「Underrepresented Groupsの存在下での学習について」
Learning under the presence of Underrepresented Groups
変化は難しい:サブポピュレーションシフトの詳細な調査(ICML 2023)
ICML 2023で受理された最新の研究、「変化は難しい:サブポピュレーションシフトの詳細な調査」をご紹介します。機械学習モデルは多くの応用分野で大きな可能性を示していますが、訓練データにおいてサブグループが十分に代表されていない場合には性能が低下することがよくあります。このようなサブポピュレーションシフトを引き起こすメカニズムの変動や、アルゴリズムが多様なシフトに対してどのように汎化するかを理解することはまだ課題となっています。本研究では、サブポピュレーションシフトと機械学習アルゴリズムへの影響について、詳細な分析を提供することを目指しています。
まず、サブグループの一般的なシフトを解析し説明する統一フレームワークを提案します。さらに、ビジョン、言語、医療の領域にわたる12の実世界データセットを評価するために、20の最新のアルゴリズムからなる包括的なベンチマークを導入します。分析とベンチマークにより、サブポピュレーションシフトおよび機械学習アルゴリズムが実世界のシフト下でどのように汎化するかについて興味深い観察と理解を提供します。コード、データ、モデルはGitHubでオープンソースとして公開されています:https://github.com/YyzHarry/SubpopBench。
背景と動機
機械学習モデルは、ディストリビューションのシフトが存在する状況下では頻繁に性能の低下を示します。このようなシフトは、トレーニングデータのディストリビューションがテストと異なる場合に生じ、モデルの展開時に性能低下を引き起こします。これらのシフトに対してロバストな機械学習モデルを構築することは、実世界での安全なモデルの展開には重要です。一般的なディストリビューションシフトの中でも、サブポピュレーションシフトと呼ばれるものがあります。これは、トレーニングと展開の間でいくつかのサブポピュレーションの割合が変化することを特徴としています。このような状況では、モデルは全体的な性能が高くても、まれなサブグループでは性能が低下する可能性があります。
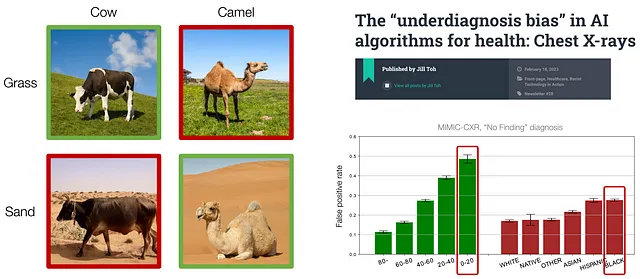
たとえば、牛とラクダの分類のタスクでは、牛は緑の草地に、ラクダは黄色い砂漠の背景によく存在します。しかし、このような相関は因果関係がないため、牛やラクダの存在は背景色と関係ありません。その結果、訓練されたモデルは上記の画像でうまく機能しますが、訓練データでは稀な背景色を持つ動物、例えば砂漠の中の牛や草地の中のラクダには汎化できません。
- アリババのChatGPTの競合相手、統一千文と出会ってください:その大規模言語モデルは、Tmall Genieスマートスピーカーや職場メッセージングプラットフォームのDingTalkに組み込まれる予定です
- 「ニューラルネットワークとディープラーニング:教科書(第2版)」
- 「FalconAI、LangChain、およびChainlitを使用してチャットボットを作成する」
また、医療診断においては、年齢や民族の代表されていないグループでは、機械学習モデルの性能が低下することが研究で明らかにされており、重要な公平性の懸念が生じています。
これらすべてのシフトは一般的にサブポピュレーションシフトと呼ばれていますが、サブポピュレーションシフトを引き起こすメカニズムの変動や、アルゴリズムがどのようにさまざまなシフトを汎化するかについてはほとんど理解されていません。では、サブポピュレーションシフトをどのようにモデル化するのでしょうか?
サブポピュレーションシフトの統一フレームワーク
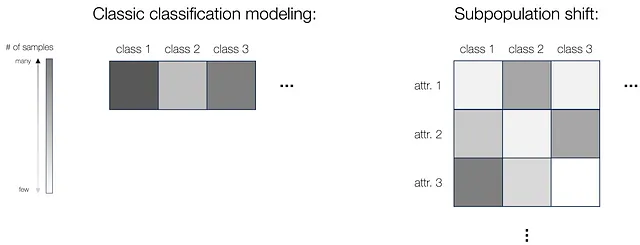
まず、サブポピュレーションシフトのモデリングに対する統一フレームワークを提供します。クラシックな分類の設定では、複数のクラスからのトレーニングデータがあります(異なる色の密度で異なるクラスのサンプル数を表すために使用されます)。しかし、サブポピュレーションシフトの場合、クラスに加えて属性が存在します(例えば牛とラクダの問題における背景色)。この場合、属性とラベルの両方に基づいて離散的なサブポピュレーションを定義することができます。また、同じクラス内の異なる属性のサンプル数も異なる場合があります(下の図を参照)。そして、モデルをテストするためには、すべてのクラスにわたる分類設定と同様に、すべてのサブグループに対してモデルをテストし、すべてのサブポピュレーションにおける最悪の性能が十分に良いか、またはすべてのグループで同じくらい良い性能を確保します。
具体的には、一般的な数学的な形式を提供するために、まずベイズの定理を使用して分類モデルを書き直します。さらに、各入力xを、基礎となるコアフィーチャー(X_core)のセットと属性(a)のリストによって完全に記述されるものと見なします。ここで、X_coreは、ラベルに固有の不変成分であり、堅牢な分類をサポートするものであり、属性aは一貫性のない分布を持ち、ラベルに固有ではありません。このモデリングを方程式に統合し、以下のように三つの項に分解することができます:
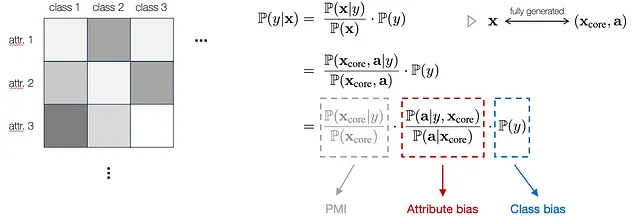
具体的には、最初の項はX_coreとyの間の点間相互情報量(PMI)を表し、これは潜在的なクラスラベルと関連する堅牢な指標です。 二つ目と三つ目の項は、属性の分布とラベルの分布に生じる潜在的なバイアスに対応します。このようなモデリングにより、サブポピュレーションシフト下で属性とクラスが結果にどのように影響を与えるかが説明されます。したがって、トレーニングとテストの分布間で不変のX_coreが与えられる場合、最初の項の変化を無視して、サブポピュレーションシフト下で属性とクラスが結果にどのように影響を与えるかに焦点を当てることができます。
このフレームワークに基づいて、私たちはサブポピュレーションシフトの四つの基本的なタイプを形式的に定義し、特徴付けしています: 偽の相関、属性の不均衡、クラスの不均衡、および属性の一般化。各タイプは、サブポピュレーションシフトにおいて潜在的に生じる基本的なシフトコンポーネントを構成します。
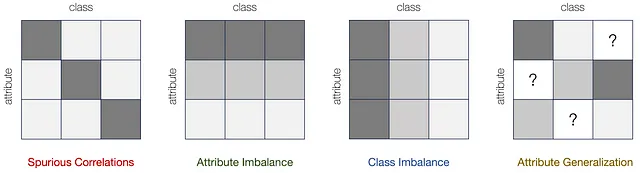
まず、特定の属性がトレーニングデータではラベルyと偽の相関を持つが、テストデータでは持たない場合、それは偽の相関を意味します。さらに、特定の属性が他の属性よりもはるかに小さい確率でサンプリングされる場合、それは属性の不均衡を引き起こします。同様に、クラスラベルは不均衡な分布を示すことがあり、少数派のラベルに対する優先度が低くなる可能性があります。これはクラスの不均衡を引き起こします。最後に、特定の属性がトレーニングでは完全に欠落しているが、テストでは特定のクラスに存在する場合、それは属性の一般化の必要性を示します。これらのシフトの属性/クラスのバイアスの源、および分類モデルへの影響は、以下の表にまとめられています:

これらの四つのケースは基本的なシフトコンポーネントを構成し、実際のデータにおける複雑なサブグループのシフトを説明するための重要な要素です。また、実際のデータセットでは、1つではなく複数のタイプのシフトが同時に存在することがよくあります。
SubpopBench:サブポピュレーションシフトのベンチマーク
このような形式を設定した後、私たちはSubpopBenchを提案します。これは、12の実世界のデータセットで評価された最先端のアルゴリズムを含む包括的なベンチマークです。特に、これらのデータセットは、ビジョン、言語、医療応用を含む、様々なモダリティとタスクから派生しており、データモダリティは自然画像、テキスト、臨床テキスト、胸部X線までさまざまです。これらのデータセットはまた、異なるシフトコンポーネントを示しています。
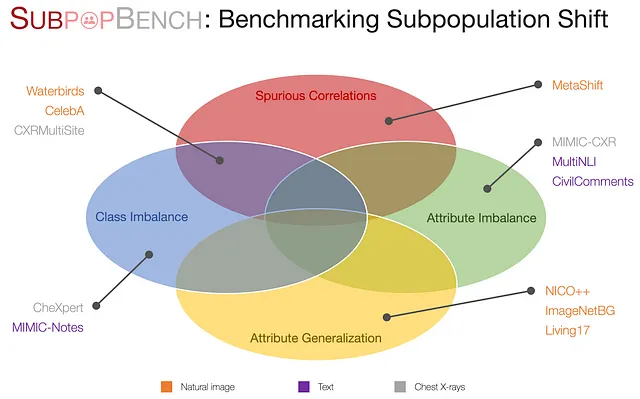

このベンチマークの詳細については、当社の論文をご参照ください。確立されたベンチマークと20の最新アルゴリズムを使用してトレーニングされた10,000以上のモデルにより、この分野の将来の研究における興味深い観察結果を明らかにします。
細かいサブポピュレーションシフトの分析
SOTAアルゴリズムは特定のタイプのシフトのみを改善する
まず、SOTAアルゴリズムは特定のタイプのシフトに対してのみサブグループの頑健性を改善することがわかりますが、他のタイプのシフトには改善されません。
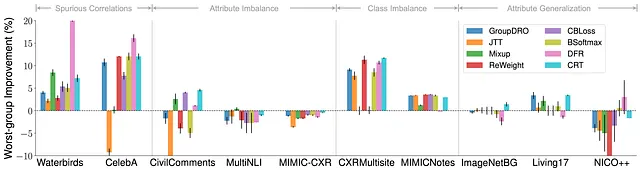
ここでは、既存のアルゴリズムがERMに対する最悪グループの正確性改善をプロットしています。偶発的な相関とクラスの不均衡に対しては、既存のアルゴリズムはERMに対して一貫した最悪グループの利益を提供できるため、これらの2つの特定のシフトに取り組むための進展があったことを示しています。
しかし興味深いことに、属性の不均衡に関しては、データセット全体でほとんど改善が見られません。さらに、属性の一般化については性能がさらに悪化します。
これらの結果から、現在の進歩は特定のシフトのみに対して行われていること、属性一般化などのより難しいシフトに対しては進展がなされていないことが強調されます。
表現と分類器の役割
さらに、サブポピュレーションシフトにおける表現と分類器の役割を探ることに興味があります。特に、全体のネットワークを特徴抽出器fと分類器gに分けます。fは入力から潜在的な特徴を抽出し、gは最終的な予測を出力します。表現と分類器はサブグループのパフォーマンスにどのように影響するのでしょうか?
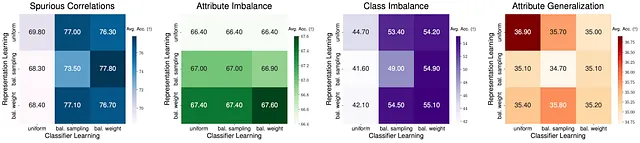
まず、基本的なERMモデルが与えられた場合、表現を固定したまま分類器の学習のみを最適化すると、偶発的な相関とクラスの不均衡に対するパフォーマンスが大幅に向上します。これは、ERMによって学習された表現がすでに十分に優れていることを示しています。しかし興味深いことに、属性の不均衡に対するパフォーマンスを向上させるためには、分類器ではなく表現学習を改善する必要があります。最後に、属性の一般化に対しては層別学習はパフォーマンスの向上につながりません。これは、異なるタイプのシフトに直面する場合には、モデルのパイプライン設計を考慮する必要があることを強調しています。
モデル選択と属性の可用性について
さらに、モデル選択と属性の可用性がサブポピュレーションシフトの評価にかなり影響を与えることを観察しました。
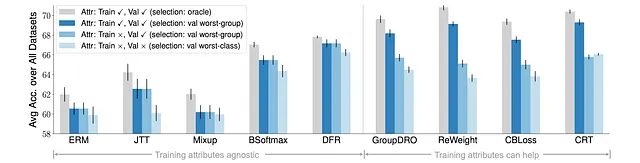
具体的には、訓練データと/または検証データから属性の注釈を徐々に削除すると、すべてのアルゴリズムのパフォーマンスが著しく低下しました、特に訓練データと検証データの両方に属性が利用できない場合です。
これは、サブポピュレーションシフトにおいては、属性へのアクセスがまだ妥当なパフォーマンスを得るために重要な役割を果たしており、将来のアルゴリズムはモデル選択と属性の可用性により現実的なシナリオを考慮する必要があることを示しています。
最悪グループの正確性を超えたメトリクス
最後に、サブポピュレーション評価における評価メトリクスの基本的なトレードオフを明らかにします。最悪グループの正確性、またはWGAは、サブポピュレーション評価のゴールドスタンダードとされています。しかし、WGAを改善することは、常に他の有意義なメトリクスを改善することを意味するのでしょうか?

まず、改善されたWGAは、調整された正確性などの特定のメトリックの向上につながる可能性があることを示します。ただし、最悪のケースでの精度をさらに考慮すると、WGAと非常に強い負の線形相関が現れることが驚くほど明らかになります。これは、サブポピュレーションのシフトにおけるモデルのパフォーマンスを評価するための唯一のメトリックとしてWGAを使用することの根本的な制限を明らかにします。つまり、高いWGAを持つよく実行されたモデルでも、最悪のクラスの精度が低い場合があります。これは、医療診断などの重要なアプリケーションにおいて特に懸念すべき状況です。
私たちの観察結果は、サブポピュレーションのシフトにおいてより現実的かつ広範な評価メトリックが必要であることを強調しています。また、私たちの論文では、WGAと逆相関する多くの他のメトリックも示しています。
結論
この記事のまとめとして、私たちはサブポピュレーションのシフト問題を体系的に調査し、異なるタイプのサブポピュレーションのシフトを定義し量化する統一フレームワークを形式化し、さらに実世界のデータにおける現実的な評価のための包括的なベンチマークを設定しました。私たちのベンチマークには、異なるドメインの20のSOTAメソッドと12の実世界のデータセットが含まれています。10,000以上のトレーニング済みモデルを基に、サブポピュレーションのシフトにおける興味深い特性を明らかにしました。私たちのベンチマークと研究結果が現実的かつ厳格な評価を促進し、サブポピュレーションのシフトにおける新たな進展にインスピレーションを与えることを願っています。最後に、私たちの論文のいくつかの関連リンクを添付します。お読みいただきありがとうございました!
コード: https://github.com/YyzHarry/SubpopBench
プロジェクトページ: https://subpopbench.csail.mit.edu/
トーク: https://www.youtube.com/watch?v=WiSrCWAAUNI
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- スタンフォード大学とGoogleからのこのAI論文は、生成エージェントを紹介しています生成エージェントは、人間の振る舞いをシミュレートするインタラクティブな計算エージェントです
- 「SegGPT」にお会いください:コンテキスト推論を通じて画像または動画の任意のセグメンテーションタスクを実行する汎用モデル
- 「識別可能であるが可視性がない:プライバシー保護に配慮した人物再識別スキーム(論文要約)」
- 「トップAIコンテンツ生成ツール(2023年)」
- 「AUDITに会おう:潜在拡散モデルに基づく指示に従ったオーディオ編集モデル」
- 「トップAIオーディオエンハンサー(2023年)」
- 「Auto-GPTに会ってください:GPT-4などのLLMの力を示す実験的なオープンソースアプリケーションで、異なる種類のタスクを自律的に開発および管理する能力を示します」






