ゼロから学ぶアテンションモデル
Learn Attention Models from Scratch
はじめに
アテンションモデル、またはアテンションメカニズムとも呼ばれるものは、ニューラルネットワークの入力処理技術に使用されるものです。これにより、ネットワークは複雑な入力の異なる側面に集中し、全データセットを分類するまでに個別に処理できます。目標は、複雑なタスクを順次処理される注目の小さな範囲に分解することです。このアプローチは、人間の心が新しい問題をより簡単なタスクに分解し、ステップバイステップで解決する方法に類似しています。アテンションモデルは、特定のタスクにより適応し、パフォーマンスを最適化し、関連情報に注意を払う能力を向上することができます。

NLPにおけるアテンションメカニズムは、過去10年間でディープラーニングにおける最も価値のある発展の1つです。TransformerアーキテクチャやGoogleのBERTなどの自然言語処理(NLP)は、最近の進歩をもたらしています。
学習目標
- ディープラーニングにおけるアテンションメカニズムの必要性、機能、モデルのパフォーマンスを向上させる方法を理解する。
- アテンションメカニズムの種類や使用例を知る。
- あなたのアプリケーションとアテンションメカニズムの使用のメリットとデメリットを探究する。
- アテンションの実装例に従ってハンズオンでの経験を得る。
この記事はData Science Blogathonの一部として公開されました。
アテンションフレームワークを使用するタイミング
アテンションフレームワークは、元々エンコーダー・デコーダー型のニューラル機械翻訳システムやコンピュータビジョンでのパフォーマンス向上に使用されました。従来の機械翻訳システムは、大規模なデータセットと複雑な機能を処理して翻訳を行っていましたが、アテンションメカニズムはこのプロセスを簡素化しました。アテンションメカニズムは、単語ごとに翻訳する代わりに、固定長のベクトルを割り当てて入力の全体的な意味と感情を捉え、より正確な翻訳を実現します。アテンションフレームワークは、エンコーダー・デコーダー型の翻訳モデルの制限に対処するのに特に役立ちます。入力のフレーズや文の正確なアラインメントと翻訳を可能にします。
アテンションメカニズムは、入力シーケンス全体を単一の固定コンテンツベクトルにエンコードするのではなく、各出力に対してコンテキストベクトルを生成することで、より効率的な翻訳が可能になります。アテンションメカニズムは翻訳の精度を向上させますが、常に言語的な完璧さを実現するわけではありません。しかし、オリジナルの入力の意図と一般的な感情を効果的に捉えることができます。要約すると、アテンションフレームワークは、従来の機械翻訳モデルの制限を克服し、より正確でコンテキストに対応した翻訳を実現するための貴重なツールです。
アテンションモデルはどのように動作するのか?
広い意味では、アテンションモデルは、クエリと一連のキー・バリューペアをマップする関数を使用して出力を生成します。これらの要素、クエリ、キー、値、および最終出力はすべてベクトルとして表されます。出力は、クエリと対応するキーの類似性を評価する互換性関数によって決定される重み付き平均値を取ることによって計算されます。
実践的な意味では、アテンションモデルは、人間が使用する視覚的アテンションメカニズムに近いものをニューラルネットワークで近似することを可能にします。人間が新しいシーンを処理する方法に似て、モデルは画像の特定の点に集中し、高解像度の理解を提供し、周囲の領域を低解像度で認識します。ネットワークがシーンをより良く理解するにつれて、焦点を調整します。
NumPyとSciPyを使用した一般的なアテンションメカニズムの実装
このセクションでは、PythonライブラリNumPyとSciPyを利用した一般的なアテンションメカニズムの実装を調べます。
まず、4つの単語のシーケンスのための単語埋め込みを定義します。単純化のために、単語埋め込みを手動で定義しますが、実際にはエンコーダーによって生成されます。
import numpy as np
# 4つの異なる単語のエンコード表現
word_1 = np.array([1, 0, 0])
word_2 = np.array([0, 1, 0])
word_3 = np.array([1, 1, 0])
word_4 = np.array([0, 0, 1])次に、単語埋め込みと乗算されるクエリ、キー、および値を生成する重み行列を生成します。この例では、これらの重み行列をランダムに生成しますが、実際のシナリオではトレーニング中に学習されます。
np.random.seed(42)
W_Q = np.random.randint(3, size=(3, 3))
W_K = np.random.randint(3, size=(3, 3))
W_V = np.random.randint(3, size=(3, 3))次に、単語埋め込みと対応する重み行列の間で行列乗算を実行することにより、各単語のクエリ、キー、バリューのベクトルを計算します。
query_1 = np.dot(word_1, W_Q)
key_1 = np.dot(word_1, W_K)
value_1 = np.dot(word_1, W_V)
query_2 = np.dot(word_2, W_Q)
key_2 = np.dot(word_2, W_K)
value_2 = np.dot(word_2, W_V)
query_3 = np.dot(word_3, W_Q)
key_3 = np.dot(word_3, W_K)
value_3 = np.dot(word_3, W_V)
query_4 = np.dot(word_4, W_Q)
key_4 = np.dot(word_4, W_K)
value_4 = np.dot(word_4, W_V)次に、最初の単語のクエリベクトルをすべてのキーベクトルにドット積演算を使用してスコアリングします。
scores = np.array([np.dot(query_1,key_1),
np.dot(query_1,key_2),np.dot(query_1,key_3),np.dot(query_1,key_4)])重みを生成するために、スコアに対してsoftmax操作を適用します。
weights = np.softmax(scores / np.sqrt(key_1.shape[0]))最後に、すべてのバリューベクトルの重み付き合計を取ることにより、注意力の出力を計算します。
attention=(weights[0]*value_1)+(weights[1]*value_2)+(weights[2]*value_3)+(weights[3]*value_4)
print(attention)これらの計算を行列形式で実行することにより、4つの単語すべての注意力出力を同時に取得することができます。次に例を示します。
import numpy as np
from scipy.special import softmax
# 4つの異なる単語のエンコーダ表現を表現する
word_1 = np.array([1, 0, 0])
word_2 = np.array([0, 1, 0])
word_3 = np.array([1, 1, 0])
word_4 = np.array([0, 0, 1])
# 単語埋め込み
words = np.array([word_1, word_2, word_3, word_4])
# 重み行列を生成する
np. random.seed(42)
W_Q = np. random.randint(3, size=(3, 3))
W_K = np. random.randint(3, size=(3, 3))
W_V = np. random.randint(3, size=(3, 3))
# クエリ、キー、バリューを生成する
Q = np.dot(words, W_Q)
K = np.dot(words, W_K)
V = np.dot(words, W_V)
# スコアリングベクトルクエリ
scores = np.dot(Q, K.T)
# ソフトマックス操作を適用してウェイトを計算する
weights = softmax(scores / np.sqrt(K.shape[1]), axis=1)
# 重み付きバリューベクトルの加重平均を計算することにより、注意力を計算する
attention = np.dot(weights, V)
print(attention)注意モデルの種類
- グローバルアテンションとローカルアテンション(local-m、local-p)
- ハードアテンションとソフトアテンション
- セルフアテンション
グローバルアテンションモデル
グローバルアテンションモデルは、現在の状態以前のすべてのソース状態(エンコーダ)とデコーダ状態から入力を考慮して出力を計算します。ソースシーケンスとターゲットシーケンスの関係を考慮します。以下は、グローバルアテンションモデルを説明する図です。
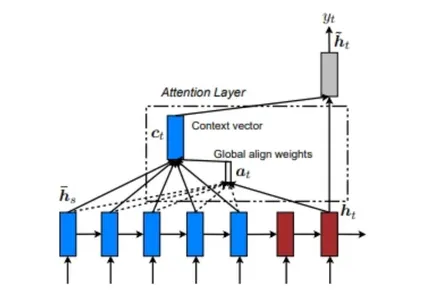
グローバルアテンションモデルでは、アラインメントウェイトまたは注意ウェイト(a<t>)は、各エンコーダステップとデコーダの前のステップ(h<t>)を使用して計算されます。アラインメントウェイトを使用してエンコーダ出力の重み付き和を取ることにより、このリファレンスベクトルがRNNセルに供給されて、デコーダ出力を決定します。
ローカルアテンションモデル
ローカルアテンションモデルは、アラインメントウェイト(a<t>)を計算する際に、ソース(エンコーダ)の一部の位置のみを考慮します。以下は、ローカルアテンションモデルを説明する図です。

ローカル注意モデルは、提供された図から理解することができます。単一の整列位置(p<t>)を見つけ、ソース(エンコーダ)層から単語のウィンドウと(h<t>)を使用して、整列重みとコンテキストベクトルを計算することを含みます。
ローカル注意には2種類あります:単調な整列と予測的な整列です。単調な整列では、位置(p<t>)は単純に「t」と設定されますが、予測的な整列では、位置(p<t>)は「t」と仮定するのではなく、予測モデルによって予測されます。
ハードアテンションとソフトアテンション
ソフトアテンションとグローバルアテンションモデルは機能的に類似していますが、ハードアテンションとローカルアテンションモデルには明確な違いがあります。主な違いは、差分性の特性にあります。ローカルアテンションモデルは各点で差分可能であり、ハードアテンションは差分可能性がないため、最適化において課題が発生します。
セルフアテンションモデル
セルフアテンションモデルは、同じ入力シーケンス内の異なる場所の間に関係を確立することを含みます。原理的に、セルフアテンションは以前に言及されたスコア関数のいずれかを使用できますが、ターゲットシーケンスは同じ入力シーケンスで置き換えられます。
トランスフォーマーネットワーク
トランスフォーマーネットワークは、再帰的なネットワークアーキテクチャを使用せずに完全に自己注意機構に基づいて構築されています。トランスフォーマーは、マルチヘッドのセルフアテンションモデルを利用しています。

アテンションメカニズムの利点と欠点
アテンションメカニズムは、ディープラーニングモデルの性能を向上させるための強力なツールであり、いくつかの主要な利点があります。アテンションメカニズムの主な利点のいくつかは以下のとおりです。
- 精度の向上:アテンションメカニズムは、モデルが最も関連性の高い情報に集中することによって予測の精度を向上させることに貢献します。
- 効率の向上:最も重要なデータのみを処理することにより、アテンションメカニズムはモデルの効率を向上させます。これにより、必要な計算リソースが減少し、モデルのスケーラビリティが向上します。
- 解釈性の向上:モデルが学習したアテンションウェイトは、データの最も重要な側面に関する貴重な洞察を提供します。これは、モデルの解釈性を向上させ、その意思決定プロセスを理解するのに役立ちます。
ただし、アテンションメカニズムには考慮すべき欠点もあります。主な欠点は以下のとおりです。
- トレーニングの困難さ:特に大規模で複雑なタスクの場合、アテンションメカニズムのトレーニングは困難になる場合があります。データからアテンションウェイトを学習することは、多大なデータと計算リソースを必要とすることがしばしばあります。
- 過学習:アテンションメカニズムは過学習に陥りやすいです。モデルがトレーニングデータ上でうまく機能する場合でも、新しいデータに対して効果的に一般化することができない場合があります。正則化技術を利用することで、この問題を軽減できますが、大規模で複雑なタスクに対しては依然として課題が残ります。
- 露出バイアス:トレーニング中にアテンションメカニズムが露出バイアスの問題に直面することがあります。これは、モデルが一度に出力シーケンスを生成することを評価する一方で、出力シーケンスをステップごとに生成するようにトレーニングされる場合に発生します。この相違により、モデルは完全な出力シーケンスを正確に再現することができず、テストデータでの性能が低下する可能性があります。
アテンションメカニズムの利点と欠点を認識することは、ディープラーニングモデルでの使用に関する情報を提供するために重要です。
アテンションフレームワークの使用に役立つヒント
アテンションフレームワークを実装する際には、以下のヒントを考慮して、その効果を向上させることができます。
- 異なるモデルを理解する:利用可能なさまざまなアテンションフレームワークモデルに精通してください。各モデルには独自の機能と利点があり、それらを評価することで、正確な結果を得るための最適なフレームワークを選択することができます。
- 一貫したトレーニングを提供する:ニューラルネットワークの一貫したトレーニングは重要です。バックプロパゲーションや強化学習などの技術を利用して、アテンションフレームワークの効果と精度を向上させます。これにより、モデル内の潜在的なエラーを特定し、パフォーマンスを磨き、向上させることができます。
- アテンションメカニズムを翻訳プロジェクトに適用する :特に言語翻訳に向いています。アテンションメカニズムを翻訳タスクに組み込むことで、翻訳の精度を向上することができます。アテンションメカニズムは、異なる単語に適切な重みを割り当て、その関連性を捉え、総合的な翻訳品質を向上させます。
Attention Mechanismsの応用
Attention Mechanismsの主な用途は以下の通りです。
- 自然言語処理(NLP)のタスク、機械翻訳、テキスト要約、および質問応答にAttention Mechanismsを使用することです。これらのメカニズムは、モデルが与えられたテキスト内の単語の意味を理解し、最も重要な情報を強調するのに重要な役割を果たします。
- 画像分類や物体認識などのコンピュータビジョンタスクもAttention Mechanismsの恩恵を受けます。Attentionを使うことで、モデルは画像の一部を識別し、特定のオブジェクトに焦点を合わせて分析することができます。
- 音声認識タスクでは、録音された音声を文字に起こし、音声コマンドを認識することが求められます。Attention Mechanismsは、オーディオ信号のセグメントに集中して、話された単語を正確に認識することで、タスクに有用です。
- Attentional Mechanismsは、メロディの生成やコード進行などの音楽制作タスクでも役立ちます。Attentionを利用することで、モデルは重要な音楽要素を強調し、一貫性のある表現力豊かな作品を生成することができます。
結論
Attention Mechanismsは、コンピュータビジョンを含むさまざまな領域で広く使用されています。ただし、Attentional Mechanismsの研究開発のほとんどは、ニューラル機械翻訳(NMT)に集中しています。従来の自動翻訳システムは、各単語の統計的特性をマップする複雑な機能を持つ広範なラベル付きデータセットに重く依存しています。
対照的に、Attentional MechanismsはNMTに対してより単純なアプローチを提供します。このアプローチでは、文の意味を固定長のベクトルにエンコードし、翻訳の生成に利用します。単語ごとに翻訳するのではなく、Attention Mechanismsは文の全体的な感情や高レベルの情報を捉えることに注力します。この学習駆動型アプローチを採用することで、NMTシステムは重要な精度向上を実現するだけでなく、より簡単な構築とより速いトレーニングプロセスの恩恵を受けることができます。
キーポイント
- Attention Mechanismsは、ディープラーニングモデルに統合されるニューラルネットワークレイヤーです。
- タスクに関連性に基づいて重みを割り当てることで、モデルは入力の特定の部分に焦点を合わせることができます。
- Attention Mechanismsは、機械翻訳、画像キャプション、音声認識を含むさまざまなタスクで高い効果を発揮します。
- 長い入力シーケンスを扱う場合、Attention Mechanismsは、モデルが最も関連性の高い部分に選択的に焦点を合わせることができるため、特に有利です。
- Attention Mechanismsは、モデルが注目している入力の部分を視覚的に表現することで、モデルの解釈性を向上させることができます。
よくある質問
この記事に表示されるメディアはAnalytics Vidhyaの所有物ではなく、著者の裁量で使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






