Hamiltonを使って、8分でAirflowのDAGの作成とメンテナンスを簡単にしましょう
Let's simplify the creation and maintenance of Airflow DAGs using Hamilton in just 8 minutes.
Hamiltonがあなたが保守性の高いAirflow DAGを書くのにどのように役立つか

この記事はThierry Jeanとの共同執筆であり、元の記事はこちらから参照できます。
この記事では、2つのオープンソースプロジェクト、HamiltonとAirflow、およびそれらの有向非巡回グラフ(DAG)がどのように連携するかについて説明します。高レベルでは、Airflowはオーケストレーション(マクロ)を担当し、Hamiltonはクリーンで保守可能なデータ変換(マイクロ)の作成を支援します。
Hamiltonについて馴染みのない方には、tryhamilton.devのインタラクティブな概要や、他の投稿(例えば、この投稿)をご紹介します。それ以外の場合は、Hamiltonについて高レベルで説明し、詳細については参照ドキュメントをご覧ください。参考までに、私はHamiltonの共同作成者の1人です。
まだ2つのプロジェクトがどのように連携するかを理解しようとしている方々にとって、HamiltonをAirflowと実行できる理由は、Hamiltonが小さな依存性のフットプリントを持つライブラリであるため、HamiltonをAirflowのセットアップに追加するのは簡単です!
繰り返しになりますが、Airflowはデータパイプラインのオーケストレーションの業界標準です。ETL、MLパイプライン、BIなど、あらゆる種類のデータイニシアチブにパワーを提供しています。2014年の設立以来、Airflowのユーザーは、次のようなデータパイプラインの作成と保守に関する課題に直面してきました:
- ワークフローの進化を保守可能に管理すること。単純なもので始まるものは必ず複雑になります。
- Airflowタスク内で実行されるモジュラーで再利用可能でテスト可能なコードの作成。
- Airflow DAGが生成するコードとデータアーティファクトのラインナップを追跡すること。
ここで、Hamiltonが役立つと考えています! Hamiltonは、データ変換を記述するためのPythonマイクロフレームワークです。つまり、Hamiltonは、名前、引数、および型アノテーションに基づいて、Python関数を「宣言的」スタイルで記述し、それらをグラフにパースして接続します。特定の出力をリクエストすることができ、Hamiltonは必要な関数パスを実行してそれらを生成します。マクロのオーケストレーション機能を提供しないため、Airflowとの組み合わせは、データプロフェッショナルがAirflow DAGのためによりクリーンで再利用可能なコードを書くのを支援します。
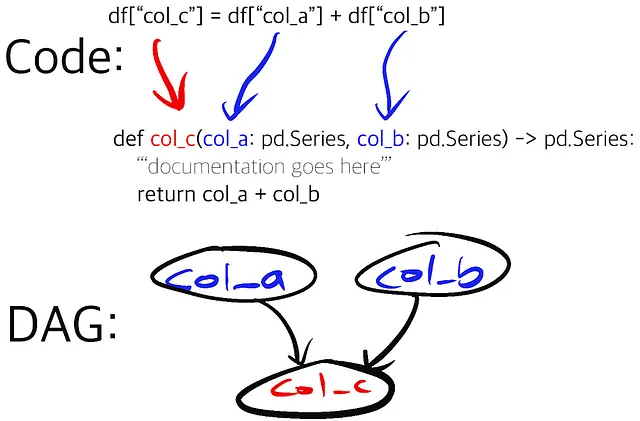
保守性の高いAirflow DAGを書く
Airflowの一般的な使用法は、機械学習/データサイエンスのサポートに役立ちます。このようなワークロードを本番環境で実行する場合、複雑なワークフローが必要になることがよくあります。Airflowでの重要な設計上の決定は、ワークフローをAirflowタスクにどのように分割するかを決定することです。タスクを多く作成すると、スケジューリングと実行のオーバーヘッドが増えます(たくさんのデータの移動など)、タスクを少なく作成すると、実行に時間がかかるモノリシックなタスクができますが、おそらく実行効率が向上します。ここでのトレードオフは、Airflow DAGの複雑さと各タスク内のコードの複雑さです。これにより、デバッグやワークフローの理解がより困難になります。特に、最初のAirflow DAGの作者でない場合は、タスクの構造が固定されることがよくあります。タスクコードのリファクタリングは禁止されます!
A->B->CなどのよりシンプルなDAGは望ましいですが、構造のシンプlicityとタスクごとのコード量の間には本質的な緊張関係があります。タスクごとのコードが多いほど、障害箇所を特定することが困難になります。障害の場合、リトライのコストはタスクの「サイズ」とともに増加します。
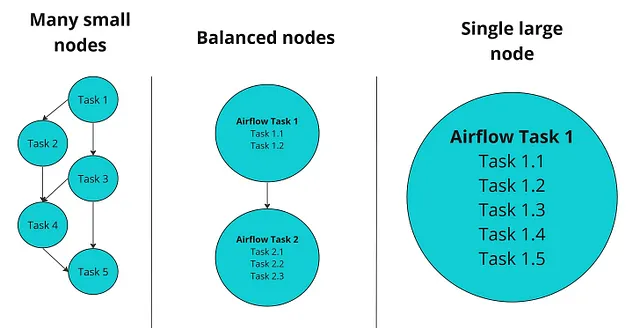
代わりに、Airflowタスク内の複雑さを同時に処理し、それに含まれるコードのサイズに関わらず、Airflow DAGの形状を容易に変更できる柔軟性を得ることができたらどうでしょうか? それがHamiltonの出番です。
Hamiltonを使用すると、各Airflowタスク内のコードをHamilton DAGで置き換えることができます。Hamiltonはタスク内のコードの「マイクロ」オーケストレーションを処理します。注意:Hamiltonは実際にはAirflow DAGのすべての機能を論理的にモデル化することができます。以下で詳しく説明します。
Hamiltonを使用するには、Hamiltonの関数が含まれるPythonモジュールをロードし、Hamiltonドライバーをインスタンス化し、いくつかのコードを使用してAirflowタスク内でHamilton DAGを実行します。 Hamiltonを使用することで、データ変換を任意の粒度で記述できるため、各Airflowタスクが行っていることを詳細に調査することができます。
具体的なコードのメカニズムは次のとおりです:
- 関数モジュールをインポートする
- それらをHamiltonドライバーに渡してDAGを構築する
- 次に、定義したDAGから実行する出力を指定して
Driver.execute()を呼び出す
次に、Hamiltonを使用してMLモデルのトレーニングと評価を行うシングルノードのAirflow DAGを作成するコードを見てみましょう:
ここではHamiltonのコードは表示していませんが、このアプローチの利点は次のとおりです:
- 単体テストと統合テスト。 Hamiltonは、名前付けや型アノテーションの要件を通じて、開発者がモジュール化されたPythonコードを記述するように促します。これにより、単体テストに適したPythonモジュールが作成されます。 Pythonコードが単体テストされると、Airflowタスクに含まれるコードをテストすることが少なくともCI / CD設定で容易ではなくなります。これはAirflow環境へのアクセスが必要とされるためです。
- データ変換の再利用。 このアプローチにより、データ変換のコードをAirflow DAGファイルから分離してPythonモジュールに保持することができます。これは、このコードがAirflowの外部で実行可能であることを意味します! 分析の世界から来た場合、AirflowのPostgresオペレータにロードする前に、外部の
.sqlファイルでSQLクエリを開発およびテストするのに似ているはずです。 - Airflow DAGの簡単な再構築。 Airflow DAGを変更するために必要な作業量が大幅に減少しました。 Hamiltonですべてを論理的にモデル化する場合、エンドツーエンドの機械学習パイプラインなど、Hamilton DAG内でどれだけ計算する必要があるかを決定するだけです。たとえば、1つの一枚岩のAirflowタスクから数個または多くのタスクに変更する場合、変更する必要があるのはHamiltonに要求する内容だけであり、Hamilton DAG自体は変更する必要はありません!
HamiltonとAirflowによる反復的な開発
ほとんどのデータサイエンスプロジェクトでは、要件が変わるため、最終システムのDAGを最初の日から書くことは不可能です。例えば、データサイエンスチームはモデル用の異なるフィーチャーセットを試したいかもしれません。リストが確定するまでは、ソースコードやバージョン管理下のフィーチャーセットを持つことは望ましくないでしょう。設定ファイルの方が好ましいです。
AirflowはデフォルトとランタイムのDAG設定をサポートし、これらの設定をログに記録してすべてのDAG実行を再現可能にします。ただし、設定可能な動作を追加するには、条件付きステートメントと複雑さをAirflowタスクのコードに追加する必要があります。このコードはプロジェクト中に廃れる可能性があり、特定のシナリオでのみ有用になる可能性があり、最終的にはDAGの読みやすさが低下します。
これに対して、HamiltonはAirflowのランタイム設定を使用して、関数グラフ上の異なるデータ変換を動的に実行することができます。このレイヤー化アプローチにより、Airflow DAGの表現力を大幅に向上させることができますが、構造のシンプルさを維持します。また、Airflowは設定から新しいDAGを動的に生成することもできますが、これにより観測性が低下する可能性があり、これらの機能の一部はまだ実験的なものです。
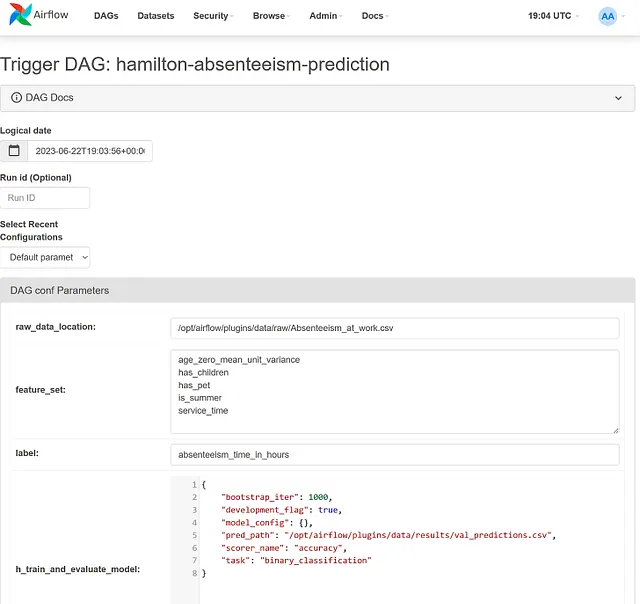
もし手渡しモデルで働いている場合、このアプローチは、Airflowプロダクションシステムのデータエンジニアと、Hamiltonコードを書いてビジネスソリューションを開発するデータサイエンティストとの関心の分離を促進します。この分離により、データの一貫性が向上し、コードの重複が減少することもあります。たとえば、単一のAirflow DAGを異なるHamiltonモジュールと組み合わせて再利用することができます。同様に、同じHamiltonデータ変換を異なるAirflow DAGで再利用して、ダッシュボード、API、アプリケーションなどを駆動することもできます。
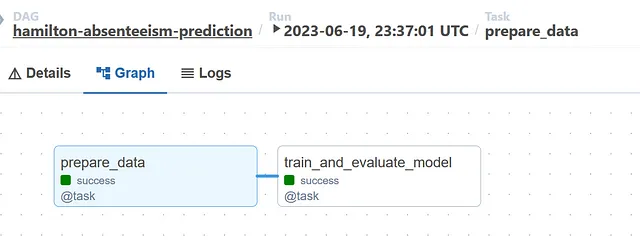
以下に2つの図があります。最初の図は、2つのノードを含む高レベルのAirflow DAGを示しています。2番目の図は、Airflowタスクtrain_and_evaluate_model.でインポートされたPythonモジュールevaluate_modelの低レベルのHamilton DAGを表示しています。

データアーティファクトの処理
データサイエンスプロジェクトでは、データセット、パフォーマンス評価、図表、トレーニングされたモデルなど、多数のデータアーティファクトが生成されます。必要なアーティファクトはプロジェクトのライフサイクル(データの探索、モデルの最適化、プロダクションのデバッグなど)によって変わるため、DAGからタスクを削除すると、そのメタデータ履歴が削除され、アーティファクトの系統が壊れるという問題があります。特定のシナリオでは、不要または冗長なデータアーティファクトを生成することが、計算およびストレージコストを引き起こす可能性があります。
Hamiltonは、データアーティファクトの生成に必要な柔軟性を提供することができます。デコレートされた@save_to.*の関数は、出力を保存する可能性を追加します。この機能は、Driver.execute()を介してこの機能を要求するだけで使用することができます。以下のコードでは、validation_predictions_tableを呼び出すとテーブルが返されます。一方、save_validation_predictionsのoutput_name_値を呼び出すと、テーブルが返され、.csvに保存されます。
この柔軟性により、ユーザーは生成されるアーティファクトを簡単に切り替えることができます。また、Airflowのランタイム設定を直接変更することで、Airflow DAGやHamiltonモジュールを編集する必要はありません。
さらに、詳細なHamilton関数グラフにより、データの系統と起源を正確に把握することができます。ユーティリティ関数what_is_downstream_of()およびwhat_is_upstream_of()は、データの依存関係を視覚化し、プログラムで探索するのに役立ちます。詳細については、興味のある読者はこちらを参照してください。
終わりに & 開始するための例
おそらく、HamiltonをAirflowと組み合わせることで、AirflowのDAG作成と保守の課題に対処することができることを理解していただけたかと思います。この投稿は短いので、最後に、Hamiltonリポジトリにあるコードに移動しましょう。
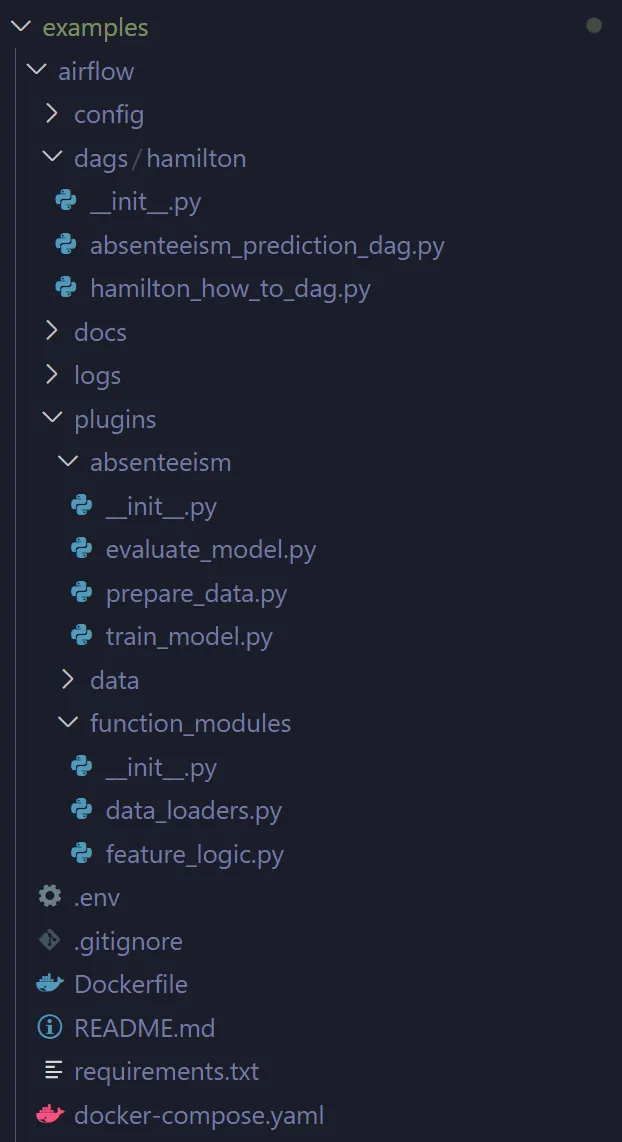
始めるのを助けるために、HamiltonをAirflowと一緒に使用する方法の例を用意しました。これにより、始めるために必要な基本的な内容がカバーされます。READMEには、DockerでAirflowをセットアップする方法も記載されており、依存関係をインストールする必要はありません。
例のコードには、2つのAirflow DAGが含まれており、1つはモデルのトレーニングに「特徴量」を作成するHamiltonの基本的な使用方法を示し、もう1つは完全なエンドツーエンドのパイプラインを作成し、モデルを適合させて評価するより完全な機械学習プロジェクトの例です。これらの例では、Hamiltonのコードはpluginsフォルダの下にあります。
質問やお困りの点がある場合は、Slackに参加してください。それ以外の場合は、Hamiltonの機能と機能について詳しく知りたい場合は、Hamiltonのドキュメントをご参照ください。
参考文献とさらなる読み物
この投稿をご覧いただきありがとうございます。もっと深く掘り下げたい場合や、Hamiltonについてもっと学びたい場合は、以下のリンクをご覧ください!
- Hamilton + Airflowのコード例
- Hamiltonドキュメンテーション
- tryhamilton.dev — Hamiltonについてのより詳しい情報を学ぶためのインタラクティブな方法です。
- Hamiltonと統合する別のオーケストレーションシステム、Hamilton + Metaflow
- Hamilton Slackコミュニティ
- 10分で理解するLineage + Hamilton
- Hamiltonの紹介(背景と導入)
- 5分でわかるHamilton + Pandas
- ノートブック環境でHamiltonを使用する方法
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
