「Llama 2によるトピックモデリング」
Llama 2 Topic Modeling

大規模言語モデルを使用して、簡単に解釈可能なトピックを作成する
Llama 2の登場により、ローカルで強力なLLMを実行することがますます現実のものになってきました。その精度はOpenAIのGPT-3.5に匹敵し、多くのユースケースに適しています。
この記事では、個々の文書をモデルに渡す必要がないまま、LLama2をトピックモデリングに使用する方法を探っていきます。その代わりに、トピック表現を微調整するために、任意のLLMを使用できるモジュラートピックモデリング技術であるBERTopicを利用します。
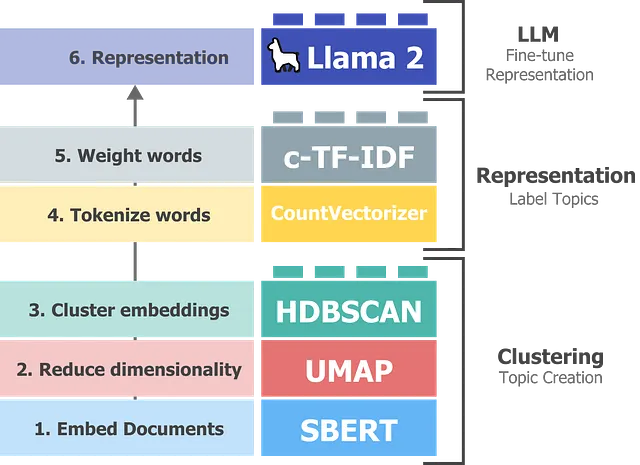
BERTopicは非常にシンプルな仕組みです。以下の5つの手順で構成されます:
- 「2023年にPrompt Engineeringを使用するであろう5つの仕事」
- この無料のeBookでMLOpsの基礎を学びましょう
- 「IDEFICSをご紹介します:最新の視覚言語モデルのオープンな再現」
- 文書の埋め込み
- 埋め込みの次元削減
- 次元削減された埋め込みのクラスタリング
- クラスタごとの文書のトークン化
- クラスタごとの最適な単語の抽出

ただし、Llama 2のようなLLMの台頭により、トピックごとに独立した単語の集まりよりも優れた結果を得ることができます。すべての文書を直接Llama 2に渡して分析させることは計算上の制約があります。ベクトルデータベースを使用して検索することもできますが、どのトピックを検索するかは完全にわかりません。
その代わりに、BERTopicによって作成されたクラスタとトピックを活用し、Llama 2がその情報をより正確に微調整および蒸留することができます。
これは、BERTopicによるトピックの作成とLlama 2によるトピック表現の両方の最良の結果です。
このイントロが終わったので、実践的なチュートリアルを始めましょう!
この例で使用するいくつかのパッケージをインストールしていきましょう:
pip install bertopic datasets accelerate bitsandbytes xformers adjustTextこの例を実行するためには、少なくともT4 GPUが必要ですので、ご注意ください…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






