機械学習におけるバイアスについて話しましょう!倫理と社会に関するニュースレター #2
Let's talk about bias in machine learning! Ethics and Society Newsletter #2.
機械学習におけるバイアスは普遍的であり、また複雑です。実際には、単一の技術的介入では問題を意味のある形で解決することはできないほど複雑です。機械学習モデルは社会技術システムであり、その展開コンテキストに依存し、常に進化しながら、不平等や有害なバイアスを悪化させる社会的な傾向を増幅させます。
これは、慎重に機械学習システムを開発するためには警戒心が必要であり、展開コンテキストからのフィードバックに対応することが求められます。これには、コンテキスト間での教訓の共有や、機械学習開発のあらゆるレベルでバイアスの兆候を分析するためのツールの開発などが必要です。
このブログポストでは、Ethics and Societyのメンバーが学んだ教訓と、機械学習におけるバイアスに対処するために開発したツールを共有しています。最初の部分では、バイアスとそのコンテキストについて幅広く考察しています。既に読んでいて、具体的にツールについて戻ってきた場合は、データセットやモデルのセクションに移動してください!
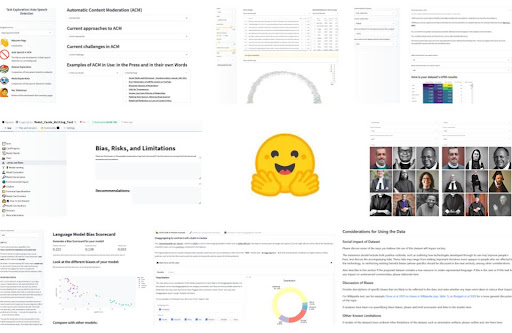 機械学習におけるバイアスに対処するために🤗のチームメンバーが開発したツールの一部を選択
機械学習におけるバイアスに対処するために🤗のチームメンバーが開発したツールの一部を選択
目次:
- 機械バイアスについて
- 機械バイアス:機械学習システムからリスクへ
- バイアスをコンテキストに置く
- ツールと推奨事項
- 機械学習開発全体でのバイアスの対処
- タスクの定義
- データセットのキュレーション
- モデルのトレーニング
- 🤗のバイアスツールの概要
- 機械学習開発全体でのバイアスの対処
機械バイアス:機械学習システムから個人および社会的なリスクへ
機械学習システムは、さまざまなセクターやユースケースで展開されるため、以前に見たことのないスケールで複雑なタスクを自動化することができます。技術が最も効果的に機能する場合、人々と技術システムの間の相互作用をスムーズにし、高度に繰り返しの多い作業の必要性をなくしたり、研究をサポートするための情報処理の新しい方法を開放することができます。
しかし、同じシステムは、特にデータが人間の行動をエンコードする場合、差別的で虐待的な行動を再現する可能性があります。その結果、これらの問題は大幅に悪化する可能性があります。自動化とスケール展開は、次のようなことができます:
- 時間の経過とともに行動を固定化し、社会的な進歩が技術に反映されるのを妨げる
- オリジナルのトレーニングデータのコンテキストを超えて有害な行動を広める
- 予測を行う際にステレオタイプな関連性に過度に焦点を当てて不公平を増幅させる
- バイアスを「ブラックボックス」システム内に隠すことで救済の可能性を排除する
これらのリスクをよりよく理解し対処するために、機械学習の研究者や開発者は、機械バイアスやアルゴリズムのバイアスなど、システムが展開コンテキストでさまざまな人口集団に対して負のステレオタイプや関連性をエンコードする可能性のあるメカニズムを研究し始めています。
これらの問題は、Hugging Faceの私たち機械学習の研究者や開発者、およびより広範な機械学習コミュニティにとって、非常に個人的な問題です。Hugging Faceは国際的な企業であり、私たちの多くは異なる国や文化の間に存在しています。私たちと同じような人々を守るための十分な配慮なしに開発される技術を見るとき、私たちの緊急性を十分に表現することは困難です。特に、これらのシステムが差別的な誤った逮捕や不当な経済的苦境につながり、移民や法執行機関に売られることが増えている場合には、私たちのアイデンティティが訓練データセットで継続的に抑圧され、”生成AI”システムの出力で代表されることで、これらの関心が私たちの日常の生活経験と結びつきます。
私たちの経験は、私たちとは異なる経験を持つ人々にとって、機械学習による差別が不均衡に影響を与えるさまざまな方法を十分にカバーするものではありませんが、技術に固有のトレードオフに関する考慮事項への入り口を提供しています。私たちは、機械学習の潜在能力を強く信じています。それは、一つのサイズが全てに適合する万能薬ではなく、展開コンテキストでの人々からの入力や配慮がある限り、価値あるツールとして輝くと考えています。特に、この配慮を可能にするためには、機械バイアスのメカニズムを機械学習開発プロセス全体でよりよく理解し、利益と被害がどのように分配されるかについての必要な議論に参加するための技術的な知識レベルの異なる人々をサポートするツールを開発することが必要です。
ハギングフェイスの倫理と社会の定期投稿からのこのブログ記事は、ML開発プロセスのさまざまな段階でバイアスに対処するために、私たちがどのように取り組んできたか、取り組んでいるか、またはHFエコシステムのライブラリのユーザーが取り組むことをお勧めする方法の概要を提供します。また、このプロセスをサポートするために開発したツールです。あなたの仕事の社会的影響に関する具体的な考慮をガイドし、問題が発生した場合にこれらの問題を緩和するためにここで参照されているツールを活用できるように願っています。
バイアスの文脈への配置
マシンバイアスを扱う際に考慮する最初でおそらく最も重要な概念は文脈です。NLPのバイアスに関する彼らの基礎的な研究で、Su Lin Blodgettらは次のように指摘しています。「[機械バイアスに関する学術的な著作の]大部分は、最初に「バイアス」が何を構成するのかについて批判的に関与していない」ということを指摘しています。これには、「どのような種類のシステムの振る舞いが誰にとってどのような方法で有害であり、なぜそれがそうであるのか」という暗黙の前提の上に彼らの作業を構築することも含まれています。
これは、ML研究コミュニティが「一般化」の価値に焦点を当てているため、あまり驚くことではありません。この領域での作業の最も引用される動機の後に続くものです。しかし、広範な設定に適用されるバイアス評価ツールは、モデルの振る舞いの共通の傾向の分析を可能にするために価値がありますが、具体的なユースケースで差別を引き起こすメカニズムに対処する能力は本質的に制限されています。ML開発サイクル内で特定の意思決定をガイドするために、システムの特定の使用文脈と影響を受ける人々を考慮に入れるために、通常は1つまたは2つの追加のステップが必要です。
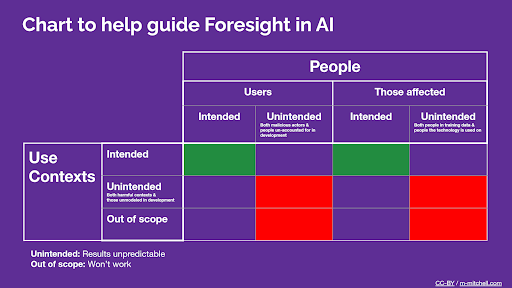 モデルカードガイドブックからのML使用文脈と人々に関する考慮事項の抜粋
モデルカードガイドブックからのML使用文脈と人々に関する考慮事項の抜粋
さて、スタンドアロン/文脈を持たないMLアーティファクトのバイアスと特定の被害との関連付けについて詳しく見てみましょう。マシンバイアスを差別に基づく被害のリスク要因として考えることは有用です。例えば、テキストから画像へのモデルが、専門的な環境での人の写真を作成するように促されるときには、明るい肌の色調を過剰に表現しますが、犯罪に関するプロンプトがあるときには暗い肌の色調を生成します。これらの傾向は、モデルレベルのマシンバイアスと呼ばれます。さて、このようなテキストから画像へのモデルを使用するいくつかのシステムについて考えてみましょう。
- モデルはウェブサイト作成サービス(SquareSpace、Wixなど)に統合され、ユーザーがページの背景を生成するのを助けます。モデルは生成された背景の人物の画像を明示的に無効にします。
- この場合、機械バイアスの「リスク要因」は、バイアスの焦点(人物の画像)がユースケースから除外されているため、差別的な被害にはつながりません。
- 機械バイアスのために追加のリスク軽減策は必要ありませんが、開発者はスクレイピングされたデータで訓練されたシステムを商業システムに統合することの合法性についての議論に注意を払う必要があります。
- モデルはストックイメージのウェブサイトに統合され、ユーザーにプライバシー上の懸念が少ない合成画像を提供します(例:プロフェッショナルな環境でのイラストなど)。これらの画像は、たとえばWikipediaの記事の挿絵として使用されることがあります。
- この場合、機械バイアスは既存の社会的なバイアスを固定化し、増幅します。それは人々についての固定観念(「CEOはすべて白人男性です」)を強化し、それが職場での暗黙のバイアスを強化するなど、さまざまな方法で増加したバイアスが増加した差別につながる複雑な社会システムに再びフィードバックされます。
- 軽減策には、ストックイメージのユーザーにこれらのバイアスについて教育すること、またはストックイメージのウェブサイトが生成された画像を故意により多様な表現のセットを提案するために選別することが含まれる場合があります。
- モデルは警察署が言葉の証言に基づいて容疑者の写真を生成するために使用する「仮想スケッチアーティスト」ソフトウェアに統合されています。
- この場合、機械バイアスは直接的に差別を引き起こし、警察署を暗い肌の人々に指示し続けることで、彼らを身体的な害や違法な拘束のリスクにさらします。
- このような場合には、リスクを受け入れ可能なレベルにするためのバイアス軽減策は存在しないかもしれません。特に、このようなユースケースは、商業団体や立法府が使用全般で一時停止または禁止を採用した顔認識と関連しており、類似のバイアスの問題が存在します。
では、MLにおけるマシンバイアスの責任は誰にあるのでしょうか?これらの3つのケースは、ML開発者がバイアスに対処することについての議論が複雑になる理由の一つを示しています。MLシステムの開発プロセスの他のポイントで他の人々が行った意思決定によって、MLデータセットやモデルのバイアスは、アプリケーションの設定に関係ない場所から直接的に深刻な被害を引き起こす可能性があります。しかし、これらのすべてのケースで、モデル/データセットのより強いバイアスは、ネガティブな結果のリスクを高めます。欧州連合は、最近の規制の取り組みでこの現象に対処するためのフレームワークを開発し始めています。要するに、測定可能なバイアスのあるモデルに基づいたAIシステムを展開する会社は、システムによって引き起こされる被害に対して責任を負います。
バイアスをリスク要因として概念化することにより、開発者間での機械のバイアスに対する「共有責任」を理解することができます。バイアスは完全に取り除くことはできません。なぜなら、社会的なバイアスの定義とそれらを差別に結びつける権力関係は社会的な文脈によって大きく異なるからです。しかし、以下のようになります:
- タスクの仕様、データセットのキュレーション、モデルのトレーニングからモデルの統合とシステムの展開まで、開発プロセスの各段階は、その選択肢と技術的な決定に直接依存する機械のバイアスの側面を最小限に抑えるための手順を踏むことができます。
- さまざまなML開発段階間の明確なコミュニケーションと情報の流れは、バイアスのネガティブな可能性を軽減するために互いに重ねて選択肢を構築するか(デプロイメントシナリオ1のようなバイアス緩和の多角的アプローチ)、あるいはネガティブな可能性を悪化させるために選択肢を重ねるか(デプロイメントシナリオ3のような)の違いを生むことができます。
次のセクションでは、これらのさまざまな段階と、それぞれで機械のバイアスに対処するのに役立つツールについて説明します。
ML開発サイクル全体でのバイアス対処
実践的なアドバイスに備えていますか?では始めましょう 🤗
MLシステムを開発するための単一の方法はありません。どのステップがどの順序で行われるかは、開発環境(大学、大企業、スタートアップ、地域団体など)、モダリティ(テキスト、表形式データ、画像など)、公開されているMLリソースの優位性や希少性など、多くの要素に依存します。ただし、バイアスに対処する上で特に興味深い3つの共通の段階を特定することができます。これらはタスクの定義、データのキュレーション、およびモデルのトレーニングです。これらのさまざまな段階でバイアスの取り扱いがどのように異なるかを見てみましょう。
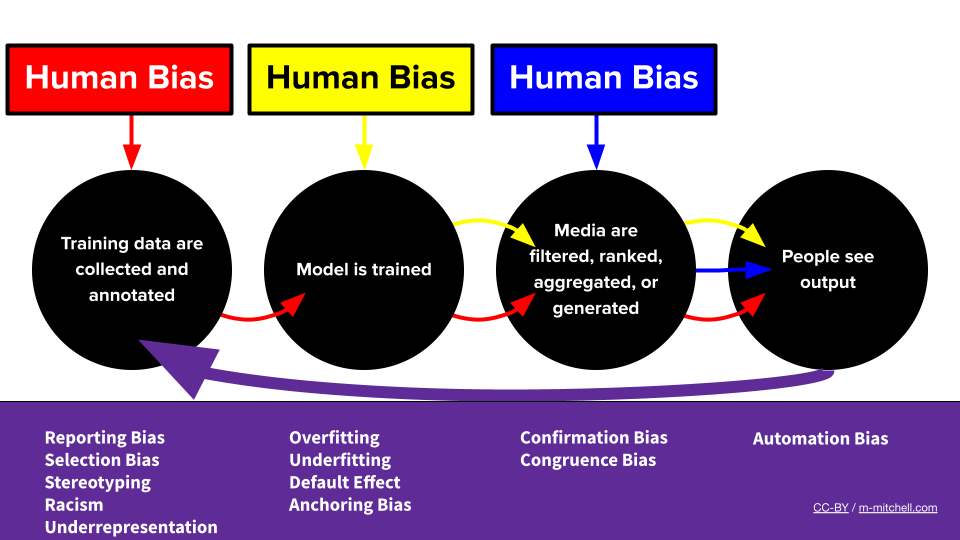 メグによるバイアスMLパイプライン
メグによるバイアスMLパイプライン
私はMLシステムのタスクを定義しています。どのようにバイアスに対処できますか?
システム内のバイアスが具体的に人々にどの程度影響するかは、システムが使用される目的に最終的に依存します。そのため、開発者がバイアスを軽減するために取り組むことができる最初の場所は、MLがシステムにどのように適合するかを決定するときです。たとえば、アルゴリズムに基づいたコンテンツ推薦のために本格的に使用された最初のケースの1つに戻ってみましょう。2006年から2009年まで、NetflixはNetflix Prizeという、新しい映画のユーザーの過去の評価に基づいて新しい映画の評価を正確に予測するためのMLシステムを開発する世界中のチームに対する競技として1Mドルの賞金を提供しました。優勝作品は、Netflix自身のCineMatchアルゴリズムに比べて、見えないユーザー-映画のペアに対する予測のRMSE(平均二乗誤差)を10%以上改善しました。つまり、ユーザーが新しい映画をどのように評価するかを過去の評価に基づいて予測する能力が大幅に向上しました。このアプローチにより、MLが推薦システムにおけるユーザーの好みをモデル化する役割を一般の人々に意識させることで、現代のアルゴリズムに基づいたコンテンツ推薦の扉が開かれました。
では、これがバイアスと何の関係があるのでしょうか?人々が過去に好んだコンテンツを表示することは、コンテンツプラットフォームからすると良いサービスのように思えますよね?しかし、過去のモデルで捉えられたバイアスやステレオタイプなどの傾向が強化されることになります。たとえば、黒人アメリカ人のユーザーの好みや一部のアーティストに不利益をもたらすシステムの動態などです。これは、上記で説明したバイアスに関連する懸念の2つを反映しています。トレーニング目標は、既存のバイアスが予測に現れる可能性を高めるため、バイアスに関連する害の「リスク要因」として機能し、タスクのフレーミングは過去のバイアスを「固定化」し悪化させる効果があります。
この段階での有望なバイアス緩和戦略は、MLをアルゴリズムコンテンツ推薦に適用する際に、エンゲージメントと多様性の両方を明示的にモデル化するようにタスクを再構築することです。ユーザーは長期的な満足度を得る可能性が高くなり、上記で説明したようなバイアスが悪化するリスクが低くなります!
この例は、MLによってサポートされる製品における機械バイアスの影響が、単にMLをどこに活用するかではなく、ML技術がどのように広範な技術システムに統合され、どの目的で使用されるかにも依存することを示しています。MLを活用したい製品やユースケースを調査する際には、MLモデルやデータセットに入り込む前に、バイアスの観点から既存システムの故障モードを探ることをおすすめします。バイアスがMLの予測によって悪化した場合、この領域の既存システムのどの行動が特に有害であるか、またはより頻繁に発生する可能性がありますか?
我々は、自動的なコンテンツモデレーションにおけるヘイトスピーチ検出のケースで、ユーザーをこれらの質問を導くためのツールを作成しました。例えば、MLの技術の一部に特に焦点を当てていないニュースや科学記事を調べることは、既にバイアスが働いている箇所を把握する良い方法であることがわかりました。モデルやデータセットが展開コンテキストにフィットしているか、既知のバイアスに関連する被害とどのように関連するかを確認するために、ぜひご覧ください!
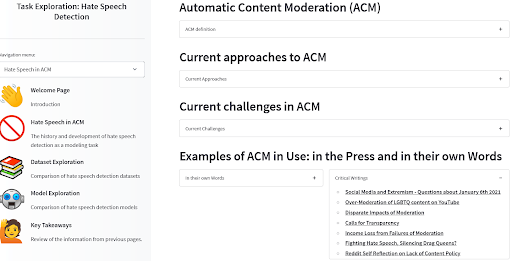 ACM Task Exploration tool by Angie, Amandalynne, and Yacine
ACM Task Exploration tool by Angie, Amandalynne, and Yacine
タスクの定義:推奨事項
MLのタスクの定義や展開がバイアスに関連する被害のリスクにどのように影響するかは、MLシステムの応用によってさまざまです。上記の例のように、バイアスに関連するリスクを最小限に抑えるために役立ついくつかの一般的な手順には、次のようなものがあります:
- 調査:
- ML以前の分野でのバイアスの報告
- 特定のユースケースにおけるリスクのある人口カテゴリ
- 検討:
- 最適化目標がバイアスを強化する影響
- 多様性と長期的なポジティブな影響を重視する代替目標
私はMLシステムのためのデータセットをキュレーション/選定していますが、どのようにバイアスに対処すればよいですか?
トレーニングデータセットは、ML開発サイクルにおけるバイアスの唯一の原因ではありませんが、重要な役割を果たします。女性の伝記と人生の出来事を関連付ける割合が男性の実績と関連付けられる割合よりも高いですか?これらのステレオタイプは、あなたのMLシステム全体に現れる可能性があります!音声認識のデータセットは特定のアクセントのみを特集していますか?それはテクノロジーの包括性の観点からは良い兆候ではありません!MLアプリケーションのためのデータセットをキュレーションしたり、MLモデルをトレーニングするためのデータセットを選択する場合、これらの現象がデータにどの程度存在するかを把握し、軽減し、伝えることはすべて、バイアスに関連するリスクを軽減するために必要な手順です。
データセットのバイアスを理解するために、データの出所、データに表れる人々の代表性、キュレーションプロセスについて反省することで、データセットのバイアスを予測することができます。この反省とドキュメンテーションのために、NLPのためのデータステートメントやデータセットのためのデータシートなど、いくつかのフレームワークが提案されています。Hugging Face Hubには、これらの作品に触発されたデータセットカードのテンプレートとガイドが含まれています。データの使用に関する考慮事項のセクションは、データセットを閲覧している場合は重要なバイアスに関する情報を探すための良い場所であり、新しいデータセットを共有する場合はそのトピックに関する洞察を共有する段落を書くための良い場所です。そして、そこに入れるものについてさらにインスピレーションを求める場合は、法的手続き、画像分類、新聞の歴史的データセットのためにBigLAM組織のユーザーが書いたこのセクションをチェックしてください。
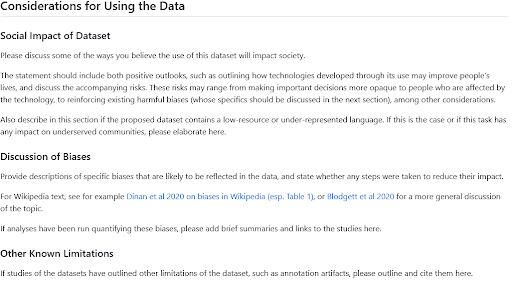 社会的影響とバイアスセクションのためのHFデータセットカードガイド
社会的影響とバイアスセクションのためのHFデータセットカードガイド
データセットの起源と文脈を説明することは、バイアスが発生する要因を理解するための良い出発点ですが、それらのバイアスをエンコードする現象を定量的に測定することも同様に役立ちます。特定のタスクに対して2つの異なるデータセットの選択肢や、異なるデータセットでトレーニングされた2つのMLモデルの選択肢の間で、MLシステムのユーザーベースの民族構成をよりよく反映する方を知ることは、バイアスに関連するリスクを最小限に抑えるための情報を提供します。データセットをキュレーションする場合は、ソースからデータポイントをフィルタリングしたり、新しいデータソースを選択したりすることで、全体のデータセットに存在する多様性とバイアスにどのように影響するかを測定することで、一般的に使用することが安全になります。
最近、データをバイアスに関する知識を基に測定するための2つのツールをリリースしました。disaggregators🤗ライブラリは、メタデータまたはモデルを利用してデータポイントの特性を推測することにより、データセットの構成を定量化するためのユーティリティを提供しています。これは、トレーニングされたモデルのバイアスに関連する表現の被害や異なる性能のリスクを最小限に抑えるために特に役立ちます。デモを見て、LAION、MedMCQA、The Stackのデータセットに適用される様子をご覧ください!
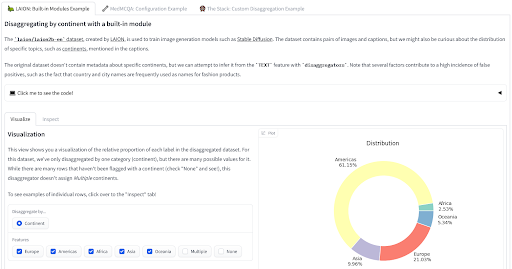 Disaggregator tool by Nima
Disaggregator tool by Nima
データセットの構成に関する有用な統計情報を持っていると、データアイテムの特徴間の関連性を見ることも重要です。特に、蔑称や否定的なステレオタイプをエンコードする可能性のある関連性に注目する必要があります。昨年紹介したデータ測定ツールでは、テキストベースのデータセット内の用語間の正規化された相互情報量(nPMI)を見ることでこれを行うことができます。特に、性別に関連する代名詞間の関連性に注目し、性別に関連するステレオタイプを示す可能性のある関連性を見ることができます。ぜひ自分で実行してみるか、予め計算されたいくつかのデータセットで試してみてください!
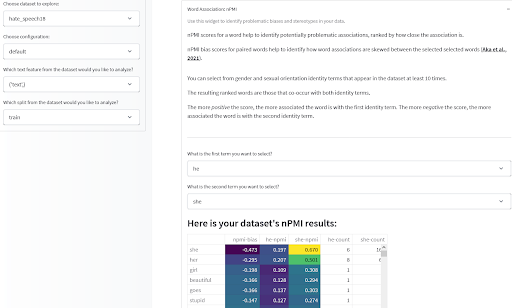 Data Measurements ツール by Meg、Sasha、Bibi、および Gradio チーム
Data Measurements ツール by Meg、Sasha、Bibi、および Gradio チーム
データセットの選択/整理:推奨事項
これらのツールはそれ自体で完全な解決策ではなく、バイアスおよびバイアスに関連するリスクの観点を含め、データセットの批判的な検討と改善をサポートするために設計されています。一般的に、これらおよびその他のツールを利用してデータセットの整理/選択段階でバイアスのリスクを軽減するためには、次の手順を考慮することをお勧めします:
- 特定のバイアスを悪化させる可能性のあるデータセット作成の側面
- データセットのタスクおよびドメインに特に重要な人口統計カテゴリおよび社会変数
- データセット内の人口統計分布
- 事前に特定されたネガティブなステレオタイプの表現
- 特定および計測した内容を Dataset Card で共有し、他のユーザー、開発者、および関係者に利益をもたらすようにします
- バイアスに関連する損害の可能性が最も低いデータセットを選択することにより
- バイアスのリスクを軽減する方法でデータセットを反復的に改善することにより
MLシステムのトレーニング/モデルの選択中にバイアスに対処する方法は?
データセットの整理/選択のステップと同様に、モデルのバイアスに関連する現象を文書化および計測することは、使用するモデルをそのまま使用するか、微調整するためのML開発者、および独自のモデルをトレーニングしたいML開発者の両方に役立ちます。後者にとって、モデル内のバイアスに関連する現象の測定値は、他のモデルに対してうまくいったことやいかなかったことから学び、自身の開発選択をガイドするための信号となることができます。
モデルカードは元々 (Mitchell et al., 2019) によって提案され、広範な倫理的考慮事項、分解された評価、および使用ケースの推奨事項など、バイアスのリスクに関連する情報をショーケースするためのモデルレポートの枠組みを提供しています。Hugging Face Hubでは、モデルドキュメンテーションにさらに多くのツールが提供されており、Hubドキュメントのモデルカードガイドブックや新しいモデルのための詳細なモデルカードを簡単に作成できるアプリもあります。
 Model Card writing ツール by Ezi、Marissa、および Meg
Model Card writing ツール by Ezi、Marissa、および Meg
ドキュメンテーションはモデルの振る舞いについての一般的な洞察を共有するための素晴らしい第一歩ですが、通常は静的であり、すべてのユーザーに同じ情報を提供します。特にトレーニングデータの分布を近似する出力を生成できる生成モデルの場合、モデルの出力を視覚化および対比することで、バイアスに関連する現象やネガティブなステレオタイプに関する文脈に基づいた理解を得ることができます。モデル生成へのアクセスは、モデルの振る舞いと自身の経験に対応したモデルの交差的な問題をユーザーがもたらすのに役立ち、モデルが異なる形容詞と職業に対して性別に関連するステレオタイプをどの程度再現するかを評価するのに役立ちます。このプロセスを支援するために、私たちはツールを開発しました。このツールでは、形容詞と職業のセットだけでなく、異なるモデル間でも生成物を比較することができます!ぜひ試してみてください。使用ケースにおいて最もバイアスのリスクが少ないモデルはどれかを把握するための感覚を得ることができます。
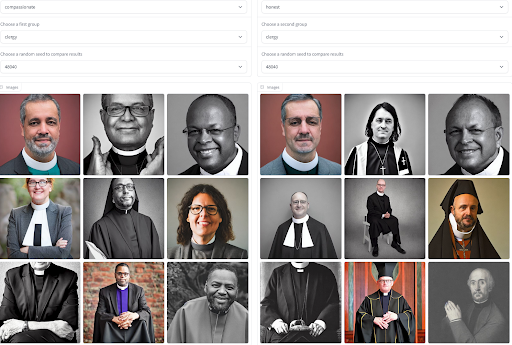 Sasha によるイメージ生成における形容詞と職業のバイアスの可視化
Sasha によるイメージ生成における形容詞と職業のバイアスの可視化
モデル出力の視覚化は生成モデルに限られません!分類モデルの場合、モデルの異なる人口統計に対するパフォーマンスの差異によるバイアスに関連する損害にも注意する必要があります。差別のリスクが最も高い保護されたクラスがわかっていて、評価セットにそれらが注釈付けされている場合、モデルカードで異なるカテゴリごとの分解されたパフォーマンスを報告することができます。ただし、バイアスに関連する損害のリスクがあるすべての人口統計を特定できていない場合や、疑わしいバイアスを測定するための注釈付きテスト例にアクセスできない場合、モデルの失敗箇所とその方法を対話的に可視化することが重要です!このプロセスをサポートするために、SEALアプリはモデルによる類似の誤りをグループ化し、各クラスターの共通の特徴を表示します。さらに進める場合は、データセットのセクションで紹介したディスアグリゲーターライブラリと組み合わせて、バイアスに関連する故障モードを示すクラスターを見つけることもできます!
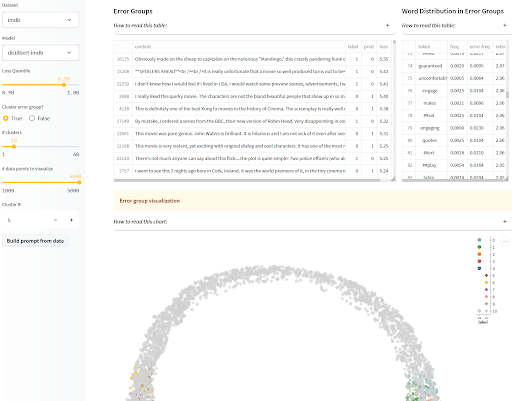 ナズニーンによるシステマティックエラー分析とラベリング(SEAL)
ナズニーンによるシステマティックエラー分析とラベリング(SEAL)
最後に、モデル内のバイアス関連現象を測定できるいくつかのベンチマークが存在します。言語モデルの場合、BOLD、HONEST、またはWinoBiasなどのベンチマークは、モデル内のバイアスを示す指標的な動作の定量的評価を提供します。これらのベンチマークには制約がありますが、異なるモデル間の選択やモデルの動作方法を説明するのに役立つ、事前に特定されたバイアスリスクの一部に対する限定的な視点を提供します。これらの評価は、一連の一般的な言語モデルで事前計算されているため、この探索スペースで比較するための初めの手掛かりを得ることができます!
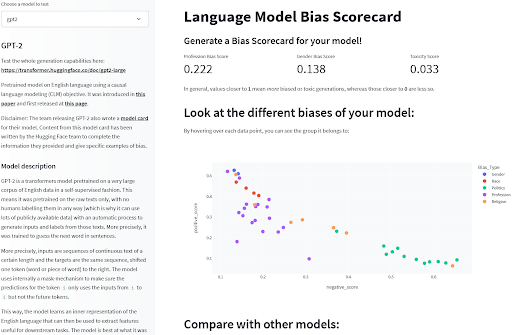 サーシャによる言語モデルバイアス検出
サーシャによる言語モデルバイアス検出
検討しているモデルに対するベンチマークへのアクセスがあるにしても、自分自身の計算リソースでは評価を実行することが prohibitively expensive であったり技術的に不可能であったりすることがあります。今年リリースされたEvaluation on the Hubツールは、そのような場合に役立ちます。このツールは評価を実行するだけでなく、評価結果をモデルのドキュメントに接続するので、結果は一度だけ利用できます。例えば、OPTのようなモデルではサイズがバイアスリスクを測定可能に増加させることが誰もが確認できます!
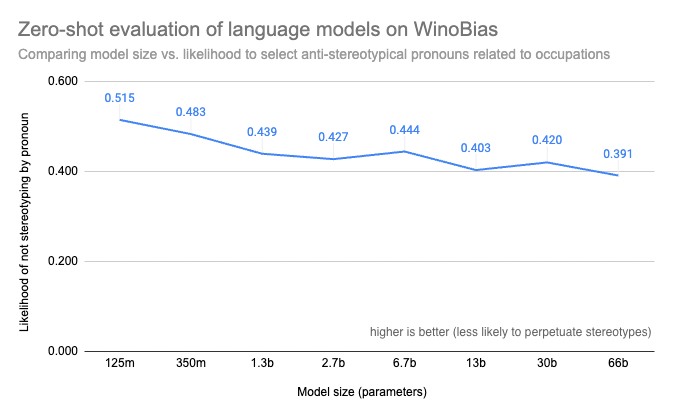 ヘレン、トリスタン、アビシェク、ルイス、ダウェによって評価された大規模モデルのWinoBiasスコア(Evaluation on the Hubによる計算)
ヘレン、トリスタン、アビシェク、ルイス、ダウェによって評価された大規模モデルのWinoBiasスコア(Evaluation on the Hubによる計算)
モデル選択/開発:おすすめ
データセットと同様に、モデルに関するドキュメントと評価のための異なるツールは、モデルのバイアスリスクに関する異なる視点を提供し、開発者がMLシステムを選択、開発、理解するのに役立ちます。
- 可視化
- 生成モデル:モデルの出力がステレオタイプを反映している可能性を可視化する
- 分類モデル:モデルのエラーを可視化して、異なるパフォーマンスを引き起こす可能性のある失敗モードを特定する
- 評価
- 可能な場合は、関連するベンチマークでモデルを評価する
- ドキュメント
- 可視化と質的評価からの学びを共有する
- モデルの分解されたパフォーマンスと適用可能な公平性ベンチマークの結果を報告する
結論と🤗からのバイアス分析とドキュメンテーションツールの概要
私たちは、より多くのアプリケーションでMLシステムを活用するにつれ、その恩恵を公平に享受するためには、技術の関連するバイアスによる被害のリスクを積極的に軽減する能力に依存することになります。どのように最善の方法でこれを行うべきかという質問には一つの正解はありませんが、私たちは、リスクを軽減し文書化するための教訓、ツール、方法論を共有することで、この取り組みを支援することができます。このブログ投稿では、Hugging Faceチームメンバーがバイアスの問題に対処する方法とサポートするツールについて概説しています。役立つ情報となることを願って、あなた自身の取り組みを開発して共有することをお勧めします!
リンクされたツールの要約:
- タスク:
- MLタスクディレクトリを探索して、選択肢とリソースについての技術的フレームワークを理解する
- 特定のタスクのフル開発ライフサイクルを探索するためのツールを使用する
- データセット:
- データセットカードを活用し、データセットのバイアスに関する関連洞察を共有する
- Disaggregatorを使用して、異なるパフォーマンスを探索する
- nPMIを含むデータセットの集計測定値を確認し、ステレオタイプ的な関連を抽出する
- モデル:
- モデルカードを活用し、モデルのバイアスに関する関連洞察を共有する
- インタラクティブモデルカードを使用してパフォーマンスの差異を可視化する
- システマティックなモデルエラーを調べ、既知の社会的バイアスに注意する
- 言語モデルのバイアス、特に大規模モデルの探索にEvaluateとEvaluation on the Hubを使用する
- テキストから画像へのバイアスエクスプローラーを使用して、画像生成モデルのバイアスを比較する
- バイアススコアカードを使用してLMモデルを比較する
お読みいただきありがとうございました!🤗
〜倫理と社会の定期メンバー代表のヤシンより
このブログ投稿を引用する場合は、以下を使用してください:
@inproceedings{hf_ethics_soc_blog_2,
author = {Yacine Jernite and
Alexandra Sasha Luccioni and
Irene Solaiman and
Giada Pistilli and
Nathan Lambert and
Ezi Ozoani and
Brigitte Toussignant and
Margaret Mitchell},
title = {Hugging Face Ethics and Society Newsletter 2: バイアスについて話しましょう!},
booktitle = {Hugging Face Blog},
year = {2022},
url = {https://doi.org/10.57967/hf/0214},
doi = {10.57967/hf/0214}
}We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles