「Langchain x OpenAI x Streamlit — ラップソングジェネレーター🎙️」
Langchain x OpenAI x Streamlit - Rap Song Generator 🎙️
LangchainフレームワークをStreamlitとOpenAIのGPT3モデルと統合したWebアプリを作成する方法を学びましょう。

Streamlit 🔥
Streamlitは、機械学習とデータサイエンスのための美しいカスタムWebアプリを簡単に作成して共有できるオープンソースのPythonライブラリです。わずか数分で強力なデータアプリを構築してデプロイできます。
このライブラリを使用して、アプリの基本的なUIを作成し、その後、UIコンポーネントを接続してLangchainとOpenAIクライアントを使用してLLMの応答を提供します。🙌
Streamlitドキュメント
Langchain 🔗
Langchainは、言語モデルによって動作するアプリケーションを開発するためのフレームワークです。以下のようなアプリケーションを可能にします:
- データ意識:言語モデルを他のデータソースに接続する
- エージェント:言語モデルが環境と対話することを許可する
Langchainフレームワークを使用して、個々のプロンプト/タスクを使用してチェーンを構築します。LLMは、チェーン内の各リンクを順次処理し、これによりモデルを介してより複雑なクエリを実行できます。1つのプロンプトからの出力は、次のプロンプトの入力になります。
Langchainドキュメント
OpenAI | GPT3.5 🤖
LangchainのOpenAIクライアントを使用することで、最新のGPTモデルのパワーを利用できます。ここでは、’gpt-3.5-turbo’モデルを使用しますが、好きなモデルを使用することもできます。
以下は、OpenAIのウェブサイトから使用するモデルの簡単な説明です:
text-davinci-003の1/10のコストで最も能力のあるGPT-3.5モデル。最新のモデルのイテレーションがリリースされてから2週間後に更新されます。最大4,096トークン
詳細はこちらをご覧ください!
🧑💻コードを記述しましょう</>
まず、アプリについて —
私たちはラップソングジェネレーターを作成します。これは私たち自身のLLMパワードWebアプリケーションです。
与えられたトピックに基づいて適切な曲のタイトルを生成し、そのタイトルのための歌詞も生成します。以下はアプリのデモです:
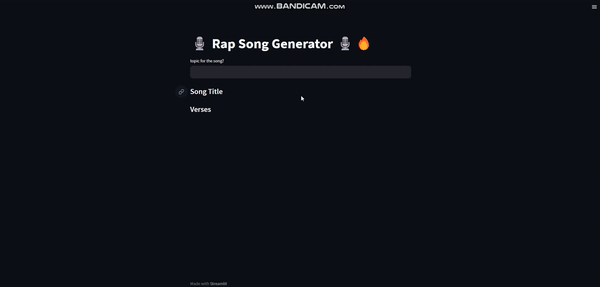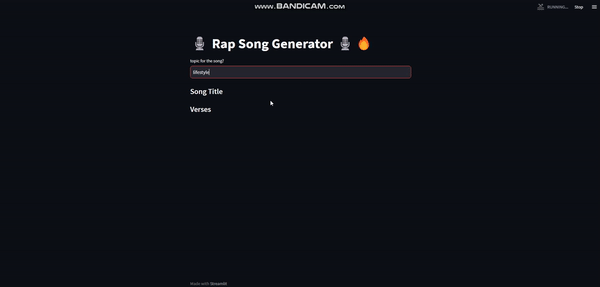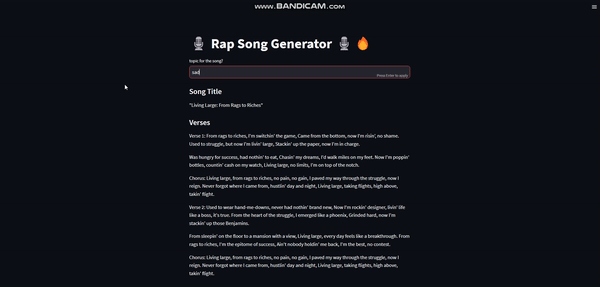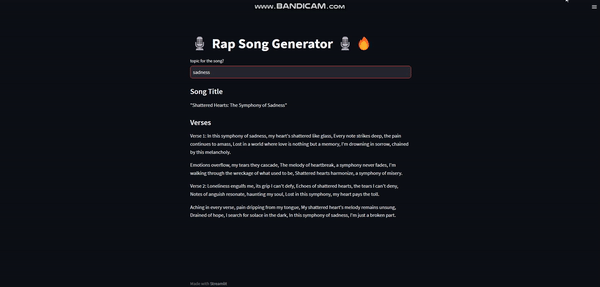
ワクワクしていますか?ビルドを開始しましょう!🧑🏻💻💪🏻
🙋🏻 インポートステートメントと初期設定 —
このプロジェクトには3つの主要なパッケージが必要です。必要な場合、それらをインストールします。
その後、APIキーをインポートして環境変数として設定します。また、アプリで使用する複数のGPTモデルがあるため、変数で使用するモデルを定義しました。必要に応じて変更できます。
#pip3 install streamlit#pip3 install langchain#pip3 install openaiimport osimport streamlit as stfrom langchain.prompts import PromptTemplatefrom langchain.chains import LLMChain, SimpleSequentialChain, SequentialChainfrom langchain.chat_models import ChatOpenAI#import API key from config filefrom config import OPEN_API # environment variable & the model to usemodel_id = 'gpt-3.5-turbo'os.environ["OPENAI_API_KEY"] = OPEN_API✒️ UI要素(streamlit)-
Streamlitは非常に使いやすいAPIを持っており、ML/データサイエンスアプリのフロントエンドを簡単に作成することができます。
以下のコードでは、まずアプリのためのタイトルを作成し、そのすぐ下にユーザーの入力ボックスがあります。ユーザーはここに曲のトピックを入力します。
その後、タイトルと歌詞のための2つの見出しを持っています。これらの見出しは、生成された後に出力が添付される個別の出力ボックスを持っています。
# メインのタイトルと入力ボックスst.title("🎙️ ラップソングジェネレーター 🎙️🔥") prompt = st.text_input("曲のトピックは?") # 2番目の見出しと曲のタイトルのための出力領域st.markdown("#### 曲のタイトル")title_box = st.empty()# 3番目の見出しと歌詞のための出力領域st.markdown("#### 歌詞")verse_box = st.empty()入力が提供されると、それは「prompt」という変数に保存されます。この変数は後で出力を生成するために使用されます。
💥 プロンプトテンプレート、チェーン、LLM(langchain、OpenAI)-
今度は、タイトルの生成と歌詞の生成のためのテンプレートを作成する必要があります。
- 最初のプロンプトでは、入力はUIからユーザーが入力した「トピック」です。この「トピック」を使用してテンプレート文字列をフォーマットします。このテンプレートは曲の「タイトル」を出力するために使用されます。
- 2番目のプロンプトでは、上記で生成された「タイトル」を入力として使用し、それをフォーマットするための2番目のテンプレート文字列を使用します。このテンプレート(チェーン)の出力は「歌詞」になります。
2つのテンプレートがあると、それぞれに2つのチェーンを作成します。最初のチェーンはタイトルチェーンであり、タイトルテンプレートを使用します。
同様に、2番目のチェーンは歌詞チェーンであり、歌詞テンプレートを使用します。
得られる出力は辞書形式になりますので、各チェーンについてキーとして使用するものを指定することができます。これは両方のチェーンに「output_key = something」と設定することで行うことができます。
# タイトル生成のためのプロンプトテンプレートtitle_template = PromptTemplate( input_variables = ["topic"], template = "トピック:{topic}についてのラップソングタイトルを生成する")# 歌詞生成のためのプロンプトテンプレートverse_template = PromptTemplate( input_variables = ["title"], template = "タイトル:{title}のラップソングに対して2つの韻を踏んだ歌詞を生成する")# チェーンの作成title_chain = LLMChain(llm=llm, prompt=title_template, verbose=True, output_key="title") verse_chain = LLMChain(llm=llm, prompt=verse_template, verbose=True, output_key="verse") # チェーンの結合sequential_chain = SequentialChain( chains=[title_chain, verse_chain], input_variables=["topic"], output_variables=["title", "verse"], verbose=True,) 最後に、両方のチェーンを結合し、実行を開始すると、それらは順次実行されます。この結合されたチェーンの入力変数は[“topic”]であり、出力変数は[“title”, “verse”]として結合する際に定義されます。
📺 画面出力-
ユーザーからの入力があると、先ほど作成した結合されたチェーンを実行します。プロンプトは「topic」として渡されます。なぜなら、それが私たちの「input_variables」パラメーターの名前として定義されているからです。
レスポンスは辞書形式であり、前もって定義した「output_variables」と「output_keys」変数を使用して必要なテキストを抽出することができます。
# プロンプトが提供された場合はチェーンを実行するif prompt: response = sequential_chain({ "topic" : prompt }) title = response["title"] body = response["verse"] # 各出力を独自の出力ボックスに表示 title_box.markdown(title) verse_box.markdown(body)アプリを実行するには、次のコマンドを使用してください-
streamlit run filename.pyこれで記事は以上です。お時間を割いていただけたことを願っています。今後のアップデートもお楽しみに!
🖤 読んでいただきありがとうございます。関連記事もぜひチェックしてください —
ジェネレーティブAIの早期採用:チャンスを受け入れリスクを緩和する
ジェネレーティブAIをビジネスに取り入れる企業の理由と、その欠点をもかかえながらどのように活用しているかを探ってみましょう…
krnk97.medium.com
YouTubeクローンの作成方法 — YouTube API
HTML、CSS、JavaScript(jQuery)とYouTube APIを使用してYouTubeビデオ検索Webアプリを開発する方法
enlear.academy
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
