングのステップ(ハイレベル)
上記で見たように、既存の言語モデルを微調整する方法は多くあります。しかし、この記事の残りの部分では、教師あり学習を用いた微調整に焦点を当てます。以下は教師ありモデルの微調整の手順の概要です[1]。
- 微調整タスクの選択(例:要約、質問応答、テキスト分類)
- トレーニングデータセットの準備(100-10,000の入出力ペアの作成とデータの前処理(トークン化、切り捨て、テキストのパディング))
- ベースモデルの選択(さまざまなモデルで実験し、望ましいタスクで最も優れたパフォーマンスを発揮するモデルを選択)
- 教師あり学習を用いたモデルの微調整
- モデルのパフォーマンスの評価
これらの手順のそれぞれについては、それぞれが独自の記事になり得ますが、私は4番目の手順に焦点を当て、微調整モデルのトレーニング方法について説明したいと思います。
パラメータトレーニングの3つのオプション
~100M-100Bのパラメータを持つモデルを微調整する場合、計算コストに注意する必要があります。そのための重要な質問は、どのパラメータを(再)トレーニングするか、です。
パラメータの山によって、トレーニングするパラメータの選択肢は数え切れません。ここでは、選択するための3つの一般的なオプションに焦点を当てます。
オプション1:すべてのパラメータの再トレーニング
最初のオプションは、すべての内部モデルパラメータをトレーニングすることです(フルパラメータチューニングと呼ばれます)[3]。このオプションはシンプルですが、計算コストが最も高いです。また、フルパラメータチューニングには、壊滅的な忘却という現象が知られています。これは、モデルが初期のトレーニングで「学習した」有用な情報を「忘れる」現象です[3]。
オプション1のデメリットを軽減する方法の1つは、モデルパラメータの大部分をフリーズすることです。これについては、オプション2で説明します。
オプション2:転移学習
転移学習(TL)の大きなアイデアは、モデルが過去のトレーニングで学んだ有用な表現/特徴を新しいタスクに適用する際に保持することです。これは一般的には、ニューラルネットワーク(NN)の「ヘッド」を削除し、新しいものに置き換えること(例:ランダムな重みを持つ新しいレイヤーの追加)を含みます。なお、NNのヘッドには、モデルの内部表現を出力値に変換する最終層が含まれます。
パラメータの大部分を変更しないことで、LLMのトレーニングの巨大な計算コストを軽減する一方、TLは壊滅的な忘却の問題を必ずしも解決するとは限りません。これらの問題をより良く処理するために、異なるアプローチを採用することができます。
オプション3:パラメータ効率の良い微調整(PEFT)
PEFTは、比較的少数のトレーニング可能なパラメータをベースモデルに追加することを特徴とします。これにより、計算およびストレージのコストのわずかな部分で、フルパラメータチューニングと同等のパフォーマンスを発揮する微調整手法が実証されます[5]。
PEFTは、さまざまな手法を包括しており、その一つが人気のあるLoRA(Low-Rank Adaptation)メソッド[6]です。LoRAの基本的なアイデアは、既存のモデルの一部のレイヤーを選択し、それらの重みを次の式に従って変更することです。
![LoRAを使用した微調整のための重み行列の変更方法を示す方程式[6]。著者による画像。](https://miro.medium.com/v2/resize:fit:640/format:webp/1*GmCISYhd-JLqHNEvAQU1tQ.png)
ここで、h() = チューニングされる隠れ層、x = h()への入力、W₀ = hの元の重み行列、ΔW = hに注入されるトレーニング可能なパラメータの行列です。ΔWはΔW=BAとして分解されます。ここで、ΔWはd×kの行列であり、Bはd×rであり、Aはr×kです。rはΔWの「固有ランク」であり、1または2といった小さな値になることがあります[6]。
すべての数学について申し訳ありませんが、W₀の(d * k)の重みは凍結されており、したがって最適化には含まれません。代わりに、行列BおよびAを構成する((d * r)+(r * k))の重みだけがトレーニングされます。
d=1000、k=1000、およびr=2の仮想の数値を代入して効率の向上を感じるために、学習可能なパラメータの数はそのレイヤーで1,000,000から4,000に減少します。実際には、LoRA fine-tune GPT-3を使用した場合、LoRA論文の著者はフルパラメータのチューニング[6]と比較して、パラメータチェックポイントのサイズを10,000倍削減しています。
これを具体化するために、パーソナルコンピュータで実行するのに十分な効率で言語モデルをLoRAを使用して微調整する方法を見てみましょう。
例:LoRAを使用してLLMを微調整するコード
この例では、Hugging Faceエコシステムを使用して、テキストを「positive」または「negative」として分類するための言語モデルを微調整します。ここでは、BERTに基づいた約70Mパラメータモデルのdistilbert-base-uncasedを微調整します。このベースモデルは言語モデリングを行うためにトレーニングされたもので、分類ではないため、ベースモデルのヘッドを分類ヘッドで置き換えるために転移学習を使用します。さらに、モデルを十分効率的に微調整するためにLoRAを使用し、Mac Mini(M1チップ、16GBメモリ)で実行するのに合理的な時間(約20分)がかかります。
コードとconda環境ファイルはGitHubリポジトリで利用できます。最終モデルとデータセット[7]はHugging Faceで利用できます。
YouTube-Blog/LLMs/fine-tuning at main · ShawhinT/YouTube-Blog
Codes to complement YouTube videos and blog posts on VoAGI. – YouTube-Blog/LLMs/fine-tuning at main ·…
github.com
Imports
有用なライブラリとモジュールをインポートします。データセット、transformers、peft、およびevaluateはすべてHugging Face(HF)のライブラリです。
from datasets import load_dataset, DatasetDict, Datasetfrom transformers import ( AutoTokenizer, AutoConfig, AutoModelForSequenceClassification, DataCollatorWithPadding, TrainingArguments, Trainer)from peft import PeftModel, PeftConfig, get_peft_model, LoraConfigimport evaluateimport torchimport numpy as npベースモデル
次に、ベースモデルをロードします。ここでのベースモデルは比較的小さいものですが、他にも使用できる(より大きな)モデルがいくつかあります(例:roberta-base、llama2、gpt2)。完全なリストはこちらでご覧いただけます。
model_checkpoint = 'distilbert-base-uncased'# ラベルマップを定義しますid2label = {0: "Negative", 1: "Positive"}label2id = {"Negative":0, "Positive":1}# モデルのチェックポイントから分類モデルを生成しますmodel = AutoModelForSequenceClassification.from_pretrained( model_checkpoint, num_labels=2, id2label=id2label, label2id=label2id)データのロード
次に、HFのデータセットライブラリからトレーニングデータと検証データをロードします。これはバイナリラベルを持つ2000件の映画レビューのデータセットです(トレーニング用1000件、検証用1000件)。
# データセットをロードしますdataset = load_dataset("shawhin/imdb-truncated")dataset# dataset = # DatasetDict({# train: Dataset({# features: ['label', 'text'],# num_rows: 1000# })# validation: Dataset({# features: ['label', 'text'],# num_rows: 1000# })# }) データの前処理
次に、データを前処理してトレーニングに使用できるようにする必要があります。これには、テキストをベースモデルが理解できる整数表現に変換するためのトークナイザの使用が含まれます。
# トークナイザの作成tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, add_prefix_space=True)データセットにトークナイザを適用するために、.map() メソッドを使用します。これには、テキストの前処理方法を指定するカスタム関数が必要です。この場合、その関数の名前は tokenize_function() です。テキストを整数に変換するだけでなく、この関数は整数シーケンスを 512 の数字より長くしないように切り捨てます。
# トークナイズ関数の作成def tokenize_function(examples): # テキストを抽出 text = examples["text"] # テキストをトークナイズして切り捨てる tokenizer.truncation_side = "left" tokenized_inputs = tokenizer( text, return_tensors="np", truncation=True, max_length=512 ) return tokenized_inputs# パッドトークンが存在しない場合は追加するif tokenizer.pad_token is None: tokenizer.add_special_tokens({'pad_token': '[PAD]'}) model.resize_token_embeddings(len(tokenizer))# トレーニングデータセットと検証データセットをトークナイズするtokenized_dataset = dataset.map(tokenize_function, batched=True)tokenized_dataset# tokenized_dataset = # DatasetDict({# train: Dataset({# features: ['label', 'text', 'input_ids', 'attention_mask'],# num_rows: 1000# })# validation: Dataset({# features: ['label', 'text', 'input_ids', 'attention_mask'],# num_rows: 1000# })# })この時点で、トレーニング中にバッチごとに例を動的にパディングするデータコレータを作成することもできます。これにより、データセット全体で例をすべて同じ長さにパディングするよりも計算効率が向上します。
# データコレータの作成data_collator = DataCollatorWithPadding(tokenizer=tokenizer)評価指標
ファインチューニングされたモデルの評価方法をカスタム関数を使用して定義することができます。ここでは、モデルの正確性を計算する compute_metrics() 関数を定義しています。
# 正確性評価指標のインポートaccuracy = evaluate.load("accuracy")# trainer に渡す評価関数を定義するdef compute_metrics(p): predictions, labels = p predictions = np.argmax(predictions, axis=1) return {"accuracy": accuracy.compute(predictions=predictions, references=labels)}未訓練モデルの性能
モデルをトレーニングする前に、ランダムに初期化された分類ヘッドを持つベースモデルがいくつかの例の入力でどのようにパフォーマンスするかを評価できます。
# 例のリストtext_list = ["良かったです。", "おすすめしません。", "前作より良いです。", "これは一度も見る価値がありません。", "これはパスです。"]print("未訓練モデルの予測結果:")print("----------------------------")for text in text_list: # テキストをトークナイズ inputs = tokenizer.encode(text, return_tensors="pt") # logits を計算 logits = model(inputs).logits # logits をラベルに変換 predictions = torch.argmax(logits) print(text + " - " + id2label[predictions.tolist()])# 出力:# 未訓練モデルの予測結果:# ----------------------------# 良かったです。 - ネガティブ# おすすめしません。 - ネガティブ# 前作より良いです。 - ネガティブ# これは一度も見る価値がありません。 - ネガティブ# これはパスです。 - ネガティブ予想通り、モデルのパフォーマンスはランダムな予測と同等です。ファインチューニングでこれを改善する方法を見てみましょう。
LoRA でのファインチューニング
ファインチューニングに LoRA を使用するには、まず設定ファイルが必要です。これには LoRA アルゴリズムのすべてのパラメータが設定されます。詳細については、コードブロック内のコメントを参照してください。
peft_config = LoraConfig(task_type="SEQ_CLS", # シーケンス分類 r=4, # トレーニング可能な重み行列の固有ランク lora_alpha=32, # 学習率のようなもの lora_dropout=0.01, # ドロップアウトの確率 target_modules = ['q_lin']) # LoRA をクエリレイヤのみに適用次に、PEFT でトレーニングできる新しいバージョンのモデルを作成できます。トレーニング可能なパラメータのスケールが約100倍に減少していることに注意してください。
モデル = get_peft_model(model, peft_config)モデル.print_trainable_parameters()# trainable params: 1,221,124 || all params: 67,584,004 || trainable%: 1.8068239934408148次に、モデルトレーニングのためのハイパーパラメータを定義します。
# ハイパーパラメータlr = 1e-3 # 最適化ステップの大きさ batch_size = 4 # 1回の最適化ステップで処理される例の数num_epochs = 10 # モデルがトレーニングデータを走査する回数# トレーニング引数を定義するtraining_args = TrainingArguments( output_dir= model_checkpoint + "-lora-text-classification", learning_rate=lr, per_device_train_batch_size=batch_size, per_device_eval_batch_size=batch_size, num_train_epochs=num_epochs, weight_decay=0.01, evaluation_strategy="epoch", save_strategy="epoch", load_best_model_at_end=True,)最後に、trainer()オブジェクトを作成してモデルを微調整します!
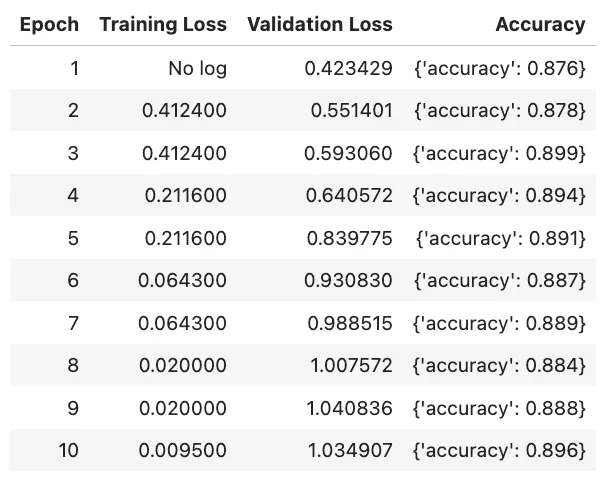
# トレーナーオブジェクトを作成するtrainer = Trainer( model=model, # 私たちのpeftモデル args=training_args, # ハイパーパラメータ train_dataset=tokenized_dataset["train"], # トレーニングデータ eval_dataset=tokenized_dataset["validation"], # バリデーションデータ tokenizer=tokenizer, # トークナイザを定義する data_collator=data_collator, # これにより、各バッチの例が等しい長さに動的にパディングされる compute_metrics=compute_metrics, # compute_metrics()関数を使用してモデルを評価する)# モデルをトレーニングするtrainer.train()上記のコードは、トレーニング中に次のメトリクスのテーブルを生成します。
トレーニングされたモデルのパフォーマンス
モデルのパフォーマンスがどのように改善されたかを確認するために、前の5つの例に適用してみましょう。
model.to('mps') # Macのmpsに移動する(代わりに'cpu'を使用することもできます)print("トレーニングされたモデルの予測:")print("--------------------------")for text in text_list: inputs = tokenizer.encode(text, return_tensors="pt").to("mps") # Macのmpsに移動する(代わりに'cpu'を使用することもできます) logits = model(inputs).logits predictions = torch.max(logits,1).indices print(text + " - " + id2label[predictions.tolist()[0]])# 出力:# トレーニングされたモデルの予測:# ----------------------------# It was good. - Positive# Not a fan, don't recommed. - Negative# Better than the first one. - Positive# This is not worth watching even once. - Negative# This one is a pass. - Positive # this one is tricky上記のコードでは、トレーニング中に90%の正確性メトリックを見たように、微調整されたモデルは前のランダムな推測よりも大幅に改善され、上記のコードの例を除いてすべて正しく分類しています。
リンク:コードリポジトリ|モデル|データセット
結論
既存のモデルを微調整するには、オートボックスを使用するよりも多くの計算リソースと技術的な専門知識が必要ですが、(より小さい)微調整されたモデルは、特定のユースケースでは(より大きな)事前学習済みベースモデルを上回る性能を発揮することがあります。さらに、オープンソースのLLMリソースが利用可能なため、カスタムアプリケーション向けにモデルを微調整することはこれまで以上に簡単になりました。
このシリーズの次の(最後の)記事では、モデルの微調整以上に進んで、ゼロから言語モデルをトレーニングする方法について説明します。
👉 LLMsについてもっと詳しく:イントロダクション | OpenAI API | Hugging Face Transformers | Prompt Engineering
リソース
連絡先:私のウェブサイト|電話を予約する|何でも聞いてください
Socials:YouTube 🎥 | LinkedIn | Twitter
サポート:コーヒーを買ってください ☕️
データ起業家
データスペースの起業家のためのコミュニティ。👉 Discordに参加してください!
VoAGI.com
[1] Deeplearning.ai ファインチューニング大規模言語モデル ショートコース: https://www.deeplearning.ai/short-courses/finetuning-large-language-models/
[2] arXiv:2005.14165 [cs.CL] (GPT-3 ペーパー)
[3] arXiv:2303.18223 [cs.CL] (LLM サーベイ)
[4] arXiv:2203.02155 [cs.CL] (InstructGPT ペーパー)
[5] 🤗 PEFT: パラメータ効率的な億単位のモデルのローリソースハードウェアでのファインチューニング: https://huggingface.co/blog/peft
[6] arXiv:2106.09685 [cs.CL] (LoRA ペーパー)
[7] オリジナルデータセットのソース — Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150, Portland, Oregon, USA. Association for Computational Linguistics.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 4/9から10/9までの週のためのトップ重要なコンピュータビジョンの論文
- ディープラーニングを使用した自動音楽生成
- 「ゼロからヒーローへ:PyTorchで最初のMLモデルを作ろう」
- 「Verbaに会ってください:自分自身のRAG検索増強生成パイプラインを構築し、LLMを内部ベースの出力に活用するためのオープンソースツール」
- 高性能意思決定のためのRLHF:戦略と最適化
- 「ResFieldsをご紹介します:長くて複雑な時間信号を効果的にモデリングするために、時空間ニューラルフィールドの制約を克服する革新的なAIアプローチ」
- ディープラーニングによる触媒性能の秘密の解明:異種触媒の高精度スクリーニングのための「グローバル+ローカル」畳み込みニューラルネットワークのディープダイブ