「PDF、txt、そしてウェブページとして、あなたのドキュメントと話しましょう」
Let's discuss your documents as PDFs, text files, and web pages.
ウェブを作成し、LLMsを使用してPDF、TXT、ウェブページなどのドキュメントに質問できる知能の完全ガイド。
目次
· 序章· 動作原理· ステップ(パート1)👣· 休憩:振り返り(パート1)🌪️· ステップ(パート2)👣· 休憩:振り返り(パート2)🌪️· ウェブアプリ· 忍耐強い人のための(コード)· 結論· 参考文献
序章
私たちは皆、必要な価値や情報を含む2つの文を取得するために永遠のドキュメントを読まなければなりません。
言葉の海に迷わずにドキュメントから魅力的な情報を抽出できると思ったことはありませんか?
それ以上探す必要はありません!「LLMを使用したドキュメントへの問いかけ」というプロジェクトへようこそ。脳の疲労を感じることなく、PDF、TXTファイル、またはウェブページから宝物を回復できるようになります。そして心配しないでください、楽しむためにテクウィザードの学位は必要ありません。Streamlitを使用してユーザーフレンドリーなインターフェースを作成しましたので、あなたの非テクノロジーサヴィーな友人であるマーケティングアシスタントでも参加できます。
- 「AIとのプログラミング」
- このAI論文は、さまざまなディープラーニングと機械学習のアルゴリズムを用いた行動および生理学的スマートフォン認証の人気のあるダイナミクスとそのパフォーマンスを識別します
- 「大規模言語モデルのダークサイドの理解:セキュリティの脅威と脆弱性に関する包括的なガイド」
この記事では、アプリケーションの知能の理論とコードについて詳しく説明し、ウェブアプリケーションの動作原理に光を当てます。使用する主な技術を簡単に紹介するために、以下の画像をご覧ください。この画像は、4つの主要なツールがどのように動作しているかを示しています。

もちろん、コードは私のGitHubリポジトリで見つけることができます。また、コードを直接テストしたい場合は、「忍耐強い人のための(コード)」セクションにアクセスしてください。
動作原理
「LLMを使用したドキュメントへの問いかけ」のベールの向こう側をのぞいてみましょう。このプロジェクトは、スマートなプレーヤー(バックエンド)と使いやすいウェブサイト(フロントエンド)のような興味深いデュオです。
- スマートなリーダー:AIの脳はスーパースマートな友人のようにドキュメントを読み取り理解し、PDF、TXT、ウェブコンテンツを優れたパフォーマンスで処理します。
- 使いやすいウェブサイト:ユーザーフレンドリーなウェブインターフェースによるモデルの構成と対話。2つの主要なページで構成されており、それぞれの目的に応じて、ステップ1️⃣ データベースの作成とステップ2️⃣ ドキュメントのリクエストという役割があります。
私たちのプロジェクトの概要は次のようになります:
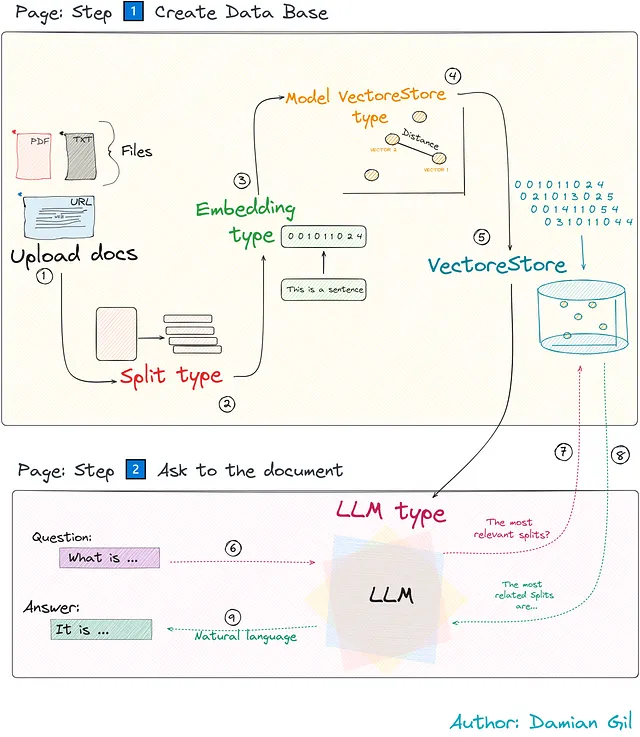
複雑に見えるかもしれませんが、機能的にするために必要なすべての重要なステップを簡素化します。知能の仕組みに焦点を当てることで、どのように機能するかを発見します。これらのステップはPythonのTalkDocumentクラスによってサポートされ、それぞれのステップを対応するコードでデモンストレーションします。
手順(パート1)👣
舞台裏の魔法の要素を発見しながら、道程のすべてのステップを探索しましょう!🚀🔍🎩
1- ドキュメントのインポート
このステップは明らかですね?ここで提供する素材のタイプを決めます。 PDF、プレーンテキスト、WebのURL、さらには生の文字列形式など、すべてがメニューにあります。
# Inside the __init__ function, I have commented out the variables# that we are not interested in at the moment.def __init__(self, HF_API_TOKEN, data_source_path=None, data_text=None, OPENAI_KEY=None) -> None: # ファイルのパスを入力できます。 self.data_source_path = data_source_path # 文字列形式のファイルを直接入力できます。 self.data_text = data_text self.document = None # self.document_splited = None # self.embedding_model = None # self.embedding_type = None # self.OPENAI_KEY = OPENAI_KEY # self.HF_API_TOKEN = HF_API_TOKEN # self.db = None # self.llm = None # self.chain = None # self.repo_id = Nonedef get_document(self, data_source_type="TXT"):# DS_TYPE_LIST= ["WEB", "PDF", "TXT"] data_source_type = data_source_type if data_source_type.upper() in DS_TYPE_LIST else DS_TYPE_LIST[0] if data_source_type == "TXT": if self.data_text: self.document = self.data_text elif self.data_source_path: loader = dl.TextLoader(self.data_source_path) self.document = loader.load() elif data_source_type == "PDF": if self.data_text: self.document = self.data_text elif self.data_source_path: loader = dl.PyPDFLoader(self.data_source_path) self.document = loader.load() elif data_source_type == "WEB": loader = dl.WebBaseLoader(self.data_source_path) self.document = loader.load() return self.documentアップロードするファイルのタイプに応じて、ドキュメントは異なる方法で読み込まれます。興味深い改善点として、自動的な形式検出の追加が考えられます。
2- 分割タイプ
さて、なぜ「タイプ」という用語が存在するのか疑問に思うかもしれません。アプリでは、分割方法を選択することができます。しかし、このトピックに入る前に、ドキュメントの分割について説明しましょう。
次のように考えてみてください:人間が情報を構造化するために章、段落、文を必要とするように(終わりのない段落を読んでみてください – はい!)、機械も構造が必要です。ドキュメントをよりよく理解するために、いくつかの小さなパーツに分割する必要があります。このパーシングは文字またはトークンによって行われることがあります。
# SPLIT_TYPE_LIST = ["CHARACTER", "TOKEN"]def get_split(self, split_type="character", chunk_size=200, chunk_overlap=10): split_type = split_type.upper() if split_type.upper() in SPLIT_TYPE_LIST else SPLIT_TYPE_LIST[0] if self.document: if split_type == "CHARACTER": text_splitter = ts.RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) elif split_type == "TOKEN": text_splitter = ts.TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) # 文字列をドキュメントとして入力した場合、split_textを実行します。 if self.data_text: try: self.document_splited = text_splitter.split_text(text=self.document) except Exception as error: print( error) # ドキュメントをアップロードした場合、split_documentsを実行します。 elif self.data_source_path: try: self.document_splited = text_splitter.split_documents(documents=self.document) except Exception as error: print( error) return self.document_splited3- 埋め込みタイプ
私たち人間は単語や画像を簡単に理解できますが、機械は少しガイダンスが必要です。これは、以下の場合に明らかになります:
- データセット内のカテゴリ変数を数値に変換しようとしているとき
- ニューラルネットワークにおける画像の管理。たとえば、画像がニューラルネットワークモデルに供給される前に、数値テンソルに変換するための変換を受けます。
数学モデルは数字の言葉を持っていることがわかります。この現象はNLPの分野でも見られ、単語の埋め込みの概念が推進されています。
本質的には、このステップでは前の段階(ドキュメントのチャンク)からの分割を数値ベクトルに変換しています。
この変換またはエンコーディングは、専用のアルゴリズムを使用して行われます。重要なことは、このプロセスが文をデジタルベクトルに変換し、このエンコーディングがランダムではないこと、構造化された方法に従っていることです。
このコードは非常にシンプルです:統合の責任を持つオブジェクトをインスタンス化します。重要なことは、この時点では実際の変換は行われていないということです。次のステップでは、実際の変換を行います。
def get_embedding(self, embedding_type="HF", OPENAI_KEY=None): if not self.embedding_model: embedding_type = embedding_type.upper() if embedding_type.upper() in EMBEDDING_TYPE_LIST else EMBEDDING_TYPE_LIST[0] # If we choose to use the Hugging Face model for embedding if embedding_type == "HF": self.embedding_model = embeddings.HuggingFaceEmbeddings() # If we opt for the OpenAI model for embedding elif embedding_type == "OPENAI": self.OPENAI_KEY = self.OPENAI_KEY if self.OPENAI_KEY else OPENAI_KEY if self.OPENAI_KEY: self.embedding_model = embeddings.OpenAIEmbeddings(openai_api_key=OPENAI_KEY) else: print("You need to introduce a OPENAI API KEY") # The object self.embedding_type = embedding_type return self.embedding_modelブレイク:復習しましょう(パート1)🌪️
最初の3つのステップを理解するために、以下の例を考えてみましょう:
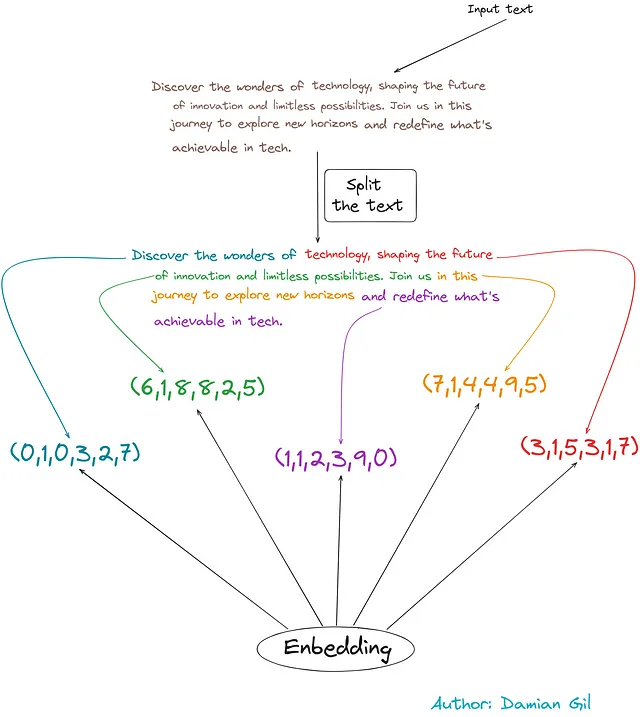
入力テキストから始めます。
- この例では、文字数に基づいて分布を行います(約50文字)。
- テキストの断片をデジタルベクトルに変換します。
素晴らしいですね!🚀 さあ、残りのレベルを興奮しながら進んでいきましょう。本当の技術の魔法を解き放つ準備をしてください!🔥🔓
ステップ(パート2)👣
続けて、次に進むステップを見ていきます。
4- モデルベクトルストアのタイプ
テキストをコード(埋め込み)に変換したので、それらを格納する場所が必要です。これが「ベクトルストア」という概念が登場する場所です。これは、質問をする際に似たコードを簡単に見つけて取得することができるスマートなライブラリのようなものです。
必要なものに迅速に戻ることができる、きちんと整理されたストレージスペースと考えてください!
このタイプのデータベースの作成は、FAISS(Facebook AI Similarity Search)など、この目的に特化した専用のアルゴリズムによって管理されます。他のオプションもありますが、現在、このクラスはCHROMAとSVMをサポートしています。
このステップと次のステップはコードを共有しています。このステップでは、作成するベクトルリポジトリのタイプを選択しますが、次のステップでは実際の作成が行われます。
5. モデルベクトルストア(作成)
このタイプのデータベースは、2つの主要な側面を扱います:
- ベクトルの格納:統合によって生成されたベクトルを格納します。
- 類似度の計算:ベクトル間の類似度を計算します。
しかし、これらのベクトル間の類似度とは具体的に何であり、なぜ重要なのでしょうか?
まあ、前述したように、統合はランダムではないと記述しましたよね?つまり、意味が似ている単語やフレーズは似たベクトルを持つように設計されています。そのため、ベクトル間の距離(ユークリッド距離のようなもの)を計算することができ、これによって「類似度」を測定することができます。
具体的な例でこれを視覚化するために、3つの文があると想像してください。
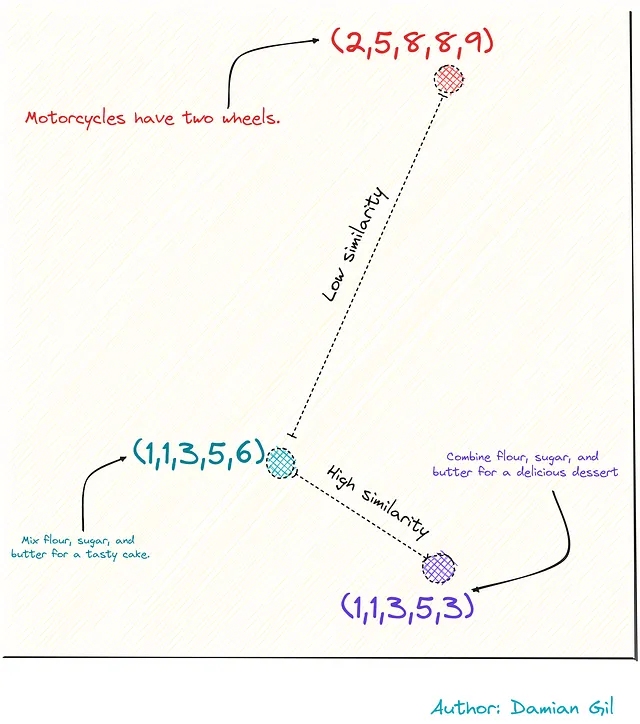
2つはレシピに関連しており、3番目はオートバイに関連しています。これらをベクトルとして表現することで(統合のおかげで)、これらの点または文の間の距離を計算することができます。この距離は、類似性の尺度として機能します。
コードの観点では、次の要件を見てみましょう:
- テキストの分割
- 埋め込みタイプ
- ベクトルストアモデル
# VECTORSTORE_TYPE_LIST = ["FAISS", "CHROMA", "SVM"]def get_storage(self, vectorstore_type = "FAISS", embedding_type="HF", OPENAI_KEY=None): self.embedding_type = self.embedding_type if self.embedding_type else embedding_type vectorstore_type = vectorstore_type.upper() if vectorstore_type.upper() in VECTORSTORE_TYPE_LIST else VECTORSTORE_TYPE_LIST[0] # 埋め込みを実行したアルゴリズムを呼び出してオブジェクトを作成します self.get_embedding(embedding_type=self.embedding_type, OPENAI_KEY=OPENAI_KEY) # 使用するベクトルストアのタイプを選択します if vectorstore_type == "FAISS": model_vectorstore = vs.FAISS elif vectorstore_type == "CHROMA": model_vectorstore = vs.Chroma elif vectorstore_type == "SVM": model_vectorstore = retrievers.SVMRetriever # ベクトルストアを作成します。この場合、ドキュメントは生のテキストから来ます。 if self.data_text: try: self.db = model_vectorstore.from_texts(self.document_splited, self.embedding_model) except Exception as error: print( error) # ベクトルストアを作成します。この場合、ドキュメントはpdf、txtなどのドキュメントから来ます。 elif self.data_source_path: try: self.db = model_vectorstore.from_documents(self.document_splited, self.embedding_model) except Exception as error: print( error) return self.dbこのステップで何が起こるかを説明するために、次のイメージを視覚化できます。エンコードされたテキストの断片がベクトルストアに格納され、ベクトルまたはポイント間の距離/類似性を計算することができることを示しています。
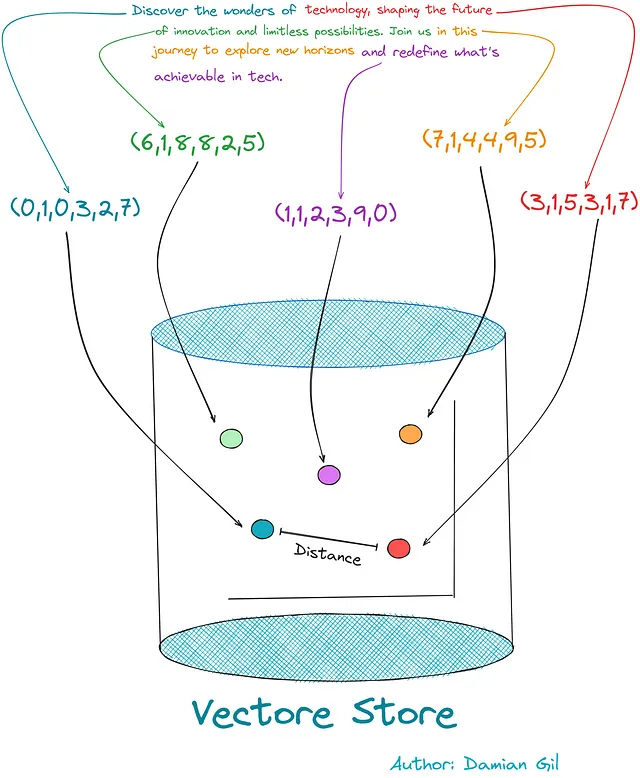
ブレイク:復習しましょう(パート2)🌪️
素晴らしい!これで、ドキュメントを保存し、暗号化されたテキストのチャンク間の類似性を計算できるデータベースを持っています。外部の文をエンコードし、ベクトルストアに保存するという状況を想像してみてください。これにより、新しいベクトルとドキュメントの分割との間の距離を計算することができます。(ここでも同じ統合がベクトルストアの作成に使用されるべきです。)このイメージを通じてこれを視覚化することができます。
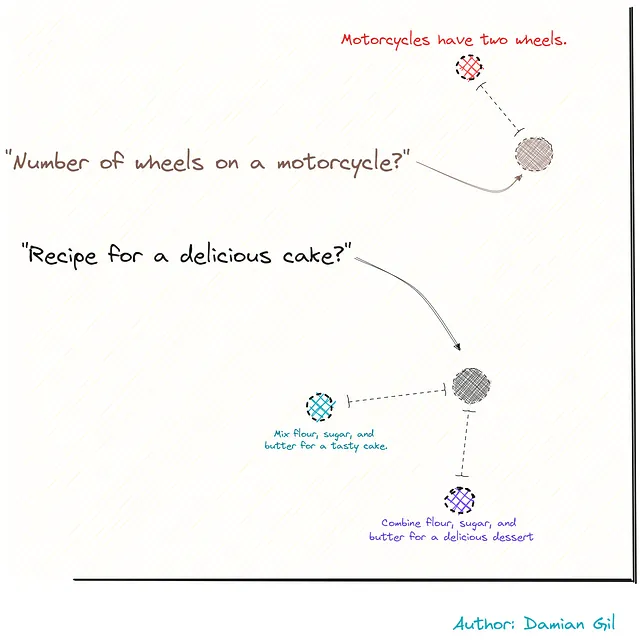
前の画像を覚えていますか…私たちには2つの質問があり、それらを積分を使用して数字に変換します。次に、距離を測定し、質問に最も近い文を見つけます。これらの文は完璧な組み合わせのようです!まるで瞬時に最高のパズルピースを見つけるようです! 🚀🧩🔍
6- 質問
目標は、ドキュメントに関する質問をすることと、それに対する回答を得ることです。このステップでは、ユーザーが提供した質問を収集します。
7 & 8- 関連する分割
ここで、質問をベクトルリポジトリに挿入し、文をデジタルベクトルに変換するために埋め込みます。次に、質問と文書の部分との距離を計算し、質問に最も近い部分を決定します。コードは以下の通りです:
# ベクトルストアのタイプに応じて、特定の関数を使用します。# すべての関数は、最も関連性の高い分割のリストを返します。def get_search(self, question, with_score=False): relevant_docs = None if self.db and "SVM" not in str(type(self.db)): if with_score: relevant_docs = self.db.similarity_search_with_relevance_scores(question) else: relevant_docs = self.db.similarity_search(question) elif self.db: relevant_docs = self.db.get_relevant_documents(question) return relevant_docs以下のコードで試してみてください。4つのアイテムのリストとして回答する方法を学びます。そして、中を見ると、実際には入力したドキュメントの別々の部分です。まるであなたの質問にぴったりの最高の4つのパズルピースを提供するアプリのようです! 🧩💬
9- 回答(自然言語)
素晴らしい、これで質問に関連性の高いテキストを持っています。ただし、それらの部分をユーザーに渡して終了するわけにはいきません。簡潔で正確な回答が必要です。そこで、私たちの言語モデル(LLM)が登場します!多くのLLMフレーバーがあります。コードでは、「flan-alpaca-large」をデフォルトに設定しています。感動する人を選ぶのに躊躇しないでください! 🚀🎉
以下は計画です:
- 質問に関連する最も重要な部分(分割)を復元します。
- 質問、回答の形式、およびこれらのテキスト要素を含むプロンプトを準備します。
- このプロンプトを私たちのインテリジェント言語モデル(LLM)に渡します。彼は質問とこれらの要素に含まれる情報を知っており、自然な回答を提供します。️
この最後の部分は次の画像で示されています: 🖼️
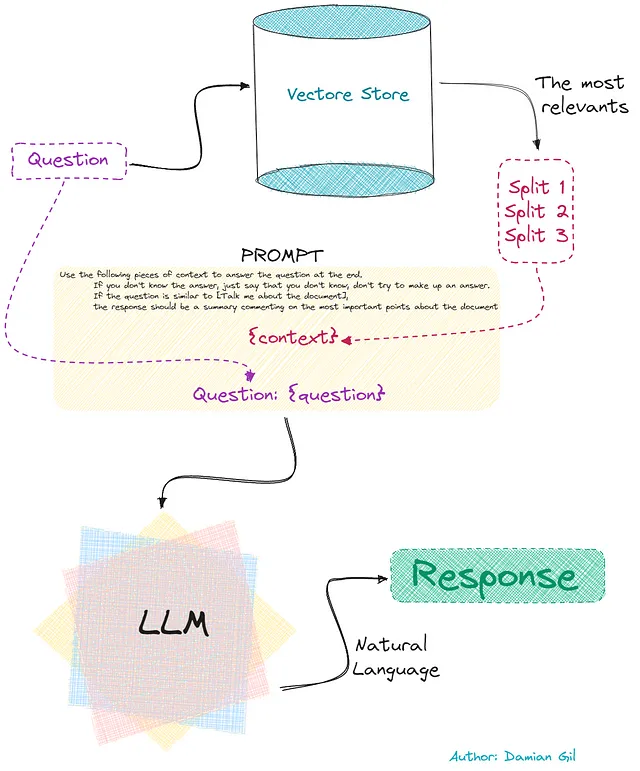
確かに、この正確なフローがコードで実行されるものです。コードでは、「prompt」という追加のステップがあることに気づくでしょう。実際には、LLMによって見つかった回答の組み合わせで最終的な回答を出すことができます。簡単にするために、最も簡単な方法で行いましょう:「stuff」。これは、LLMによって見つかった最初の解答です。ここでは、理論に迷うことはありません! 🌟
def do_question(self, question, repo_id="declare-lab/flan-alpaca-large", chain_type="stuff", relevant_docs=None, with_score=False, temperature=0, max_length=300): # 最も関連性の高い分割を取得する relevant_docs = self.get_search(question, with_score=with_score) # 使用するLLMを定義するため、# リポジトリIDを導入する必要があります(huggingfaceを使用しているため)。 self.repo_id = self.repo_id if self.repo_id is not None else repo_id chain_type = chain_type.lower() if chain_type.lower() in CHAIN_TYPE_LIST else CHAIN_TYPE_LIST[0] # このチェックは必要です。関数を複数回呼び出すことができますが、# LLMがクラス内に既に存在するか、# repo_id(LLMのタイプ)が変更されたかどうかをチェックします。 if (self.repo_id != repo_id ) or (self.llm is None): self.repo_id = repo_id # LLMを作成します。 self.llm = HuggingFaceHub(repo_id=self.repo_id,huggingfacehub_api_token=self.HF_API_TOKEN, model_kwargs= {"temperature":temperature, "max_length": max_length}) # プロンプトを作成する prompt_template = """以下のコンテキストの一部を使用して、最後の質問に回答してください。 答えを知らない場合は、知らないと言って、回答をでっち上げないでください。 質問が [ドキュメントについて話してください] に似ている場合、 応答はドキュメントに関する最も重要なポイントにコメントする要約であるべきです {context} 質問: {question} """ PROMPT = PromptTemplate( template=prompt_template, input_variables=["context", "question"] ) # チェーンを作成する、chain_type= "stuff" self.chain = self.chain if self.chain is not None else load_qa_chain(self.llm, chain_type=chain_type, prompt = PROMPT) # プロンプトを使用してLLMにクエリを作成する # チェーンが既に定義されているかどうかをチェックし、# 存在しない場合は作成します response = self.chain({"input_documents": relevant_docs, "question": question}, return_only_outputs=True) return responseおめでとう!ウェブアプリの脳がどのように動作するかを理解し終えました。ここまで来てくれたら最高ですね!さあ、記事の最後のセクションに進んで、ウェブアプリのページを探検しましょう。🎉🕵️♂️
ウェブアプリ
このインターフェースは、技術的な知識を持たない人々を対象に設計されていますので、問題なくこのテクノロジーを最大限に活用することができます。🚀👩💻
このサイトの使用は非常にシンプルでパワフルです。基本的に、ユーザーはドキュメントを提供するだけです。追加のパラメーターを活用する準備ができていない場合でも、次のステップで既に質問を始めることができます。🌟🤖
以下に従う手順を見てみましょう:
- ドキュメントまたはウェブリンクを提供します。ページ:ステップ1️⃣データベースの作成。
- 設定を行います(オプション)。ページ:ステップ1️⃣データベースの作成。
- 質問をして回答を得ます!📚🔍🚀ページ:ステップ2️⃣ドキュメントへの質問。
1. ドキュメントまたはウェブリンクを提供します。
このステップでは、ドキュメントをアップロードしてウェブに追加します。Face Hugging APIキーが環境変数として設定されていない場合、”ホーム”タブで入力を求められますので、ご注意ください。📂🔑
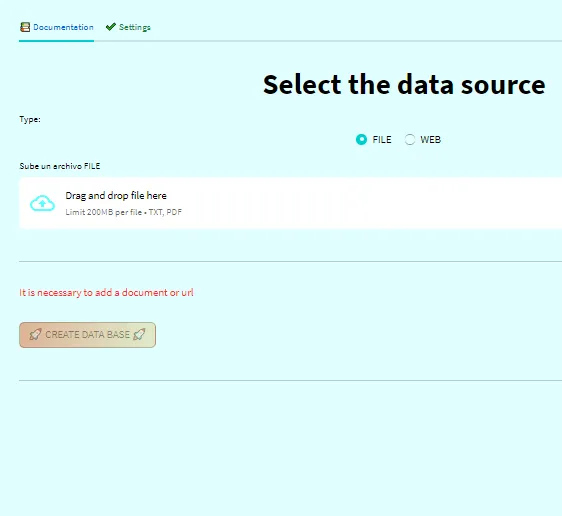
ドキュメントを添付し、設定を行った後、設定の要約表が表示されます。その後、「データベースの作成」ボタンがロック解除されます。ボタンをクリックすると、データベースまたはベクトルストアが作成され、質問セクションにリダイレクトされます。📑🔒🚀
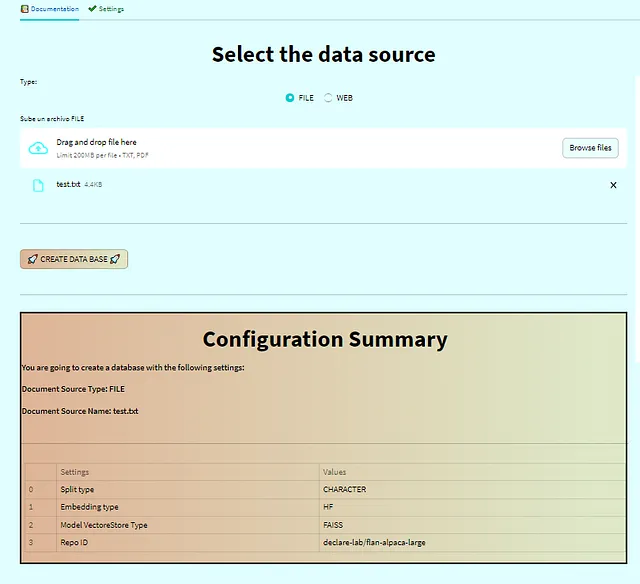
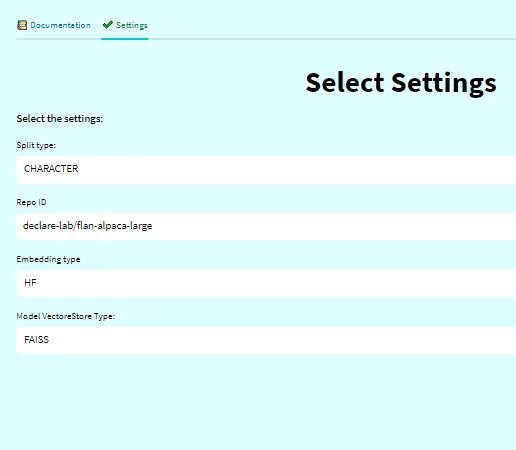
2. 設定を行います(オプション)。
先に述べたように、ベクトルストアを好みに応じて設定することができます。ドキュメントの分割や埋め込みなどには異なる方法があります。このタブでは、お好みに応じてカスタマイズできます。より速いセットアップのためのデフォルトの設定が付属しています。⚙️🛠️
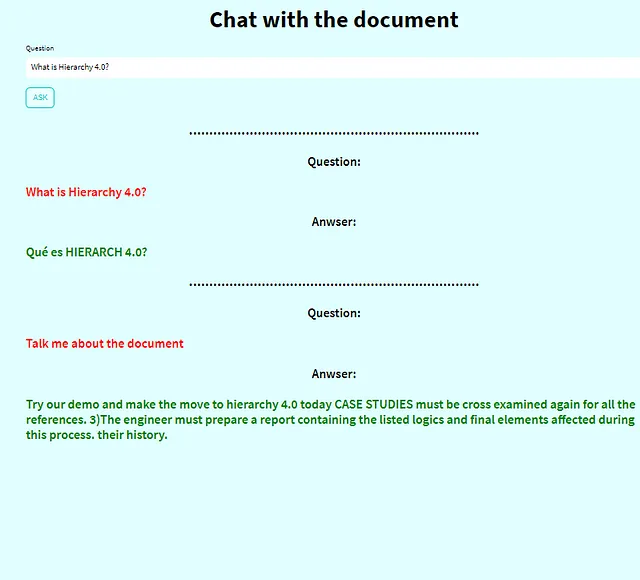
3. 質問をして回答を得ます!
この時点で、何でも質問することができます。今こそ、心ゆくまでツールを楽しんでインタラクトできる時間です!🤗🔍💬
急いでいる方のためのコード
早速始めたい方は、TalkDocumentクラスを直接取得し、Jupyterノートブックに貼り付けて試してみることができます。いくつかの依存関係をインストールする必要があるかもしれませんが、きっとチャレンジになることはないでしょう。楽しい時間を過ごして、探求や実験をしてください!ハッピーコーディング!! 🚀📚😄
コードで遊ぶためのTalkDocumentクラス(著者提供のコード)
まとめ
この興奮するような旅の最後までおめでとうございます!このWebアプリケーションの背後にある知識について深く掘り下げました。ドキュメントのアップロードから回答の取得まで、多くのことに取り組んできました!もしインスピレーションを感じたら、コードは私のGitHubリポジトリで入手できます。質問や提案があれば、お気軽にLinkedInで連絡してください!この強力なツールを使って、楽しみながら探求や実験をしてください!
もしよければ、私のGitHubをチェックしてください
damiangilgonzalez1995 – 概要
データに情熱を持ち、物理学からデータサイエンスに転向しました。Telefonica、HPで働き、現在はCTOです…
github.com
参考文献
- Langchainドキュメンテーション
- Hugging Faceドキュメンテーション
- Facebook AI類似検索(Faiss)入門
- Steamlitドキュメンテーション
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles




