Langchain、Weviate、およびStreamlitを使用してカスタムAIベースのチャットボットを構築する
Langchain, Weviate, and Streamlitを使用してカスタムAIベースのチャットボットを構築する
ジェネレーティブAI、人気のあるベクトルデータベース、プロンプトチェイニング、およびUIツールを使用してカスタマイズされたチャットボットを構築する包括的なガイド
複数の組織がカスタマイズされたLLMを構築するために競い合っている中で、私がよく聞かれる共通の質問は、このプロセスを効率化するためのツールはどれですか?
この記事では、ドキュメントの上に構築されたチャットボットを通じて会話を行うための完全に機能するアプリケーションの作成方法を紹介します。このアプリケーションでは、埋め込みとして保存されたドキュメントデータから情報を抽出するためにChatGPT/GPT-4(または他の大規模言語モデル)のパワーを活用し、プロンプトチェイニングにはLangchainを使用します。以下にプレビューを示します。
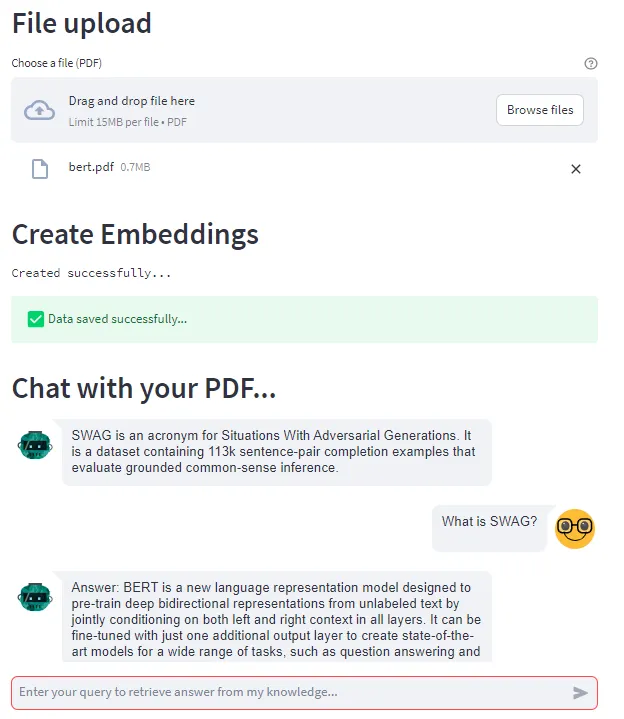
それでは、始めましょう!
アプリの構築🏗️
まず、アプリケーションのソースコードが存在する `app` という名前の新しいフォルダを作成します。これはstreamlitアプリケーションのエントリーポイントとして機能します。次に、PDFからテキストを抽出する、テキストの埋め込みを作成する、埋め込みを保存する、最後にチャットするといったさまざまなタスクを実行するフォルダを作成します。`app` ディレクトリの構造は以下のようになります:
PDFのアップロード
PDFをアップロードし、後続の処理のためにテキストを抽出します。
from PyPDF2 import PdfReaderimport streamlit as [email protected]_data()def extract_text(_file): """ :param file: 抽出するPDFファイル """ content = "" reader = PdfReader(_file) number_of_pages = len(reader.pages) # 複数ページからテキストをスクレイピング for i in range(number_of_pages): page = reader.pages[i] text = page.extract_text() content = content + text return contentコードリンク:
https://github.com/LLM-Projects/docs-qa-bot/blob/main/app/extract.py
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





