「Llama 2がコーディングを学ぶ」
Llama 2 learns coding.
イントロダクション
Code Llamaは、コードタスクに特化した最新のオープンアクセスバージョンであり、Hugging Faceエコシステムでの統合をリリースすることに興奮しています! Code Llamaは、Llama 2と同じ許容されるコミュニティライセンスでリリースされ、商業利用が可能です。
今日、私たちは以下をリリースすることに興奮しています:
- モデルカードとライセンスを備えたHub上のモデル
- Transformersの統合
- 高速かつ効率的な本番用推論のためのテキスト生成推論との統合
- 推論エンドポイントとの統合
- コードのベンチマーク
Code LLMは、ソフトウェアエンジニアにとってのエキサイティングな開発です。IDEでのコード補完により生産性を向上させることができ、ドックストリングの記述などの繰り返しや面倒なタスクを処理することができ、ユニットテストを作成することもできます。
目次
- イントロダクション
- 目次
- Code Llamaとは?
- Code Llamaの使い方
- デモ
- Transformers
- コード補完
- コードインフィリング
- 対話的な指示
- 4ビットローディング
- text-generation-inferenceとInference Endpointsの使用
- 評価
- 追加リソース
Code Llamaとは?
Code Llamaのリリースにより、7, 13, 34兆パラメータのモデルファミリーが導入されました。ベースモデルはLlama 2から初期化され、その後、500兆トークンのコードデータでトレーニングされました。メタはこれらのベースモデルを2つの異なるフレーバー用にメタファインチューニングしました:Pythonの専門家(追加の100兆トークン)と、自然言語の指示を理解できるようにした指示ファインチューニングバージョンです。
これらのモデルは、Python、C++、Java、PHP、C#、TypeScript、Bashで最先端のパフォーマンスを示しています。7Bと13Bのベースモデルとインストラクトバリアントは、周囲のコンテンツに基づいたインフィリングをサポートしており、コードアシスタントとしての使用に最適です。
Code Llamaは16kのコンテキストウィンドウでトレーニングされました。さらに、3つのモデルバリアントは追加の長いコンテキストファインチューニングを行い、最大100,000トークンのコンテキストウィンドウを扱うことができるようにしました。
Llama 2の4kのコンテキストウィンドウをCode Llamaの16kに拡大する(最大で100kまで推測できる)ことは、RoPEスケーリングの最近の進展により可能になりました。コミュニティは、Llamaの位置エンベディングを線形補間または周波数領域で補間できることを見つけ、ファインチューニングを介したより大きなコンテキストウィンドウへの移行を容易にすることができました。Code Llamaの場合、周波数領域スケーリングはスラックを持って行われます:ファインチューニングの長さは、スケーリングされた事前学習の長さの一部であり、モデルに強力な推測能力を与えます。
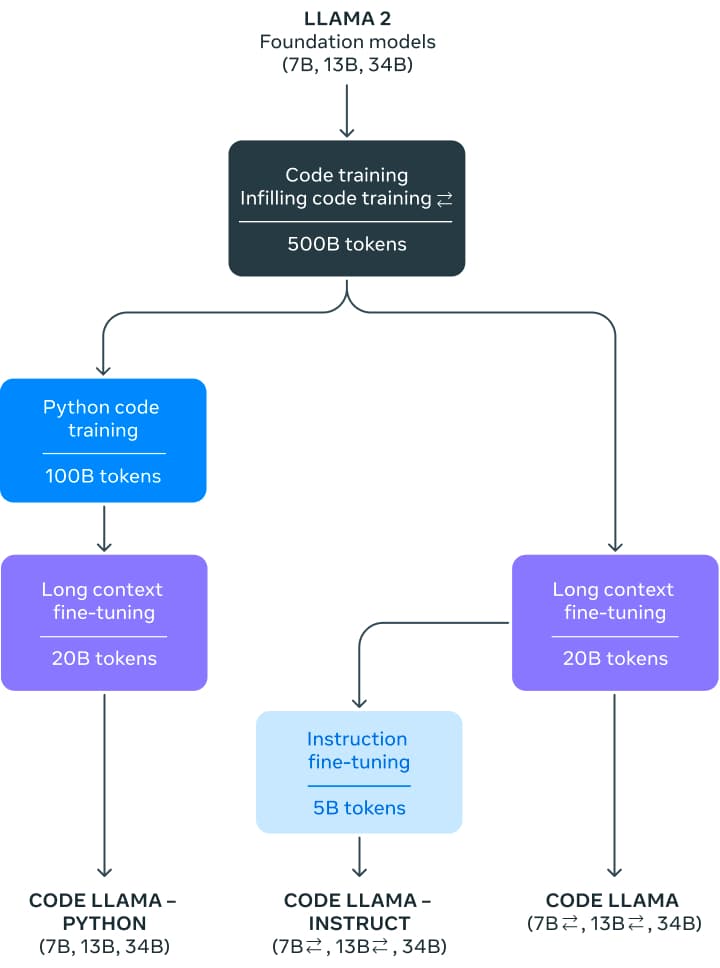
すべてのモデルは、最初に公開されているコードのデータセットの非重複データセット上で500兆トークンでトレーニングされました。データセットにはコードに関する議論やコードスニペットなどの自然言語データセットも含まれています。残念ながら、データセットについての詳細情報はありません。
指示モデルでは、Llama 2 Chatのために収集された指示チューニングデータセットと自己指示データセットの2つのデータセットを使用しました。自己指示データセットは、Llama 2を使用して面接プログラミングの質問を作成し、その後、Code Llamaを使用してユニットテストとソリューションを生成し、テストを実行して評価することで作成されました。
Code Llamaの使い方
Code Llamaは、Hugging Faceエコシステムで利用できます。 transformersバージョン4.33から利用できます。 transformers 4.33がリリースされるまで、メインブランチからインストールしてください。
デモ
このデモでは、Code Llamaモデル(1300億パラメータ!)をこのスペースまたは以下の埋め込みプレイグラウンドで簡単に試すことができます:
このプレイグラウンドでは、Hugging FaceのText Generation Inferenceを使用しています。これはHuggingChatのパワーを提供する同じ技術です。詳細は以下のセクションで共有します。
Transformers
次期リリースのtransformers 4.33では、Code Llamaを使用し、HFエコシステム内のすべてのツールを活用することができます。
- トレーニングおよび推論スクリプトと例
- 安全なファイル形式(
safetensors) bitsandbytes(4ビットの量子化)およびPEFT(パラメータ効率の向上)などのツールとの統合- モデルを使用しての生成を実行するためのユーティリティとヘルパー
- モデルをデプロイするためのエクスポート機構
transformers 4.33がリリースされるまで、メインブランチからインストールしてください。
!pip install git+https://github.com/huggingface/transformers.git@main accelerateコード補完
7Bおよび13Bモデルはテキスト/コードの補完や補充に使用できます。次のコードスニペットは、テキストの補完をデモンストレーションするためにpipelineインターフェースを使用します。GPUランタイムを選択する限り、Colabの無料ティアで実行できます。
from transformers import AutoTokenizer
import transformers
import torch
tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
pipeline = transformers.pipeline(
"text-generation",
model="codellama/CodeLlama-7b-hf",
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'def fibonacci(',
do_sample=True,
temperature=0.2,
top_p=0.9,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=100,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")これにより、次のような出力が生成される場合があります:
Result: def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
if n == 0:
return 0
elif n == 1:
returnCode Llamaはコード理解に特化していますが、それ自体は言語モデルです。同じ生成戦略を使用してコメントや一般的なテキストの自動補完にも使用できます。
コードの補充
これはコードモデルに特化したタスクです。モデルは、既存の接頭辞と接尾辞に最も適合するコード(コメントを含む)を生成するように訓練されています。これは通常、コードアシスタントが使用する戦略です: 現在のカーソル位置を埋めるように求められ、それより前と後に表示される内容を考慮します。
このタスクは、7Bおよび13Bモデルのbaseおよびinstructionバリアントで利用可能です。34BモデルやPythonバージョンでは利用できません。
この機能を正常に使用するには、このタスクのためにモデルのトレーニングに使用されるフォーマットに注意を払う必要があります。特別な区切り文字を使用してプロンプトの異なる部分を識別します。以下に例を見てみましょう:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16
).to("cuda")
prefix = 'def remove_non_ascii(s: str) -> str:\n """ '
suffix = "\n return result\n"
prompt = f"<PRE> {prefix} <SUF>{suffix} <MID>"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=False,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))
<s> <PRE> def remove_non_ascii(s: str) -> str:
""" <SUF>
return result
<MID>
Remove non-ASCII characters from a string.
:param s: The string to remove non-ASCII characters from.
:return: The string with non-ASCII characters removed.
"""
result = ""
for c in s:
if ord(c) < 128:
result += c <EOT></s>完了を使用するためには、<MID>と<EOT>トークンの間のテキストを切り取って出力を処理する必要があります。それが私たちが提供した接頭辞と接尾辞の間に入るものです。
会話の指示
ベースモデルは補完とインフィリングの両方に使用できます。Code Llamaリリースには、会話型インターフェースで使用できる指示の微調整モデルも含まれています。
このタスクの入力を準備するには、Llama 2ブログ投稿で説明されているようなプロンプトテンプレートを使用する必要があります。ここで再度再現します:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST]システムプロンプトはオプションです – モデルはそれなしでも動作しますが、ここでその動作やスタイルをさらに設定するために使用することができます。たとえば、JavaScriptで常に回答を取得したい場合は、ここで指定することができます。システムプロンプトの後には、会話で前のインタラクションですべての以前の質問とモデルの回答を提供する必要があります。インフィリングの場合と同様に、使用されるデリミタに注意する必要があります。入力の最終コンポーネントは常に新しいユーザーの指示でなければならず、それがモデルに回答を提供する信号となります。
次のコードスニペットは、テンプレートが実際にどのように機能するかを示しています。
- 最初のユーザークエリ、システムプロンプトなし
user = 'Bashで、直近1ヶ月以内に変更された(サブディレクトリを除く)現在のディレクトリのテキストファイルをすべてリストする方法は?'
prompt = f"<s>[INST] {user.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")- 最初のユーザークエリ、システムプロンプト付き
system = "JavaScriptで回答を提供"
user = "与えられたリストのすべての連続したサブリストの和を計算する関数を書いてください。"
prompt = f"<s><<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")- 以前の回答を含む進行中の会話
このプロセスはLlama 2と同じです。最大の明瞭さのために、この例のコードをループや一般化はしていません:
system = "システムプロンプト"
user_1 = "ユーザープロンプト_1"
answer_1 = "回答_1"
user_2 = "ユーザープロンプト_2"
answer_2 = "回答_2"
user_3 = "ユーザープロンプト_3"
prompt = f"<<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user_1}"
prompt = f"<s>[INST] {prompt.strip()} [/INST] {answer_1.strip()} </s>"
prompt += f"<s>[INST] {user_2.strip()} [/INST] {answer_2.strip()} </s>"
prompt += f"<s>[INST] {user_3.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")4ビットローディング
TransformersでのCode Llamaの統合により、4ビットローディングなどの高度な機能をすぐにサポートできます。これにより、nvidia 3090カードなどのコンシューマーGPUで大きな32Bパラメーターモデルを実行することができます!
以下に4ビットモードで推論を実行する方法を示します:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
model_id = "codellama/CodeLlama-34b-hf"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto",
)
prompt = 'def remove_non_ascii(s: str) -> str:\n """ '
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=True,
top_p=0.9,
temperature=0.1,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))テキスト生成推論と推論エンドポイントの使用
テキスト生成推論は、Hugging Faceが開発した本番利用可能な推論コンテナであり、大規模な言語モデルの簡単なデプロイを実現します。連続バッチ処理、トークンストリーミング、複数のGPUでの高速推論のためのテンソル並列処理、本番利用可能なログ記録とトレースなどの機能があります。
テキスト生成推論を独自のインフラストラクチャで試すこともできますし、Hugging Faceの推論エンドポイントを使用することもできます。Codellama 2モデルをデプロイするには、モデルページに移動し、「Deploy -> Inference Endpoints」ウィジェットをクリックします。
- 7Bモデルの場合、”GPU [VoAGI] – 1x Nvidia A10G”を選択することをお勧めします。
- 13Bモデルの場合、”GPU [xlarge] – 1x Nvidia A100″を選択することをお勧めします。
- 34Bモデルの場合、”GPU [1xlarge] – 1x Nvidia A100″(bitsandbytesクォンタイゼーションを有効にする)または”GPU [2xlarge] – 2x Nvidia A100″を選択することをお勧めします。
注意:A100にアクセスするためには、メールでクオータのアップグレードをリクエストする必要がある場合があります。[email protected]までお問い合わせください。
Hugging Face推論エンドポイントを使用してLLMをデプロイする方法については、ブログで詳しく説明しています。このブログには、サポートされているハイパーパラメータと、PythonとJavascriptを使用してレスポンスをストリーミングする方法についての情報も含まれています。
評価
コードの言語モデルは、通常、HumanEvalなどのデータセット上でベンチマークテストされます。これは、モデルに関数のシグネチャとドキュメント文字列が提示され、関数の本体を完成させるタスクが与えられます。提案された解決策は、事前に定義されたユニットテストを実行して検証されます。最終的には、テストをすべてパスした解決策の割合が報告されます。pass@1率は、1回の試行で合格する解決策を生成する頻度を、pass@10率は、10個の候補のうち少なくとも1つの解決策が合格する頻度を示します。
HumanEvalはPythonのベンチマークですが、それを他のプログラミング言語に翻訳し、より包括的な評価を可能にするための重要な取り組みが行われています。そのようなアプローチの一つがMultiPL-Eであり、HumanEvalを12以上の言語に翻訳しています。私たちは、それに基づいた多言語のコードリーダーボードをホストしています。これにより、コミュニティは異なる言語間でモデルを比較し、自分のユースケースに最適なモデルを評価することができます。
注意:上記の表に表示されているスコアは、同じ設定ですべてのモデルを評価したコードリーダーボードから取得されています。詳細については、リーダーボードを参照してください。
追加リソース
- ハブ上のモデル
- 論文ページ
- 公式メタの発表
- 責任ある使用ガイド
- デモ
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






