線形回帰と勾配降下法
Linear Regression and Gradient Descent.
最も基本的な機械学習アルゴリズムについて学ぶ
線形回帰は、機械学習に存在する基本的なアルゴリズムの1つです。内部のワークフローを理解することで、データサイエンスの他のアルゴリズムの主要なコンセプトを把握するのに役立ちます。線形回帰は、連続変数を予測するために使用される広範囲なアプリケーションがあります。
線形回帰の内部機能に潜り込む前に、まず回帰問題を理解しましょう。
導入
回帰は、通常x = <x₁、x₂、x₃、…、xₙ>と示される特徴ベクトルが与えられたときに、連続変数の値を予測する機械学習問題です。モデルが予測を行うためには、特徴ベクトルxから対応する目標変数yの値へのマッピングを含むデータセットでトレーニングする必要があります。学習プロセスは、特定のタスクに使用されるアルゴリズムのタイプに依存します。
- Boto3 vs AWS Wrangler PythonによるS3操作の簡素化
- 非教師あり学習シリーズ:階層クラスタリングの探索
- Rendered.aiは、合成データの生成にNVIDIA Omniverseを統合します

線形回帰の場合、モデルは重みベクトルw = <x₁、x₂、x₃、…、xₙ>とバイアスパラメータbを学習し、目標値yを<w、x> + b = x₁ * w₁ + x₂ * w₂ + x₃ * w₃ + … + xₙ * wₙ + bで近似します。これは、最良のデータセット観察(x、y)に対して行われます。
公式化
線形回帰モデルを構築する場合、最終的な目標は、予測値ŷを実際の目標値yにより近づける重みベクトルwとバイアス項bを見つけることです。つまり、すべての入力に対して次のように方程式を書き直します。
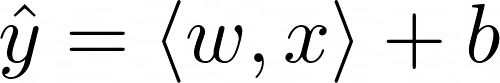
例として、単一の特徴xを持つデータセットを使用します。したがって、xとwは1次元ベクトルです。内積表記を簡単にするために、上記の方程式を次のように書き直します。
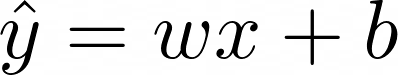
損失関数
アルゴリズムをトレーニングするために、損失関数を選択する必要があります。損失関数は、単一のトレーニングイテレーションでオブジェクトセットの予測をどの程度良くまたは悪くしたかを測定します。その値に基づいて、アルゴリズムはモデルのパラメータを調整し、将来的にはモデルが誤差を少なく生み出すようにします。
最も一般的な損失関数の1つは平均二乗誤差(MSE)で、予測値と真の値の間の平均平方偏差を測定します。
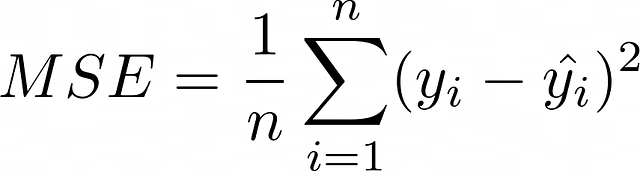
勾配降下法
勾配降下法(Gradient descent)は、局所最小値を探索することによって、与えられた損失関数を最小化するための重みベクトルの反復的なアップデートアルゴリズムです。勾配降下法は、各反復で以下の式を使用します:
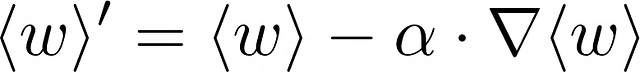
- <w> は現在の反復でのモデルの重みベクトルです。計算された重みは <w> に割り当てられます。アルゴリズムの最初の反復では、重みは通常ランダムに初期化されますが、他の戦略が存在します。
- α は通常、小さな正の値であり、学習率として知られています。これは、局所最小値を探索する速度を制御するハイパーパラメータです。
- 反転した三角形は勾配を表します。これは、損失関数の偏微分のベクトルです。この例では、重みのベクトルは2つの要素から構成されています。したがって、<w> の勾配を計算するには、2つの偏微分(f は損失関数を表します)が計算される必要があります。
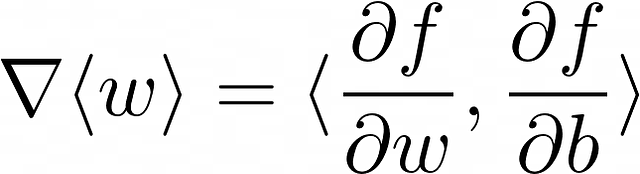
アップデート式は、次のように書き換えることができます:

現在の目標は、f の偏微分を見つけることです。MSE が損失関数として選択された場合、単一の観測値(MSE 式で n = 1)に対して計算しましょう。したがって、f = (y — ŷ)² = (y — wx — b)² です。
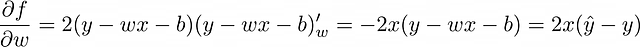
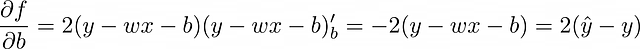
単一のオブジェクトに基づいてモデルの重みを調整するプロセスを、確率的勾配降下法(stochastic gradient descent)と呼びます。
バッチ勾配降下法
前述のセクションでは、モデルパラメータは単一のオブジェクトの MSE を計算することによって更新されました(n = 1)。実際には、単一の反復で複数のオブジェクトに対して勾配降下を実行することができます。この重みの更新方法を、バッチ勾配降下法と呼びます。
この場合に重みを更新するための式は、前のセクションの確率的勾配降下法と非常に似ています。唯一の違いは、ここではオブジェクトの数 n を考慮する必要があることです。最終的には、バッチ内のすべてのオブジェクトの項の合計が計算され、n(バッチサイズ)で除算されます。
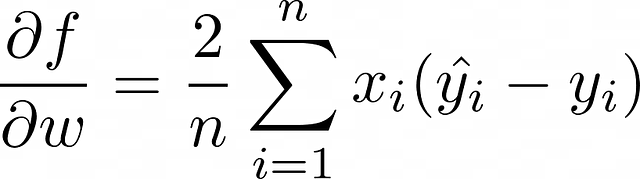
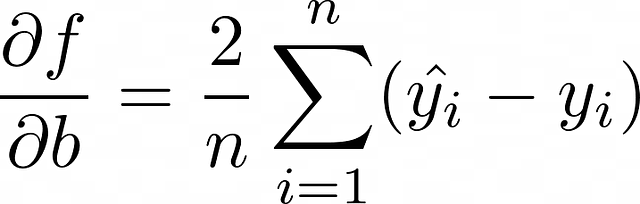
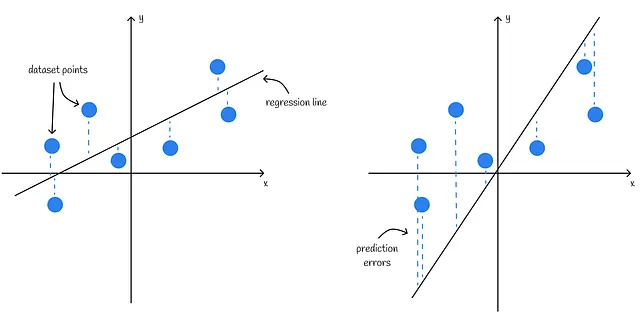
可視化
単一の特徴量のデータセットを扱う場合、回帰結果は簡単に2Dプロット上で視覚化できます。水平軸は特徴量の値を表し、垂直軸は目標値を含みます。
線形回帰モデルの品質は、データセットの点にどの程度密着しているかによって視覚的に評価できます。すべてのデータセットの点と線の平均距離が近いほど、アルゴリズムの品質が向上します。
データセットにより多くの特徴が含まれている場合、PCAやt-SNEなどの次元削減技術を使用して特徴を低次元で表現し、新しい特徴を2Dまたは3Dプロットにプロットすることができます。
分析
線形回帰にはいくつかの利点があります:
- トレーニング速度。アルゴリズムの単純さにより、より複雑な機械学習アルゴリズムと比較して線形回帰は迅速にトレーニングできます。さらに、比較的高速で理解しやすいLSM法を介して実装することもできます。
- 解釈可能性。複数の特徴に対して構築された線形回帰方程式は、特徴の重要性に関して簡単に解釈できます。係数の値が高いほど、最終的な予測に対する影響が大きくなります。
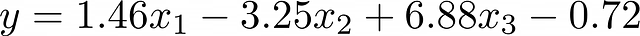
一方で、いくつかの欠点もあります:
- データの仮定。線形回帰モデルを適合させる前に、出力と入力特徴量の依存関係のタイプを確認することが重要です。線形である場合は、適合させるのに問題はありません。それ以外の場合は、方程式には線形項しかないため、モデルはデータに適合しにくくなります。実際には、方程式に高次数を追加してアルゴリズムを多項式回帰に変換することができます。ただし、現実には、ドメイン知識が十分にない場合は、依存関係のタイプを正確に予測することが難しいことがあります。これが線形回帰が与えられたデータに適応しない理由の1つです。
- 多重共線性の問題。多重共線性は、2つ以上の予測子が互いに高度に相関している場合に発生します。1つの変数の変化が他の変数に影響を与える状況を想像してください。しかし、トレーニングされたモデルにはその情報がありません。これらの変化が大きいと、未知のデータに対する推論フェーズでモデルが安定しなくなるため、過学習の問題が発生します。さらに、最終的な回帰係数もこれにより解釈が不安定になる可能性があります。
- データの正規化。線形回帰を特徴量の重要性ツールとして使用するためには、データを正規化または標準化する必要があります。これにより、すべての最終回帰係数が同じスケールになり、正しく解釈できます。
結論
線形回帰を見てきました。これは、機械学習において非常にポピュラーなアルゴリズムです。その基本原理は、より複雑なアルゴリズムにも使用されます。
線形回帰は現代のプロダクションシステムではめったに使用されませんが、その単純さにより、回帰問題の標準的な基準として使用され、より洗練されたソリューションと比較されます。
この記事で使用されたソースコードはこちらから入手できます:
ML-VoAGI/linear_regression.ipynb at master · slavafive/ML-VoAGI
この時点でその操作を実行できません。別のタブまたはウィンドウでサインインしました。別のタブまたはウィンドウでサインアウトしました。
github.com
リソース
- 最小二乗法 | Wikipedia
- 多項式回帰 | Wikipedia
すべての画像は、特に記載がない限り著者によるものです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
