「LLMはどのようにテキストを生成するのか?」
LLMのテキスト生成方法は?
この記事ではトランスフォーマーや大規模な言語モデルのトレーニングについては議論しません。代わりに、事前学習済みモデルの使用に集中します。
すべてのコードはGithubとColabで提供されます
テキスト生成の概要を見てみましょう。

- 入力テキストは、トークン化器に渡され、各トークンには一意の数値表現が割り当てられたトークンIDの出力が生成されます。
- トークン化された入力テキストは、事前学習済みモデルのエンコーダ部に渡されます。エンコーダは入力を処理し、入力の意味と文脈をエンコードする特徴表現を生成します。エンコーダは大量のデータでトレーニングされており、それを活用しています。
- デコーダは、エンコーダからの特徴表現を受け取り、その文脈に基づいてトークンごとに新しいテキストを生成し始めます。以前に生成されたトークンを使用して新しいトークンを作成します。
今日は、3番目のステップに焦点を当てます-デコードとテキストの生成。最初の2つのステップに興味がある場合は、以下にコメントしてください。それらのトピックについても検討します。
出力のデコード
さて、もう少し詳しく見てみましょう。例えば、「パリは都市です…」というフレーズの続きを生成したいとします。エンコーダ(私たちはBloom-560mモデルを使用します(コメントのリンク先のコード))は、持っているすべてのトークンに対してロジット(スコアと考えられるもの)を送信します。ロジットはソフトマックス関数を使用して、トークンが生成のために選択される確率に変換できます。

上位5つの出力トークンを見ると、すべて意味があります。次のような合法的なフレーズを生成することができます:
- パリは愛の都市です。
- パリは眠らない都市です。
- パリは芸術と文化が繁栄する都市です。
- パリは象徴的な名所のある都市です。
- パリは歴史にユニークな魅力を持つ都市です。
課題は、適切なトークンを選択することです。そのためには、いくつかの戦略があります。
貪欲サンプリング
単純に言えば、貪欲戦略では、モデルは常に各ステップで最も確率が高いと信じるトークンを選択します-他の可能性を考慮したり、異なるオプションを試したりしません。モデルは最も確率が高いトークンを選択し、選択した選択肢に基づいてテキストの生成を続けます。

貪欲戦略を使用することは計算的に効率的で簡単ですが、時には繰り返しや過度に決定論的な出力を得るというコストがかかります。モデルは各ステップで最も確率が高いトークンのみを考慮するため、文脈や言語の豊かさを十分に捉えることができず、最も創造的な応答を生成することができないかもしれません。モデルの視野は短期的であり、各ステップで最も確率が高いトークンに焦点を当てるため、シーケンス全体に対する全体的な影響を無視します。
生成された出力:パリは未来の都市です。
ビームサーチ
ビームサーチは、テキスト生成で使用される別の戦略です。ビームサーチでは、モデルは各ステップで最も確率が高いトークンだけでなく、上位の「k」個の最も確率が高いトークンのセットを仮定します。このk個のトークンのセットは「ビーム」と呼ばれます。

モデルは各ビームの可能なシーケンスを生成し、各ビームの各ステップでの確率を追跡します。このプロセスは、生成されたテキストの目的の長さに達するか、各ビームに対して「終了」トークンが出現するまで続きます。モデルは、すべてのビームから最も全体的な確率が高いシーケンスを最終出力として選択します。
アルゴリズムの観点から見ると、ビームの作成はk-aryツリーの展開です。ビームを作成した後、最も全体の確率が高い枝を選択します。
生成された出力:パリは歴史と文化の都市です。
正規ランダムサンプリングまたは確率の直接使用

アイデアはシンプルです – ランダムな値を選択し、それをトークンにマッピングして次の単語を選択します。各トークンの領域は確率によって定義される、車輪を回すことと想像してください。確率が高いほど、トークンが選択される可能性が高くなります。それは比較的安価な計算上の解決策であり、高い相対的なランダム性により、文(またはトークンのシーケンス)はおそらく毎回異なるものになります。

温度を使用したランダムサンプリング
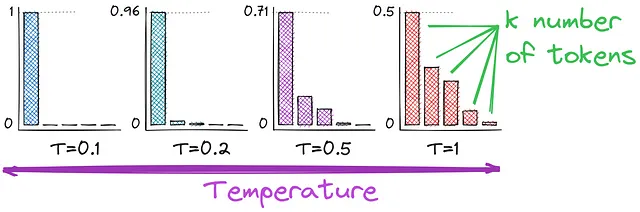
おそらく思い出すかもしれませんが、ロジットを確率に変換するためにソフトマックス関数を使用しています。そして、ここでは温度を導入します – テキスト生成のランダム性に影響を与えるハイパーパラメータです。温度がどのように確率の計算に影響を与えるかをよりよく理解するために、活性化関数を比較してみましょう。

お気づきかもしれませんが、分母が異なります – Tで割ります。温度の値が高い(例:1.0)ほど、出力はより多様になります。一方、値が低い(例:0.1)ほど、より焦点が絞られ、決定論的になります。 T = 1は最初に使用したソフトマックス関数になります。
Top-kサンプリング
温度で確率を調整することができます。もう一つの強化策は、すべてのトークンではなく、上位k個のトークンを使用することです。これにより、テキスト生成の安定性が向上し、創造性があまり低下しません。これは、上位k個のトークンのランダムサンプリングに温度を使用するものです。唯一の懸念事項は、kの数を選択することであり、以下に改善方法を示します。
核サンプリングまたは上位pサンプリング
トークンの確率分布は非常に異なる場合があり、テキスト生成中に予期しない結果をもたらす可能性があります。

核サンプリングは、さまざまなサンプリング手法の制限に対処するために設計されています。検討するトークンの固定数”k”を指定する代わりに、確率の閾値”p”を使用します。この閾値は、サンプリングに含めたい累積確率を表します。モデルは各ステップで可能なすべてのトークンの確率を計算し、降順でソートします。

モデルは、確率の合計が指定された閾値を超えるまで生成されたテキストにトークンを追加し続けます。核サンプリングの利点は、コンテキストに基づいたより動的で適応的なトークンの選択が可能になることです。各ステップで選択されるトークンの数は、そのコンテキストのトークンの確率に応じて異なる場合があります。これにより、より多様で高品質な出力が得られる可能性があります。
結論
デコーディング戦略は、特に事前学習済みの言語モデルを使用したテキスト生成において重要です。考えてみると、確率を定義する方法はいくつかあり、それらの確率を使用する方法もいくつかあり、考慮するトークンの数を決定する方法も少なくとも2つあります。以下に知識をまとめるための要約表を示します。
温度はデコーディング中のトークンの選択のランダム性を制御します。温度が高いほど創造性が高まり、温度が低いほど連続性と構造が重視されます。創造性を受け入れることで魅力的な言語的冒険が可能になりますが、安定性を保つことで生成されたテキストのエレガンスが確保されます。
イラストと記事の内容を楽しんでいただけたら、あなたのサポートをいただけると嬉しいです。次回までお楽しみください!

この記事は私のLinkedInページで最初に公開されました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






