ソフトウェア開発活動のための大規模シーケンスモデル
Large-scale sequence model for software development activities.
Google の研究科学者である Petros Maniatis と Daniel Tarlow が投稿しました。
ソフトウェアは一度に作られるわけではありません。編集、ユニットテストの実行、ビルドエラーの修正、コードレビューのアドレス、編集、リンターの合意、そしてより多くのエラーの修正など、少しずつ改善されていきます。ついには、コードリポジトリにマージするに十分な良い状態になります。ソフトウェアエンジニアリングは孤立したプロセスではなく、人間の開発者、コードレビュワー、バグ報告者、ソフトウェアアーキテクト、コンパイラ、ユニットテスト、リンター、静的解析ツールなどのツールの対話です。
今日、私たちは DIDACT(Dynamic Integrated Developer ACTivity)を説明します。これは、ソフトウェア開発の大規模な機械学習(ML)モデルをトレーニングするための方法論です。 DIDACT の新規性は、完成したコードの磨き上げられた最終状態だけでなく、ソフトウェア開発のプロセス自体をトレーニングデータのソースとして使用する点にあります。開発者が作業を行う際に見るコンテキストと、それに対するアクションを組み合わせて、モデルはソフトウェア開発のダイナミクスについて学び、開発者が時間を費やす方法により合わせることができます。私たちは、Google のソフトウェア開発の計装を活用して、開発者活動データの量と多様性を以前の作品を超えて拡大しました。結果は、プロのソフトウェア開発者にとっての有用性と、一般的なソフトウェア開発スキルを ML モデルに注入する可能性という2つの側面で非常に有望です。
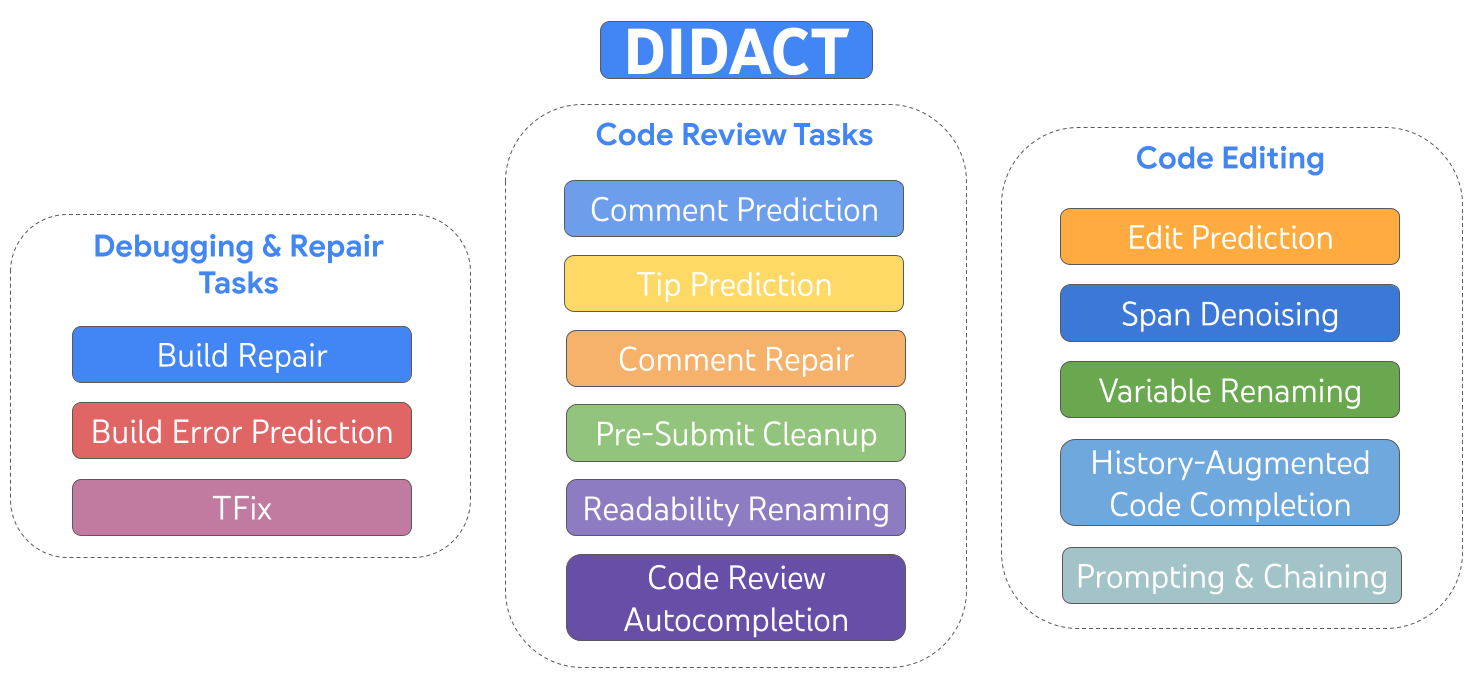 |
| DIDACT は、編集、デバッグ、修復、およびコードレビューを含む開発活動をトレーニングするマルチタスクモデルです。 |
私たちは DIDACT Comment Resolution(最近発表しました)、Build Repair、および Tip Prediction の 3 つのツールを内部で作成して展開しました。それぞれが開発ワークフローの異なる段階で統合されています。これら 3 つのツールは、内部の数千人の開発者から熱烈なフィードバックを受けました。私たちは、これを有用性の究極のテストと考えています。コードベースのエキスパートであり、ワークフローを注意深く磨いているプロの開発者が、生産性を向上させるためにこれらのツールを活用しているかどうかです。
- 人間の注意力を予測するモデルを通じて、心地よいユーザーエクスペリエンスを実現する
- デジタルルネッサンス:NVIDIAのNeuralangelo研究が3Dシーンを再構築
- NYUとNVIDIAが協力して、患者の再入院を予測するための大規模言語モデルを開発する
もっとも興奮することには、DIDACT が一般的な目的の開発者支援エージェントに向けた第一歩であることが示されていることです。トレーニングされたモデルが、開発者のアクティビティの接頭辞でプロンプトすることや、複数の予測を連鎖させてより長いアクティビティの軌跡を展開することを通じて、多様な驚くべき方法で使用できることを示しています。 DIDACT は、ソフトウェア開発プロセス全体にわたって一般的に支援できるエージェントの開発に向けて、有望な道を開拓していると考えています。
ソフトウェアエンジニアリングプロセスに関するデータの宝庫
Google のソフトウェアエンジニアリングツールチェーンは、コードに関連するすべての操作をツールと開発者の間の相互作用のログとして保存しており、数十年にわたってそのようにしてきました。原則として、Google のコードベースがどのようにして、ステップバイステップで、1つのコード編集、コンパイル、コメント、変数の名前変更などを含めて、「ソフトウェアエンジニアリングビデオ」の主要なエピソードを詳細に再生するためにこの記録を使用できます。
Google のコードは、すべてのツールとシステムのための単一のコードリポジトリである monorepo に存在します。ソフトウェア開発者は、通常、Clients in the Cloud(CitC)と呼ばれるシステムによって管理されるローカルのコピーを書き換え可能なワークスペースでコード変更の実験を行います。開発者が特定の目的(例:バグ修正)のためにコード変更のセットをパッケージ化する準備ができたら、Critique という Google のコードレビューシステムでチェンジリスト(CL)を作成します。他の種類のコードレビューシステムと同様に、開発者は機能とスタイルについての同僚レビュワーとの対話を行います。対話が進むにつれて、開発者は CL を編集してレビューコメントに対応します。最終的に、レビュワーは「LGTM!」(「私にとっては良いように見える」)と宣言し、CL がコードリポジトリにマージされます。
もちろん、コードレビュワーとの対話に加えて、開発者はコンパイラ、テストフレームワーク、リンター、静的解析ツール、fuzzer など、多数の他のソフトウェアエンジニアリングツールとも「対話」を維持します。
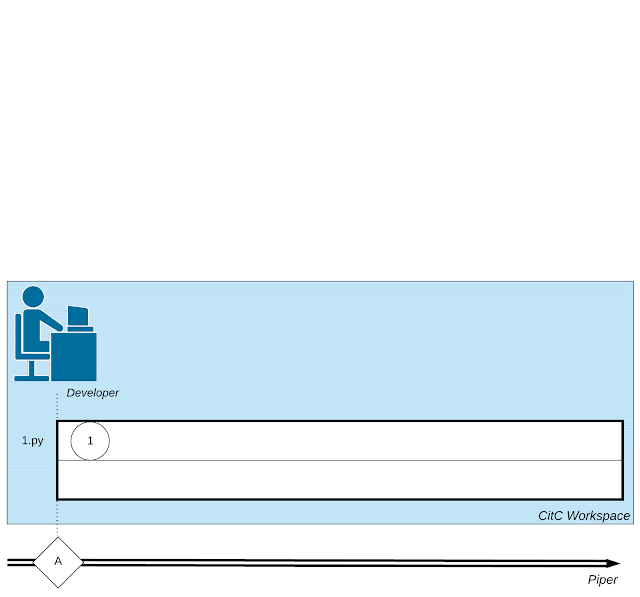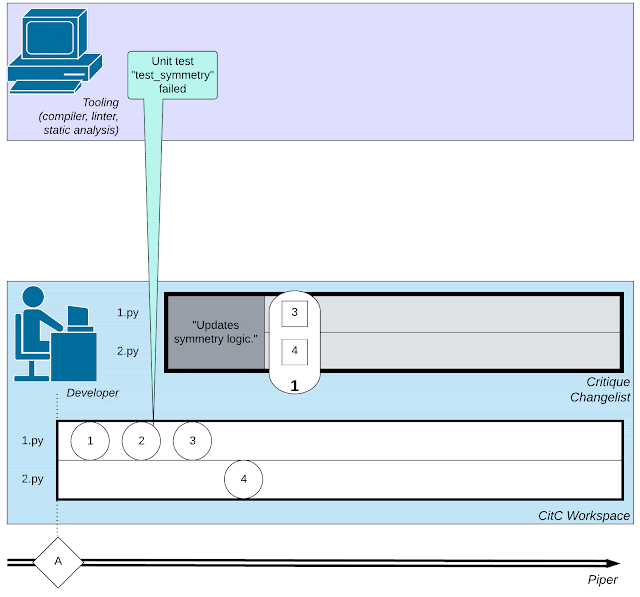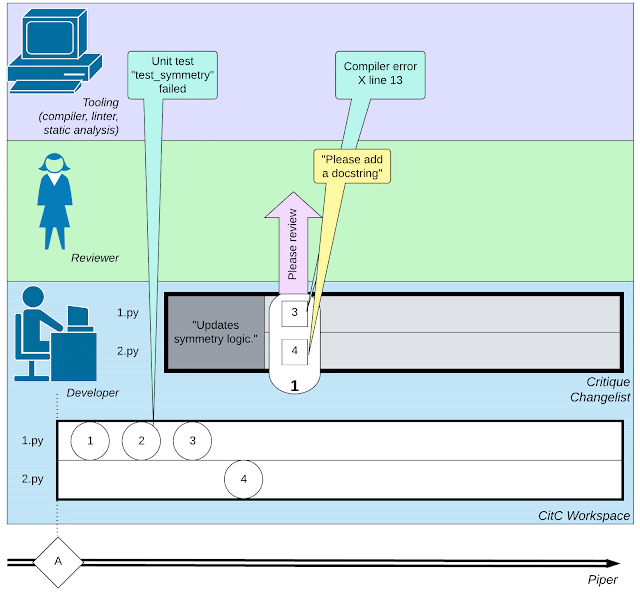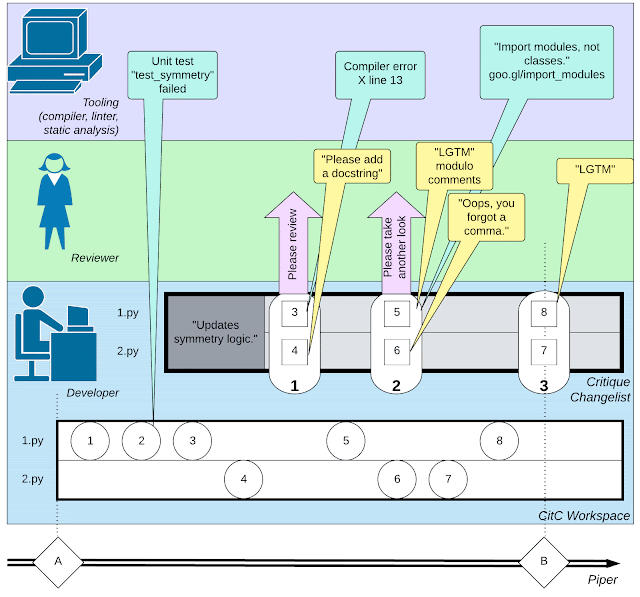 |
| ソフトウェア開発に関わる複雑な活動のウェブを描いたイラスト: 開発者による小さなアクション、コードレビュワーとのやりとり、コンパイラなどのツールの呼び出し。 |
ソフトウェアエンジニアリングのためのマルチタスクモデル
DIDACTは、エンジニアとツールの相互作用を利用して、Googleの開発者がソフトウェアエンジニアリングのタスクを追求しながら、文脈に沿って開発者が実行するアクションを提案または強化するMLモデルを駆動します。そのために、個々の開発者活動についていくつかのタスクを定義しています: 壊れたビルドの修復、コードレビューコメントの予測、コードレビューコメントの対処、変数の名前変更、ファイルの編集など。各活動に対して共通の形式を使用します: 状態(コードファイル)、意図(活動に特化した注釈、例えばコードレビューコメントやコンパイラエラー)、アクション(タスクに対処するために実行される操作)を必要とします。このアクションは、ミニプログラミング言語のようであり、新しく追加された活動に対して拡張することができます。編集、コメントの追加、変数の名前変更、エラーでコードをマークアップするなど、これらのことをカバーします。この言語をDevScriptと呼びます。
 |
| DIDACTモデルは、タスク、コードスニペット、およびそのタスクに関連する注釈を促し、編集やコメントなどの開発アクションを生成します。 |
この状態-意図-アクションの形式は、多くの異なるタスクを一般的な方法でキャプチャすることができます。さらに、DevScriptは、複雑なアクションを簡潔に表現できるため、アクションが実行された後の状態(元のコード)全体を出力する必要がないため、モデルをより効率的かつ解釈可能にします。例えば、名前の変更は、ファイル内の数十箇所に触れるかもしれませんが、モデルは1つの名前変更アクションを予測できます。
MLピアプログラマー
DIDACTは、個々のアシストタスクで良い仕事をします。例えば、下の例では、機能がほぼ完了した後に、DIDACTがコードのクリーンアップを行っています。コードレビュワーによる最終コメント(アニメーション中の”human”でマークされています)と共にコードを見て、それらのコメントに対処するための編集を予測します(差分としてレンダリング)。
 |
| 初期のコードスニペットと、コードレビュワーがそのスニペットに添付したコメントを与えられた場合、DIDACTの「事前送信クリーンアップタスク」は、それらのコメントに対処するためのテキストの挿入や削除などの編集を生成します。 |
DIDACTの多様な性質は、スケールに伴って現れる振る舞いを思い起こさせるいくつかの驚くべき機能を生み出します。そのような機能の1つは、プロンプトを介して有効になる履歴拡張です。開発者が最近何をしたかを知ることで、モデルは開発者が次に何をすべきかをより正確に予測できます。
 |
| 履歴拡張によるコード補完のアクションのイラスト。 |
この能力を例示する強力なタスクの1つは、履歴拡張によるコード補完です。下の図では、開発者が新しい関数パラメーターを追加し(1)、ドキュメントにカーソルを移動します(2)。開発者の編集履歴とカーソル位置に依存する条件付きで、モデルは(3)の行を補完し、新しいパラメーターのdocstringエントリを正しく予測します。
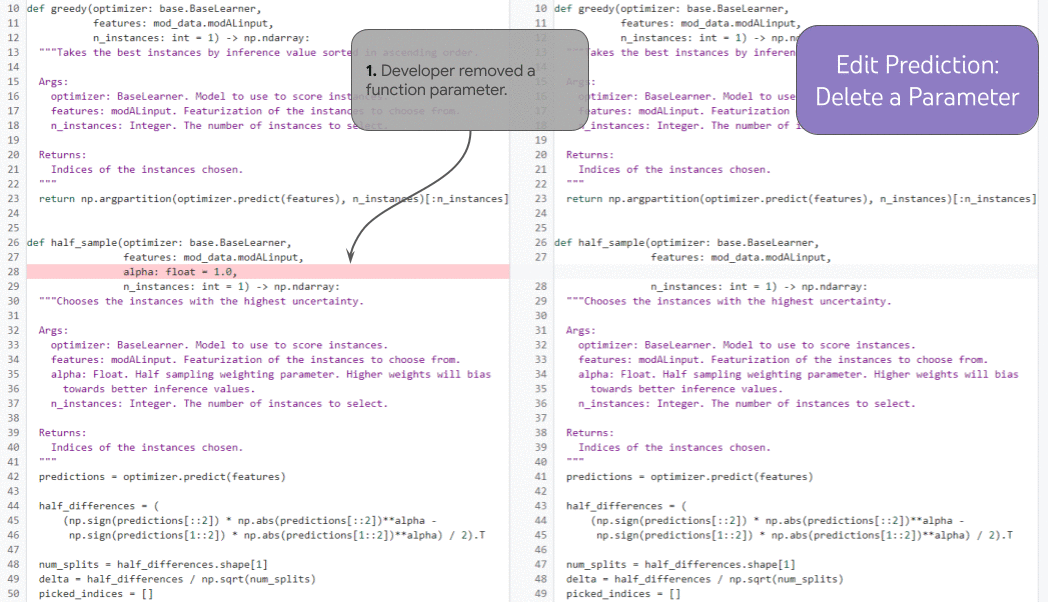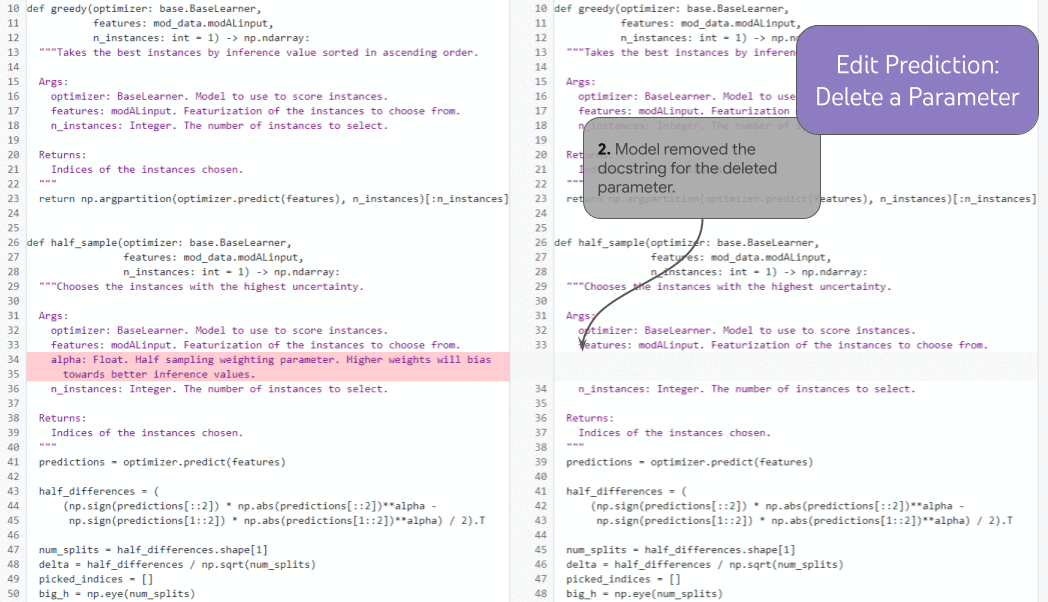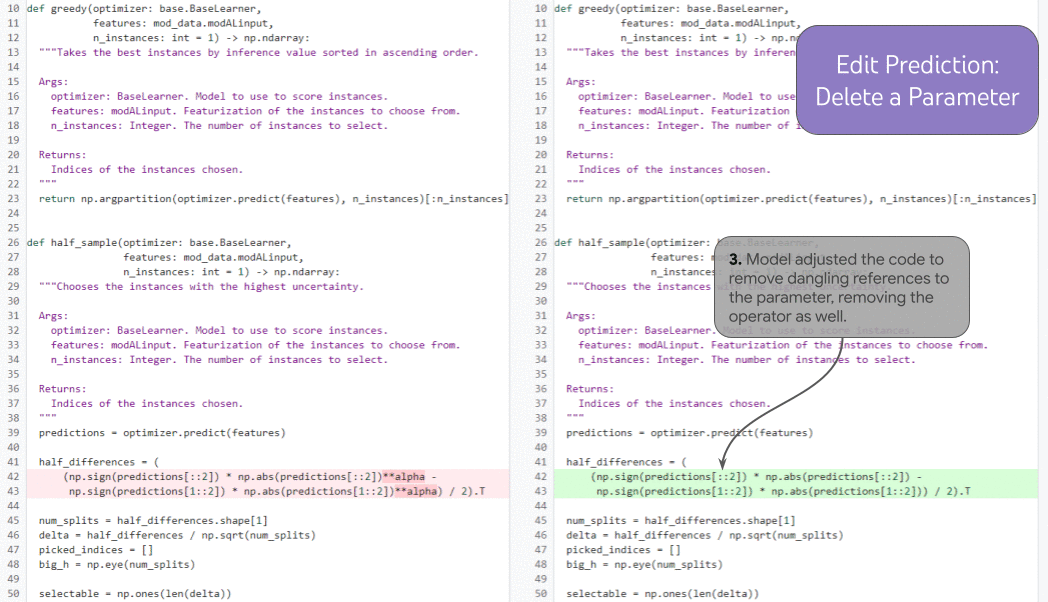 |
| 複数の連鎖的な編集にわたる編集予測のイラスト。 |
より強力な履歴拡張タスクである編集予測では、モデルは歴史的に一貫性のある方法で次にどこを編集するかを選択できます。開発者が関数パラメーターを削除する場合(1)、モデルは履歴を利用して削除されたパラメーターを除去するドックストリング(2)の更新を正確に予測し(人間の開発者が手動でカーソルをそこに置く必要はありません)、構文的に(および、議論の余地はあるかもしれませんが)意味的に正しい方法で関数内の文(3)を更新します。履歴を使用することで、モデルは「編集ビデオ」を正しく続ける方法を明確に決定できます。履歴がない場合、モデルは、欠落している関数パラメーターが意図的である(開発者がそれを削除するより長時間の編集プロセスにある場合)か、誤っているか(その場合、モデルは問題を修正するためにそれを再追加する必要があります)かを判断できません。
モデルはさらに進むことができます。たとえば、私たちは空のファイルから始め、モデルに次々にどのような編集が行われるかを予測して、完全なコードファイルを書き出すように頼みました。驚くべきことに、モデルは開発者に自然に見えるステップバイステップの方法でコードを開発しました。まず、インポート、フラグ、および基本的なメイン関数を含む完全に動作するスケルトンを作成し、次に、ファイルから読み取り、結果を書き出す新しい機能を段階的に追加し、ユーザー提供の正規表現に基づいていくつかの行をフィルタリングする機能を追加しました。これには、新しいフラグの追加など、ファイル全体にわたる変更が必要でした。
結論
DIDACTは、Googleのソフトウェア開発プロセスをMLデベロッパーアシスタントのトレーニングデモンストレーションに変え、それらのデモンストレーションを使用して、ツールとコードレビュアーとの対話的にステップバイステップでコードを構築するモデルをトレーニングすることで、Googleの開発者が毎日楽しんでいるツールを駆動しています。 DIDACTアプローチは、ソフトウェアエンジニアの労力を軽減し、生産性を向上させ、作業の品質を向上させる技術に向けられた、Googleや他の大規模な言語モデルが進んできた偉大な進歩を補完するものです。
謝辞
この作業は、Google Research、Google Core Systems and Experiences、およびDeepMindの複数年にわたる協力の結果です。このプロジェクトの主要なドライバーであるJacob Austin、Pascal Lamblin、Pierre-Antoine Manzagol、Daniel Zhengの同僚に感謝します。Alphabetのパートナー(Peter Choy、Henryk Michalewski、Subhodeep Moitra、Malgorzata Salawa、Vaibhav Tulsyan、Manushree Vijayvergiya)の重要で持続的な貢献、データの収集、タスクの特定、製品の構築、戦略策定、エバンジェリスト活動、そしてこのアジェンダの多くの側面の実行に役立った多くの人々(Ankur Agarwal、Paige Bailey、Marc Brockschmidt、Rodrigo Damazio Bovendorp、Satish Chandra、Savinee Dancs、Denis Davydenko、Matt Frazier、Alexander Frömmgen、Nimesh Ghelani、Chris Gorgolewski、Chenjie Gu、Vincent Hellendoorn、Franjo Ivančić、Marko Ivanković、Emily Johnston、Luka Kalinovcic、Lera Kharatyan、Jessica Ko、Markus Kusano、Kathy Nix、Christian Perez、Sara Qu、Marc Rasi、Marcus Revaj、Ballie Sandhu、Michael Sloan、Tom Small、Gabriela Surita、Maxim Tabachnyk、David Tattersall、Sara Toth、Kevin Villela、Sara Wiltberger、Donald Duo Zhao)と、私たちを非常にサポートしてくれたリーダーシップ(Martín Abadi、Joelle Barral、Jeff Dean、Madhura Dudhgaonkar、Douglas Eck、Zoubin Ghahramani、Hugo Larochelle、Chandu Thekkath、Niranjan Tulpule)に感謝します。ありがとうございました!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






