LLMのトレーニングの異なる方法
LLMのトレーニング方法
そしてなぜプロンプティングはそれらのいずれでもないのか
大規模言語モデル(LLM)の世界では、さまざまな目的、要件、目標を持つさまざまなトレーニングメカニズムが存在します。これらは異なる目的を果たすため、お互いを混同せず、それらが適用される異なるシナリオについて認識することが重要です。
この記事では、プリトレーニング、ファインチューニング、人間のフィードバックからの強化学習(RLHF)、およびアダプターといった最も重要なトレーニングメカニズムの概要を説明します。さらに、学習メカニズムとは見なされないプロンプティングの役割についても議論し、プロンプティングと実際のトレーニングの橋渡しをするプロンプトチューニングの概念についても解説します。
プリトレーニング
プリトレーニングは、最も基本的なトレーニング方法であり、他の機械学習の領域でのトレーニングと同等です。ここでは、トレーニングされていないモデル(つまり、ランダムに初期化された重みを持つモデル)から始めて、前のトークンのシーケンスが与えられた場合に次のトークンを予測するようにモデルをトレーニングします。このために、さまざまなソースから文の大量のコーパスを収集し、モデルに小さなチャンクで与えます。
ここで使用されるトレーニングモードは、自己教師ありと呼ばれます。トレーニングされているモデルの観点から見ると、教師あり学習アプローチと言えます。なぜなら、モデルは常に予測した後に正しい答えを得るからです。例えば、I like ice …というシーケンスが与えられた場合、モデルは次の単語としてconesを予測するかもしれず、その後、実際の次の単語がcreamであるために答えが間違っていると伝えられるかもしれません。最終的に、損失を計算し、モデルの重みを調整して次回の予測を改善します。自己教師あり(単に教師ありとは言わず)と呼ばれる理由は、事前にラベルを高価な手続きで収集する必要がなく、データにすでに含まれているためです。I like ice creamという文を自動的にI like ice(入力)とcream(ラベル)に分割することができますが、これには人間の努力は必要ありません。これを行うのはモデル自体ではありませんが、機械によって自動的に行われるため、学習プロセスで自己を監督するAIのアイデアがあります。
- 新しいAIメソッド、StyleAvatar3Dによるスタイル化された3Dアバターの生成画像テキスト拡散モデルとGANベースの3D生成ネットワークを使用
- 「OpenAIは、パーソナライズされたAIインタラクションのためのChatGPTのカスタムインストラクションを開始」
- 「CHARMに会ってください:手術中に脳がんのゲノムを解読し、リアルタイムの腫瘍プロファイリングを行う新しい人工知能AIツール」
最終的に、大量のテキストに対してトレーニングすることで、モデルは言語の一般的な構造(たとえば、I likeの後に名詞または分詞が続くことを学ぶ)や、見たテキストに含まれる知識をエンコードする方法を学びます。たとえば、Joe Biden is …という文は、しばしばアメリカ合衆国の大統領が続くことを学び、その知識の表現を持つようになるでしょう。
このプリトレーニングは既に他の人によって行われており、GPTなどのモデルをそのまま使用することができます。しかし、なぜ同様のモデルをトレーニングする必要があるのでしょうか?ゼロからモデルをトレーニングする必要が生じるのは、言語とは異なる特性を持つデータを扱う場合です。音楽の楽譜は、言語のような構造を持つ例です。どの音符が続く可能性があるかについて特定のルールやパターンがありますが、自然言語でトレーニングされたLLMではそのようなデータを扱うことができませんので、新しいモデルをトレーニングする必要があります。ただし、LLMのアーキテクチャは、音楽の楽譜と自然言語の間に多くの類似点があるため、適している場合があります。
ファインチューニング
プリトレーニング済みのLLMは、エンコードされた知識のおかげでさまざまなタスクを実行できますが、その出力の構造と、最初にデータにエンコードされていない知識の欠如という2つの主な欠点があります。
LLMは常に前のトークンのシーケンスに基づいて次のトークンを予測します。与えられたストーリーを継続するためにはこれで十分かもしれませんが、それ以外のシナリオでは望ましくない場合があります。異なる出力構造が必要な場合、2つの主な方法があります。モデルが次のトークンを予測する能力を利用してタスクを解決するようにプロンプトを記述する方法(プロンプトエンジニアリング)と、他の機械学習モデルと同様に、最後の層の出力を変更してタスクを反映させる方法があります。分類タスクを考えてみましょう。N個のクラスがある場合、プロンプトエンジニアリングでは、モデルに対して常に特定の入力の後に分類ラベルを出力させるように指示することができます。ファインチューニングでは、最後の層をN個の出力ニューロンを持つように変更し、最も活性化が高いニューロンから予測クラスを導出することができます。
LLMのもう一つの制限は、それが訓練されたデータにあります。データソースが非常に豊富であるため、最も知られているLLMは様々な共通の知識をエンコードしています。したがって、彼らは、アメリカ合衆国の大統領、ベートーヴェンの主要な作品、量子物理学の基礎、ジークムント・フロイトの主要な理論などについて話すことができます。ただし、モデルが知らないドメインもあり、そのようなドメインで作業する必要がある場合は、ファインチューニングが関連する可能性があります。
ファインチューニングのアイデアは、すでに事前学習されたモデルを取り、異なるデータでそのトレーニングを続け、トレーニング中に最後の層の重みのみを変更することです。これにより、初期のトレーニングに必要なリソースの一部しか必要とせず、より高速に実行することができます。一方で、モデルが事前トレーニング中に学習した構造は、最初の層にエンコードされたままであり、利用できます。例えば、トレーニングデータの一部ではなかったお気に入りのファンタジー小説についてモデルに教えたいとします。ファインチューニングを使用すると、モデルの一般的な自然言語の知識を活用して、新しいファンタジー小説のドメインを理解させることができます。
RLHFファインチューニング
モデルのファインチューニングの特別なケースとして、人間のフィードバックからの強化学習(RLHF)があります。これは、GPTモデルとChat-GPTのようなチャットボットの主な違いの一つです。この種のファインチューニングでは、モデルは人間との会話で最も有用と考えられる出力を生成するようにトレーニングされます。
主なアイデアは次の通りです。任意のプロンプトに対して、モデルから複数の出力が生成されます。人間はそれらの出力をプロンプトに対してどれだけ有用または適切だと判断し、それらをランク付けします。A、B、C、Dの4つのサンプルが与えられた場合、人間はCが最良の出力であり、BはDと同じくらい良く、Aがそのプロンプトに対して最も悪い出力だと判断するかもしれません。これにより、C > B = D > Aの順序が得られます。次に、このデータを使用して報酬モデルをトレーニングします。これは完全に新しいモデルであり、LLMの出力を人間の好みを反映した報酬で評価する方法を学習します。報酬モデルがトレーニングされたら、それはそのプロデュースで人間の代わりになることができます。そこで、モデルの出力は報酬モデルによって評価され、その報酬がLLMにフィードバックとして与えられ、報酬を最大化するように適応させられます。これはGANのアイデアと非常に似ています。
ご覧の通り、この種のトレーニングには人間がラベル付けしたデータが必要ですが、それにはかなりの努力が必要です。ただし、必要なデータ量は有限です。報酬モデルのアイデアは、そのデータから一般化してLLMを評価できるようにすることです。RLHFは、LLMの出力をより会話のようにしたり、モデルが意地悪で侵略的または侮辱的になることを避けるためによく使用されます。
アダプター
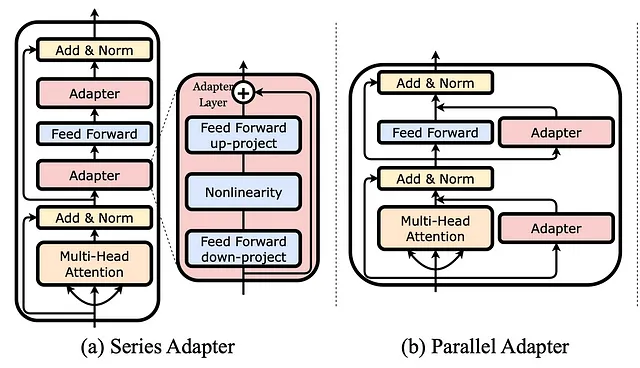
先述のファインチューニングでは、最後の層のモデルの一部のパラメータを適応させますが、前の層の他のパラメータはそのままにします。しかし、これに代わるものとして、より少ないパラメータ数でより効率的なアダプターと呼ばれる方法があります。
アダプターを使用すると、すでにトレーニングされたモデルに追加のレイヤーを追加します。ファインチューニング中には、それらのアダプターのみがトレーニングされ、モデルの他のパラメータは一切変更されません。ただし、これらのレイヤーはモデルが持っているレイヤーよりもはるかに小さいため、チューニングが容易です。さらに、これらはモデルの最後の部分だけでなく、異なる位置に挿入することもできます。上の画像では、シリアルな方法でレイヤーとしてアダプターが追加される例と、既存のレイヤーに並列に追加される例が示されています。
プロンプティング
プロンプティングは、モデルを訓練する別の方法と考えるかもしれません。プロンプティングとは、実際のモデルの入力に先行する指示を作成することを意味し、特にfew-shot-promptingを使用する場合、プロンプト内のLLMに例を提供します。これは訓練と非常に似ており、モデルに提示される例から構成されます。ただし、プロンプティングはモデルの訓練とは異なる理由があります。まず、単純な定義から、重みが更新される場合にのみ訓練と言われますが、プロンプティング中には行われません。プロンプトを作成する際には、モデルを変更せず、重みも変更せず、新しいモデルも生成せず、モデルにエンコードされた知識や表現も変更しません。プロンプティングは、LLMに指示を与え、それから何を望んでいるのかを伝える方法として考えるべきです。次のプロンプトを例として考えてみましょう:
"""与えられたテキストの感情に関して分類してください。テキスト:アイスクリームが好きです。感情:ネガティブテキスト:新しいAirPodsが本当に嫌いです。感情:ポジティブテキスト:ドナルドは地球上で最も嫌な奴です。本当に嫌いです!感情:中立テキスト:{user_input}感情:""""私はモデルに感情分類を行うように指示しましたが、お気づきのように、モデルに与えた例はすべて間違っています!もしモデルをそのようなデータで訓練した場合、ラベルのポジティブ、ネガティブ、中立を混同してしまうでしょう。では、例として与えた文「アイスクリームが好きです」をモデルに分類させた場合、どうなるでしょうか?興味深いことに、モデルはそれをポジティブと分類します。これはプロンプトとは逆ですが、意味的には正しいです。なぜなら、プロンプトはモデルを訓練せず、学習した内容を変更しません。プロンプトは、私が期待する構造、つまりコロンの後に感情ラベル(ポジティブ、ネガティブ、または中立)が続くことをモデルに伝えるだけです。
プロンプトチューニング
プロンプト自体はLLMの訓練ではありませんが、プロンプティングに関連するメカニズムであるプロンプトチューニング(またはソフトプロンプティング)というものがあり、それは一種の訓練と見なすことができます。
前の例では、プロンプトを実際の入力の前にモデルに与えられる自然言語テキストと見なしました。つまり、モデルの入力は<prompt><instance>となります。例えば、<ラベル以下をポジティブ、ネガティブ、または中立にする:> <アイスクリームが好きです>となります。自分でプロンプトを作成する場合は、ハードプロンプティングと言います。ソフトプロンプティングでは、形式は<prompt><instance>のままですが、プロンプト自体は自分で設計するのではなく、データを学習して学習します。詳細については、プロンプトはベクトル空間内のパラメータで構成され、これらのパラメータは訓練中にチューニングされて損失を小さくし、より良い回答を得るために使用されます。つまり、訓練後、プロンプトは与えられたデータに対して最も良い回答につながる文字列のシーケンスになります。ただし、モデルのパラメータ自体は全く訓練されません。
プロンプトチューニングの大きな利点は、異なるタスクに対して複数のプロンプトを訓練できるが、同じモデルで使用できることです。ハードプロンプティングと同様に、テキスト要約のための1つのプロンプト、感情分析のためのもう1つのプロンプト、テキスト分類のためのもう1つのプロンプトを構築することがありますが、すべて同じモデルで使用することができます。逆に、ファインチューニングを使用した場合、各タスクに対して特定のモデルのみを提供することになります。
まとめ
さまざまなトレーニングメカニズムを見てきましたので、最後に簡単なまとめをしましょう。
- LLMの事前学習は、自己教師ありの方法で次のトークンを予測するように教えることを意味します。
- ファインチューニングは、事前学習済みLLMの重みを最後の層に適応させることであり、モデルを特定の文脈に適応させるために使用できます。
- RLHFは、モデルの振る舞いを人間の期待に合わせて適応させることを目指し、追加のラベリング作業が必要です。
- アダプタは、事前学習済みLLMに追加される小さな層により、ファインチューニングをより効率的に行うことができます。
- プロンプティングは、モデルの内部表現を変更しないため、トレーニングそのものとは考えられていません。
- プロンプトチューニングは、プロンプトを生成するための重みを調整するテクニックであり、モデルの重み自体には影響しません。
もちろん、他にもさまざまなトレーニングメカニズムがあり、新しいものが毎日発明されています。LLMはテキストを予測するだけでなく、さまざまなスキルと技術を必要とします。私がご紹介したものの一部です。
さらなる読み物
Instruct-GPTは、RLHFの最も有名な例の1つです:
- https://openai.com/research/instruction-following
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., … & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 27730–27744.
アダプタの一般的な形式の概要は、LLM-Adaptersプロジェクトで見つけることができます:
- https://github.com/AGI-Edgerunners/LLM-Adapters
- Hu, Z., Lan, Y., Wang, L., Xu, W., Lim, E. P., Lee, R. K. W., … & Poria, S. (2023). LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models. arXiv preprint arXiv:2304.01933.
プロンプトチューニングは、次の場所で探求されています:
- Lester, B., Al-Rfou, R., & Constant, N. (2021). The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691.
プロンプトチューニングの詳しい説明は、次の場所で見つけることができます:
- https://huggingface.co/docs/peft/conceptual_guides/prompting
- https://ai.googleblog.com/2022/02/guiding-frozen-language-models-with.html
この記事が気に入ったら、私をフォローして将来の投稿をお知らせください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「SwiggyがZomatoとBlinkitに続き、生成AIを統合する」
- 「私たちはLLMがツールを使うことを知っていますが、LLMが新しいツールを作ることもできることを知っていますか? LLMツールメーカー(LATM)としての出会い:LLMが自分自身の再利用可能なツールを作ることを可能にするクローズドループシステム」
- 類似検索、パート6:LSHフォレストによるランダム射影
- このAI論文では、「Retentive Networks(RetNet)」を大規模言語モデルの基礎アーキテクチャとして提案していますトレーニングの並列化、低コストの推論、そして良好なパフォーマンスを実現しています
- マルチディフュージョンによる画像生成のための統一されたAIフレームワーク、事前学習されたテキストから画像へのディフュージョンモデルを使用して、多目的かつ制御可能な画像生成を実現します
- 「機械学習モデルのバリデーション方法」
- メタの戦略的な優れた点:Llama 2は彼らの新しいソーシャルグラフかもしれません





