大規模画像モデルのための最新のCNNカーネル
Latest CNN kernel for large-scale image models
デフォーマブル畳み込みネットワーク(DCNv2、DCNv3)における最新の畳み込みカーネル構造の高レベル概要

OpenAIのChatGPTの驚異的な成功により、大規模な言語モデルのブームが起こり、多くの人々が大規模な画像モデルの次のブレークスルーを予想しています。この領域では、ビジョンモデルは現在のChatGPTと同様の方法で画像や動画を分析し、生成するように促されることがあります。
大規模な画像モデルのための最新のディープラーニング手法は、畳み込みニューラルネットワーク(CNN)に基づくものとトランスフォーマに基づくものの2つの主要な方向に分かれています。この記事では、CNN側に焦点を当て、これらの改良されたCNNカーネル構造の高レベルな概要を提供します。
目次
- DCN
- DCNv2
- DCNv3
1. デフォーマブル畳み込みネットワーク(DCN)
従来、CNNカーネルは各レイヤーの固定された位置に適用され、すべてのアクティベーションユニットが同じ受容野を持つことになります。
以下の図のように、入力特徴マップxに対して畳み込みを行うために、各出力位置p0の値は、カーネルの重みwとx上のスライディングウィンドウとの要素ごとの乗算と合計として計算されます。スライディングウィンドウは、グリッドRによって定義され、p0の受容野でもあります。グリッドRのサイズは、yの同じレイヤー内のすべての位置で同じままです。
- 「生成AI技術によって広まる気候情報の誤情報の脅威」
- 「CREATORと出会ってください:ドキュメントとコードの実現を通じて、LLMs自身が自分のツールを作成するための革新的なAIフレームワーク」
- アバカスAIは、新しいオープンロングコンテキスト大規模言語モデルLLM「ジラフ」を紹介します
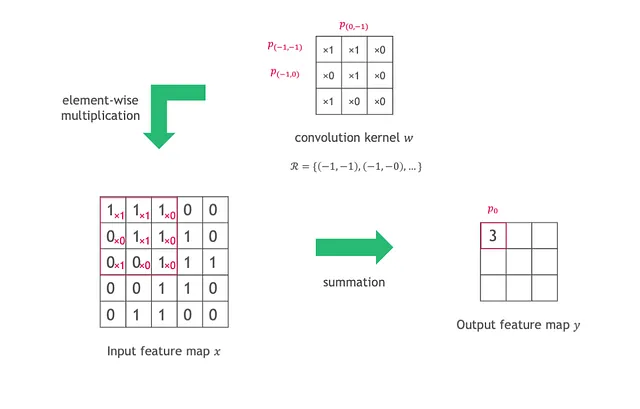
各出力値は以下のように計算されます:
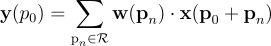
ここで、pnはスライディングウィンドウ(グリッドR)内の位置を列挙します。
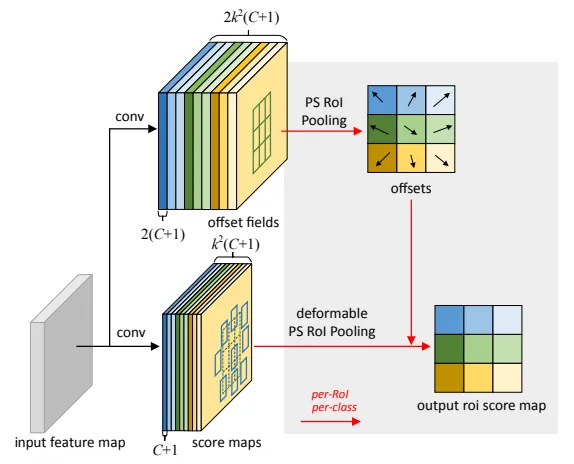
RoI(興味領域)プーリング操作も、各レイヤーで固定サイズのビンで操作されます。nijピクセルを含む(i、j)番目のビンのプーリング結果は、次のように計算されます:

再び、各レイヤーでビンの形状とサイズは同じです。
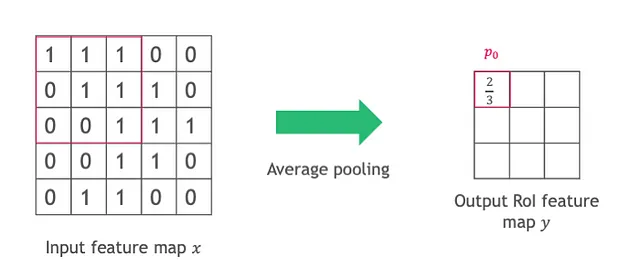
両方の操作は、スケールの異なるオブジェクトなどの意味をエンコードする高レベルのレイヤーで特に問題となります。
DCNは、これらの幾何学的構造をより柔軟にモデル化するための変形可能な畳み込みと変形可能なプーリングを提案しています。両方の操作は2D空間領域で操作されますが、操作はチャネル次元全体で同じままです。
変形可能な畳み込み

入力特徴マップxが与えられた場合、出力特徴マップyの各位置p0に対して、DCNは正規グリッドR内の各位置pnを列挙する際に、2Dのオフセット△pnを追加します。
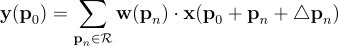
これらのオフセットは、特徴マップ上の追加の畳み込み層を通じて得られる前の特徴マップから学習されます。これらのオフセットは通常、分数であるため、バイリニア補間によって実装されます。
可変RoIプーリング
畳み込み演算と同様に、元のビニング位置にプーリングオフセット△pijが追加されます。
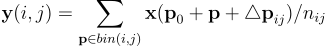
以下の図のように、これらのオフセットは、元のプーリング結果の後に完全連結(FC)層を介して学習されます。
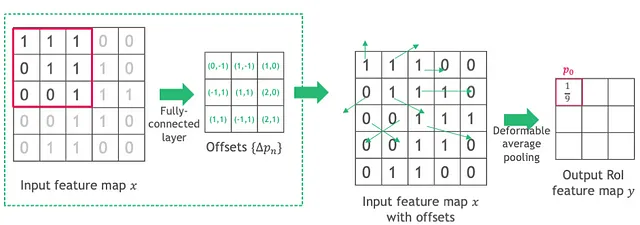
可変位置感度(PS)RoIプーリング
PS RoIプーリング(Dai et al., n.d.)に可変操作を適用する場合、以下の図に示すように、オフセットは入力特徴マップではなく各スコアマップに適用されます。これらのオフセットは、FC層ではなくconv層を介して学習されます。
位置感度RoIプーリング(Dai et al., n.d.):従来のRoIプーリングでは、各領域がどのオブジェクトパーツを表しているかの情報が失われます。PS RoIプーリングは、入力特徴マップを各オブジェクトクラスに対してk²個のスコアマップに変換することで、この情報を保持するために提案されています。各スコアマップは特定の空間部分を表します。したがって、C個のオブジェクトクラスに対して、合計k²(C+1)個のスコアマップがあります。
2. DCNv2
DCNは受容野内の各ピクセルが応答に等しく貢献すると仮定していますが、これはしばしば事実ではありません。貢献の振る舞いをより良く理解するために、著者は以下の3つの方法を使用して空間的なサポートを可視化します:
- 有効受容野:各画像ピクセルの強度摂動に対するノード応答の勾配
- 有効サンプリング/ビン位置:サンプリング/ビン位置に関するネットワークノードの勾配
- エラーバウンドされた注目領域:画像の一部を段階的にマスクし、全体の画像と同じ応答を生成する最小の画像領域を見つける
受容野内の場所に学習可能な特徴振幅を割り当てるために、DCNv2は変形可能なモジュールを導入します:
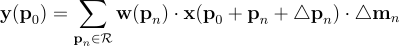
位置p0に対して、オフセット△pnとその振幅△mnは、同じ入力特徴マップに適用される別々の畳み込み層を通じて学習可能です。
DCNv2は、(i,j)番目のビンごとに学習可能な振幅△mijを追加することで、改訂された変形RoIプーリングを実現しました。

DCNv2は、ResNet-50のconv3からconv5の段階で通常の畳み込み層を変形畳み込み層に置き換えるために、畳み込み層をより広く使用します。
3. DCNv3
DCNv2からパラメータサイズとメモリの複雑さを削減するために、DCNv3はカーネル構造に以下の調整を加えています。
- 深度方向に分離された畳み込み(Chollet、2017による)に触発されたもの
深度方向に分離された畳み込みは、従来の畳み込みを以下に分けます:1. 深度方向の畳み込み:入力特徴の各チャンネルがフィルタと個別に畳み込まれる。2. ポイント方向の畳み込み:チャンネル全体に対して適用される1×1の畳み込み。
著者たちは、特徴の振幅mを深度方向の部分とし、グリッド内の位置とは関係ない射影重みwをポイント方向の部分とすることを提案しています。
2. グループ畳み込み(Krizhevsky、Sutskever、およびHinton、2012による)に触発されたもの
グループ畳み込み:入力チャンネルと出力チャンネルをグループに分け、各グループに別々の畳み込みを適用します。
DCNv3(Wangら、2023)は畳み込みをGグループに分割し、各グループごとに独立したオフセット△pgnと特徴の振幅△mgnを持つように提案しています。
したがって、DCNv3は次のように定義されます:
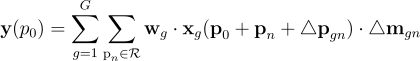
ここで、Gは畳み込みグループの総数です。wgは位置に関係なく、△mgnはsoftmax関数によって正規化され、グリッドR全体の和が1になります。
パフォーマンス
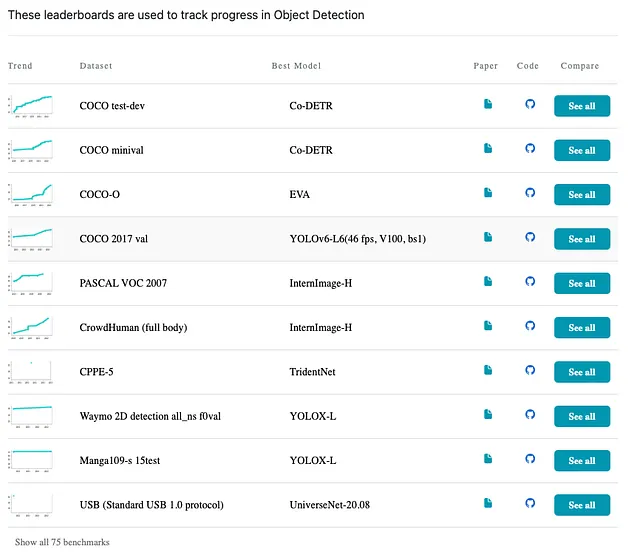
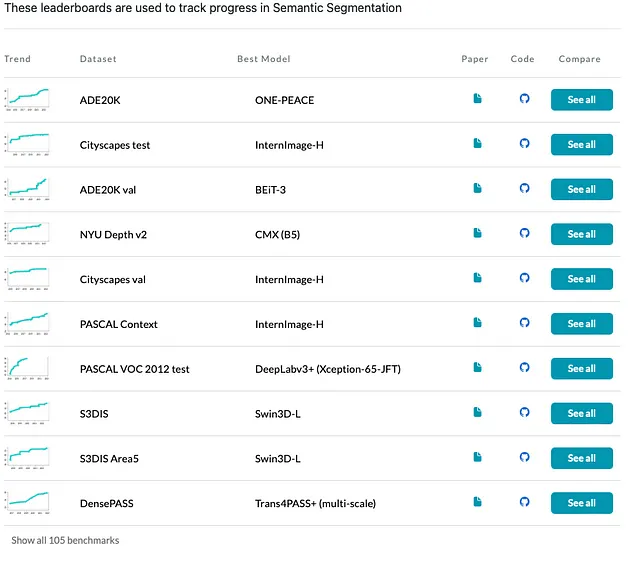
これまでに、DCNv3ベースのInternImageは、検出やセグメンテーションなどの複数の下流タスクで優れた性能を示しており、以下の表やpaperswithcode.comのリーダーボードでも確認できます。詳細な比較については、元の論文を参照してください。

概要
この記事では、通常の畳み込みネットワークのカーネル構造と、デフォーマブル畳み込みネットワーク(DCN)およびその新しいバージョンであるDCNv2とDCNv3を含む最新の改良についてレビューしました。従来の構造の制限について議論し、以前のバージョンを基にしたイノベーションの進歩を強調しました。これらのモデルのより深い理解については、参考文献セクションの論文をご覧ください。
謝辞
この記事を作成することをインスピレーションとし、素晴らしいアイデアを共有してくれたKenneth Leungに特に感謝します。また、この記事の改善に貢献してくれたKenneth、Melissa Han、Annie Liaoにも心から感謝します。貴重な提案と建設的なフィードバックは、コンテンツの品質と深さに大きな影響を与えました。
参考文献
Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H. and Wei, Y. (n.d.). Deformable Convolutional Networks. [オンライン] Available at: https://arxiv.org/pdf/1703.06211v3.pdf.
Zhu, X., Hu, H., Lin, S. and Dai, J. (n.d.). Deformable ConvNets v2: More Deformable, Better Results. [オンライン] Available at: https://arxiv.org/pdf/1811.11168.pdf.
Wang, W., Dai, J., Chen, Z., Huang, Z., Li, Z., Zhu, X., Hu, X., Lu, T., Lu, L., Li, H., Wang, X. and Qiao, Y. (n.d.). InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions. [オンライン] Available at: https://arxiv.org/pdf/2211.05778.pdf [参照日:2023年7月31日].
Chollet, F. (n.d.). Xception: Deep Learning with Depthwise Separable Convolutions. [オンライン] Available at: https://arxiv.org/pdf/1610.02357.pdf.
Krizhevsky, A., Sutskever, I. and Hinton, G.E. (2012). ImageNet classification with deep convolutional neural networks. Communications of the ACM, 60(6), pp.84–90. doi:https://doi.org/10.1145/3065386.
Dai, J., Li, Y., He, K. and Sun, J. (n.d.). R-FCN: Object Detection via Region-based Fully Convolutional Networks. [オンライン] Available at: https://arxiv.org/pdf/1605.06409v2.pdf.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「非常にシンプルな数学が大規模言語モデル(LLMs)の強化学習と高次関数(RLHF)に情報を提供できるのか? このAIの論文はイエスと言っています!」
- 「LEVER(リーバー)とは、生成されたプログラムの実行結果を検証することを学習することで、言語からコードへの変換を改善するためのシンプルなAIアプローチです」
- AWSの知的ドキュメント処理を生成AIで強化する
- マシンラーニングのロードマップ:コミュニティの推奨事項2023
- 「生成的なAIアプリケーションと3D仮想世界の構築方法」
- 「メーカーに会う:開発者がAI搭載ピットドロイドの背後にNVIDIA Jetsonを使う」
- 「チューリングテストと中国の部屋の議論に基づく大規模言語モデル」






