LangChain + Streamlit + Llama ローカルマシンに会話型AIをもたらす
LangChain + Streamlit + Llama 会話型AIのローカル実装

過去数ヶ月間、大規模言語モデル(LLM)は著しい注目を浴び、世界中の開発者の関心を集めています。これらのモデルは特に、チャットボット、パーソナルアシスタント、コンテンツ作成に取り組む開発者にとって、興味深い展望を生み出しています。LLMがもたらす可能性は、開発者 | AI | NLPコミュニティに熱狂的な波を巻き起こしました。
LLMとは何ですか?
- 「転移学習の非合理的な効果」
- 「教師付き機械学習と集合論を通じた現実世界の時系列異常検出」
- 「Tabnine」は、ベータ版のエンタープライズグレードのコード中心のチャットアプリケーション「Tabnine Chat」を導入しましたこれにより、開発者は自然言語を使用してTabnineのAIモデルと対話することができます
大規模言語モデル(LLM)とは、人間の言語に非常に近いテキストを生成し、自然な方法でプロンプトを理解できる機械学習モデルを指します。これらのモデルは、書籍、記事、ウェブサイトなどを含む広範なデータセットを使用してトレーニングされます。データ内の統計的なパターンを分析することで、LLMは与えられた入力に続く最も確率が高い単語やフレーズを予測します。
大規模言語モデル(LLM)を利用することで、ドメイン固有のデータを効果的に取り込んで問い合わせに対応することができます。これは、モデルが初期のトレーニング時にアクセスできなかった情報(企業の内部の文書や知識リポジトリなど)に対して特に有利です。
この目的に使用されるアーキテクチャは、Retrieval Augmentation Generation(検索補完生成)または一般的にはGenerative Question Answering(生成型質問応答)として知られています。
LangChainとは何ですか?
LangChainは、特に大規模な言語モデル(LLM)によって駆動されるアプリケーションの開発者を支援するために精巧に作り込まれた素晴らしいフレームワークです。LangChainは、LLMのパワーに基づいた優れたアプリケーションの作成を可能にするために、複数のモジュールからのコンポーネントをシームレスに連鎖することができます。
詳細情報:公式ドキュメント
動機?
この記事では、LLaMA 7bとLangchainを利用して、ゼロから独自のドキュメントアシスタントを作成するプロセスを紹介します。Langchainは、LLMとシームレスに統合するために特別に開発されたオープンソースのライブラリです。
以下は、プロセスの詳細な説明を提供する特定のセクションをアウトラインしたブログの構造の概要です:
仮想環境の設定とファイル構造の作成ローカルマシンにLLMを取得するLLMをLangChainに統合し、PromptTemplateをカスタマイズするドキュメントの検索と回答の生成Streamlitを使用してアプリケーションを構築する
セクション1:仮想環境の設定とファイル構造の作成
仮想環境の設定は、アプリケーションの実行に制御された独立した環境を提供し、その依存関係を他のシステム全体のパッケージから切り離します。このアプローチにより、依存関係の管理が簡素化され、異なる環境間での一貫性が保たれます。
このアプリケーションの仮想環境を設定するために、GitHubリポジトリでpipファイルを提供します。まず、図に示すような必要なファイル構造を作成しましょう。または、必要なファイルを取得するためにリポジトリをクローンすることもできます。
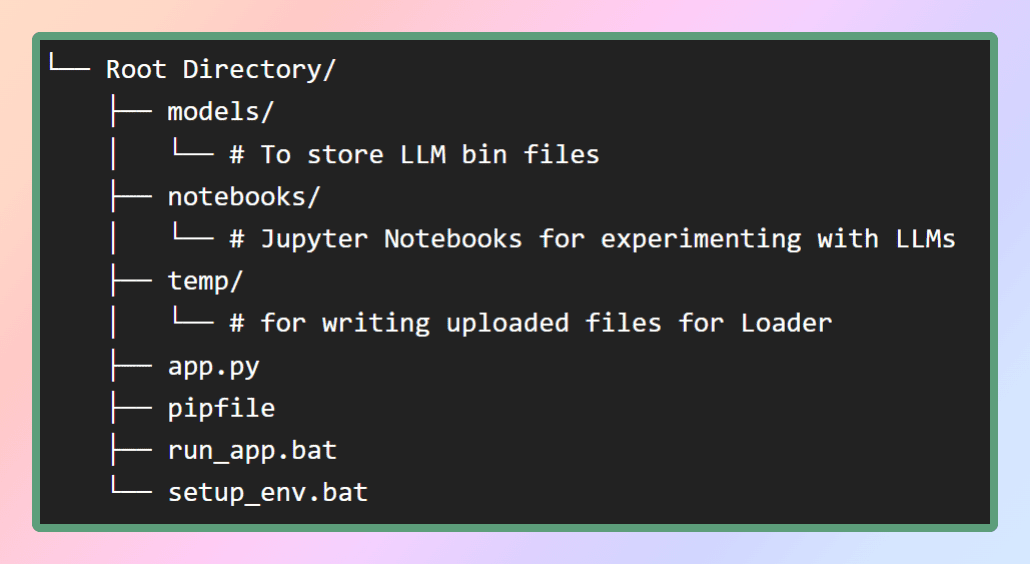
modelsフォルダの中には、ダウンロードするLLMを保存します。pipファイルはルートディレクトリに配置されます。
仮想環境を作成し、それに必要なすべての依存関係をインストールするために、同じディレクトリからpipenv installコマンドを使用するか、単純にsetup_env.batバッチファイルを実行します。これにより、必要なパッケージとライブラリが仮想環境に正常にインストールされます。依存関係が正常にインストールされたら、次のステップに進むことができます。次のステップでは、必要なモデルをダウンロードすることが含まれます。リポジトリはこちらです。
セクション2:ローカルマシンにLLaMAを取得する
LLaMAとは何ですか?
LLaMAは、Facebookの親会社であるMeta AIによって設計された新しい大規模言語モデルです。7兆〜65兆のパラメータを持つ多様なモデルのコレクションを備えたLLaMAは、最も包括的な言語モデルの一つとして際立っています。2023年2月24日、MetaはLLaMAモデルを一般に公開し、オープンサイエンスへの取り組みを示しました。
LLaMAの優れた機能を考慮し、私たちはこの強力な言語モデルを利用することにしました。具体的には、最小のバージョンであるLLaMA 7Bを使用します。この縮小サイズでも、LLaMA 7Bは重要な言語処理能力を提供し、効率的かつ効果的に目標を達成することができます。
公式の研究論文:
LLaMA:オープンで効率的な基礎言語モデル
ローカルCPUでLLMを実行するには、GGML形式のローカルモデルが必要です。いくつかの方法でこれを達成することができますが、最も簡単なアプローチはHugging Face Modelsリポジトリからbinファイルを直接ダウンロードすることです。私たちの場合、Llama 7Bモデルをダウンロードします。これらのモデルはオープンソースであり、無料でダウンロードすることができます。
時間と労力を節約したい場合は心配しないでください。ダウンロード用の直接リンクをこちらに用意しました ?. 任意のバージョンをダウンロードして、ファイルをルートディレクトリ内のmodelsディレクトリに移動させてください。このようにすることで、モデルを便利に利用することができます。
GGMLとは何ですか?なぜGGMLを使用するのですか?どのようにGGMLを使用するのですか?LLaMA CPP
GGMLは、機械学習のためのテンソルライブラリであり、CPUまたはCPU + GPUでLLMを実行するためのC++ライブラリです。GGMLは大規模言語モデル(LLM)の配布のためのバイナリ形式を定義しています。GGMLは量子化と呼ばれる技術を利用しており、消費者向けのハードウェアで大規模言語モデルを実行することができます。
では、量子化とは何ですか?
LLMの重みは浮動小数点(小数)の数値です。大きな整数(例:1000)を表すためには小さな整数(例:1)よりもスペースが必要であるように、高精度の浮動小数点数値(例:0.0001)を表すためには低精度の浮動小数点数値(例:0.1)よりもスペースが必要です。大規模言語モデルの量子化プロセスでは、モデルの重みの表現精度を低下させ、モデルの使用に必要なリソースを削減します。GGMLは、効率とパフォーマンスの間で異なるトレードオフを提供する複数の異なる量子化戦略(例:4ビット、5ビット、8ビットの量子化)をサポートしています。
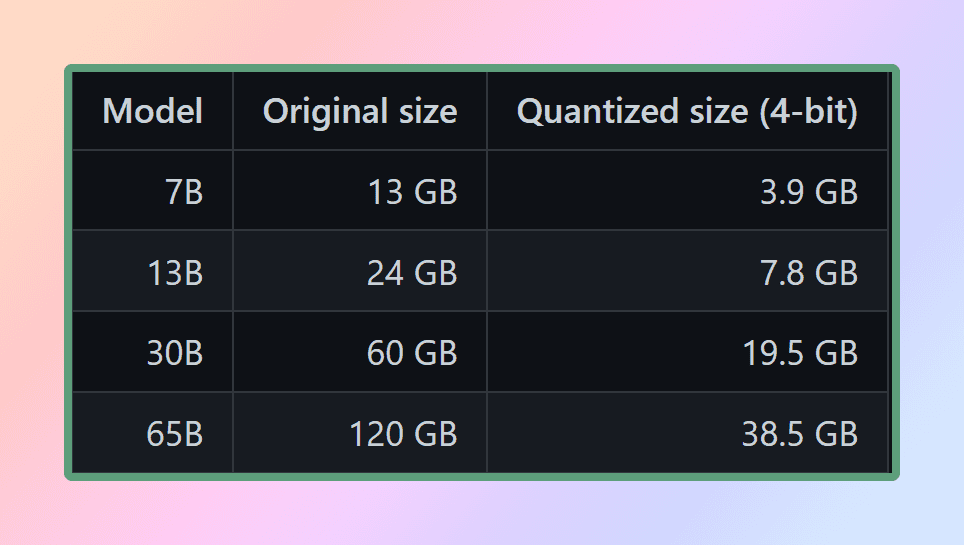
モデルを効果的に使用するためには、メモリとディスクの要件を考慮することが重要です。モデルは現在、完全にメモリにロードされているため、それらを保存するために十分なディスク容量と、実行時にそれらをロードするために十分なRAMが必要です。65Bモデルの場合、量子化後でも少なくとも40ギガバイトの利用可能なRAMが推奨されています。メモリとディスクの要件は現在同等です。
量子化はこれらのリソース要求を管理する上で重要な役割を果たします。優れた計算リソースにアクセスできない限り
モデルのパラメータの精度を低下させ、メモリの使用を最適化することにより、量子化はより控えめなハードウェア構成でもモデルを利用できるようにします。これにより、さまざまなセットアップに対して、モデルの実行が実現可能かつ効率的になります。
C++ ライブラリの場合、Python でどのように使用するのですか?
それが Python バインディングが登場する場所です。バインディングとは、2つの言語間のブリッジまたはインターフェースを作成するプロセスを指します。ここでは、Python と C++ の間のブリッジを作成します。Python では、llama-cpp-python を使用します。これは、llama.cpp の Python バインディングであり、純粋な C/C++ で LLaMA モデルのインファレンスを行います。llama.cpp の主な目標は、4ビット整数量子化を使用して LLaMA モデルを実行することです。この統合により、C/C++ の実装の利点と4ビット整数量子化の利点を効果的に活用できます。

GGML モデルが準備され、すべての依存関係が整っている(pipfile のおかげで)、LangChain との旅に出る準備が整いました。しかし、LangChain のエキサイティングな世界に飛び込む前に、お決まりの「Hello World」の儀式でスタートしましょう。新しい言語やフレームワークを探求するときには、いつもこの伝統を守ります。LLM も言語モデルですから。
 Image By Author: CPU 上で LLM とのインタラクション
Image By Author: CPU 上で LLM とのインタラクション
ボワラ!CPU 上で完全にオフラインかつ完全にランダムな方法で最初の LLM を正常に実行しました(ハイパーパラメータ temperature を調整できます)。
このエキサイティングなマイルストーンを達成したことで、LangChain の主な目標に向かって進む準備が整いました。LangChain フレームワークを使用して、カスタムテキストの質問応答を行います。
セクション 3: LLM — LangChain 統合の始め方
前のセクションでは、llama cpp を使用して LLM を初期化しました。では、LangChain フレームワークを活用して LLM を使用したアプリケーションを開発しましょう。LLM とのインタラクションは主にテキストを通じて行うことができます。単純化された説明として、多くのモデルは「テキストイン、テキストアウト」です。そのため、LangChain のインターフェースの多くはテキストを中心にしています。
プロンプトエンジニアリングの台頭
プログラミングの常に進化し続ける分野で、魅力的なパラダイムが生まれました。それが「プロンプト」です。プロンプトは、特定の入力を言語モデルに提供して所望の応答を引き出すことを意味します。この革新的なアプローチにより、私たちは提供する入力に基づいてモデルの出力を形成することができます。
私たちがプロンプトの表現方法に微妙なニュアンスを持たせると、モデルの応答の性質と内容に大きな影響を与えることが驚くべきことです。結果は、フレーズの言い回しに基づいて根本的に異なる場合があり、プロンプトの作成時に慎重な考慮が重要であることを強調します。
LLM とシームレスにインタラクションするために、LangChain はいくつかのクラスと関数を提供しており、プロンプトテンプレートを使用してプロンプトの構築と操作を簡単に行うことができます。プロンプトテンプレートは、プロンプトを生成するためにエンドユーザーからパラメータセットを受け取るテキスト文字列です。いくつかの例を見てみましょう。
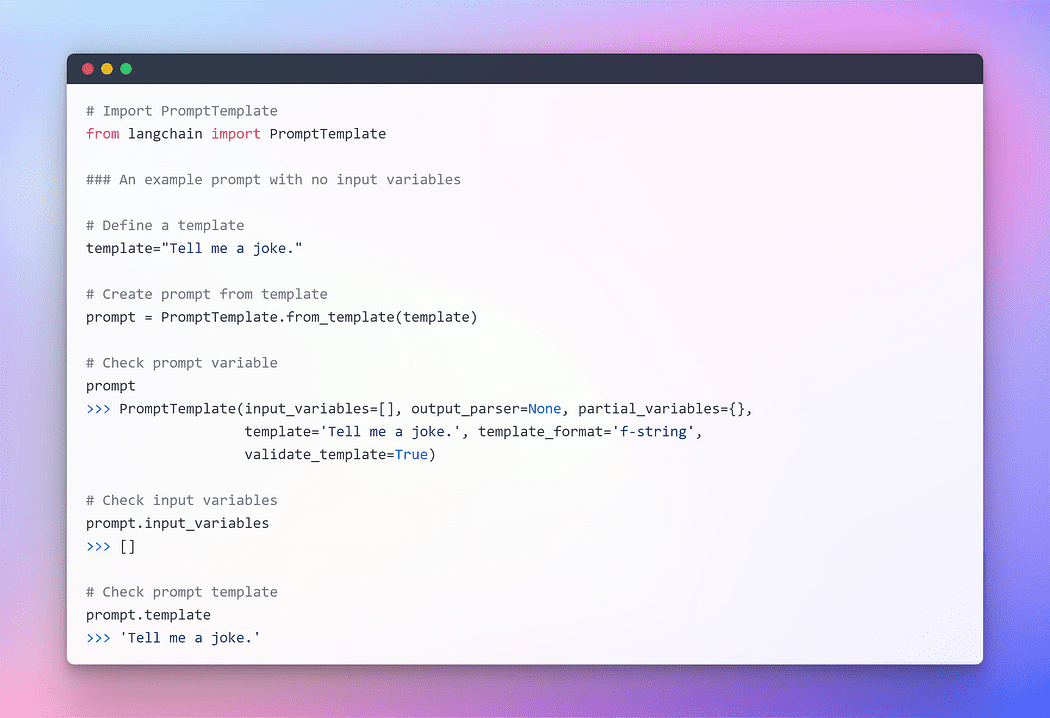 Image By Author: 入力変数なしのプロンプト
Image By Author: 入力変数なしのプロンプト
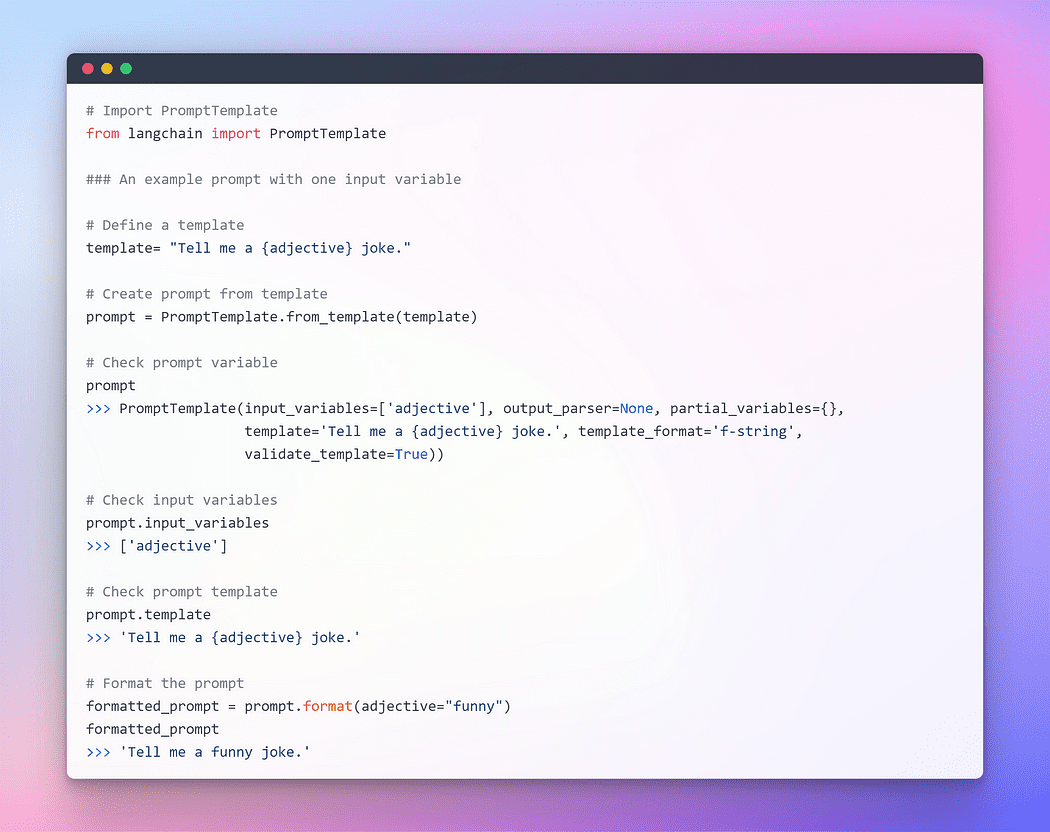 Image By Author: 入力変数が1つあるプロンプト
Image By Author: 入力変数が1つあるプロンプト
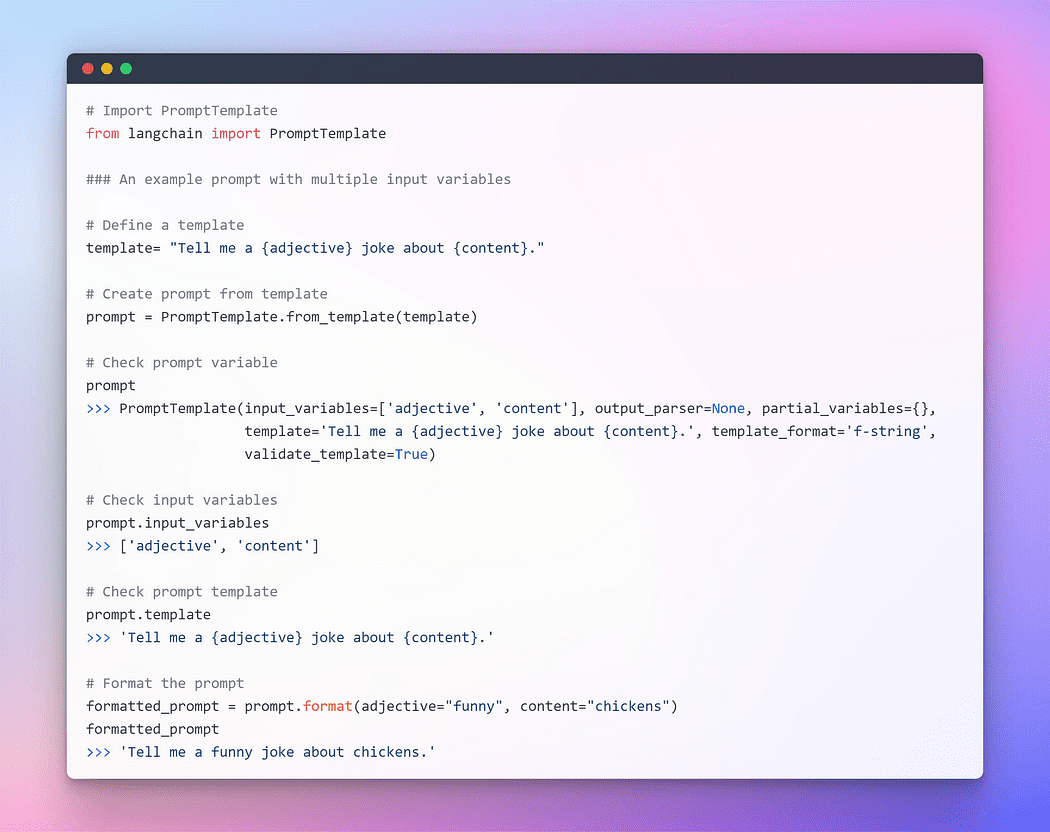 Image By Author: 複数の入力変数を持つプロンプト
Image By Author: 複数の入力変数を持つプロンプト
前の説明がプロンプトの概念をより明確に理解できたことを願っています。さあ、LLM にプロンプトを与えましょう。
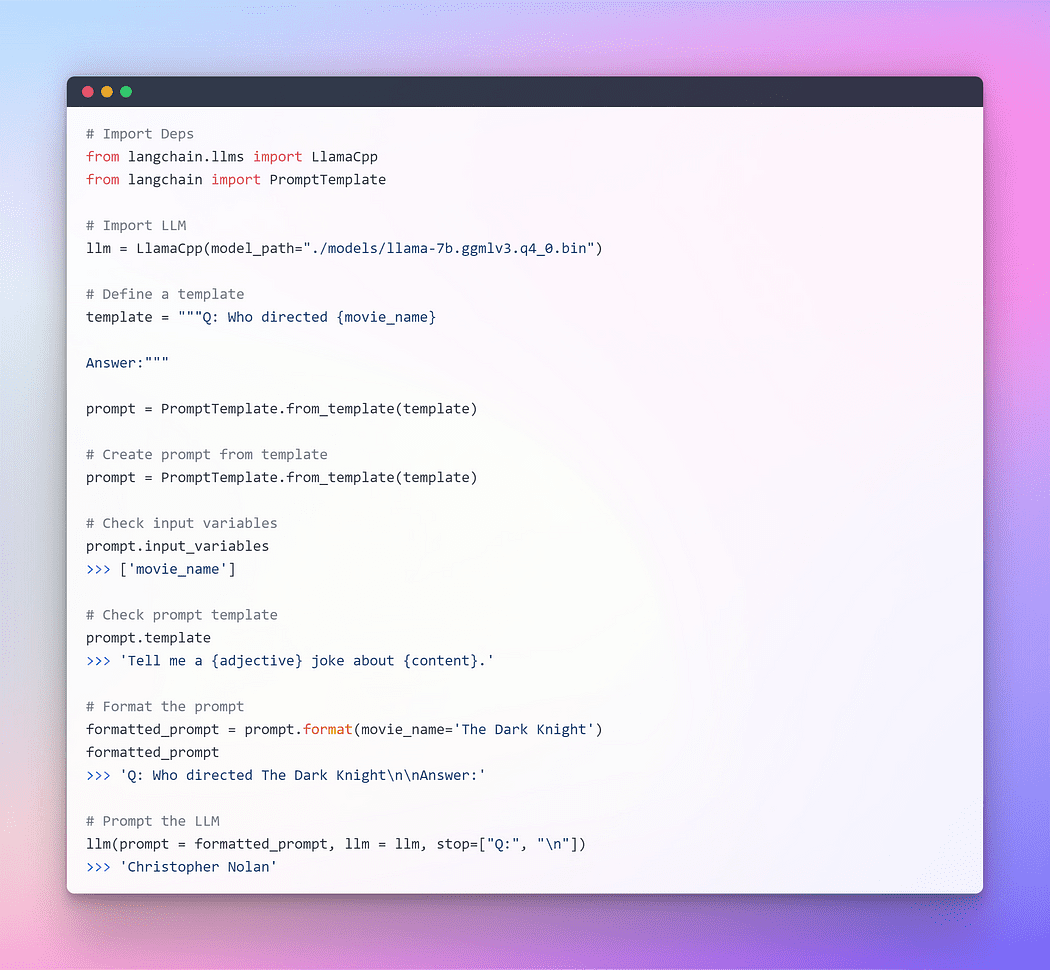 作者: Langchain LLM を通じたプロンプト提示
作者: Langchain LLM を通じたプロンプト提示
これは完璧に機能しましたが、これはLangChainの最適な活用ではありません。これまで個々のコンポーネントを使用してきました。プロンプトテンプレートを取得し、それをフォーマットし、LLMを取得し、そのパラメータをLLM内に渡して回答を生成しました。単独でLLMを使用することは、シンプルなアプリケーションには適していますが、より複雑なアプリケーションではLLMを連鎖させる必要があります。これは他のLLMと組み合わせるか、他のコンポーネントと組み合わせることができます。
LangChainでは、このような連鎖されたアプリケーションのためにChainインターフェースを提供しています。Chainを非常に一般的に、コンポーネントへの呼び出しのシーケンスとして定義します。コンポーネントには他のChainを含めることができます。Chainを使用すると、複数のコンポーネントを組み合わせて単一の一貫したアプリケーションを作成することができます。たとえば、ユーザーの入力を受け取り、プロンプトテンプレートでフォーマットし、フォーマットされた応答をLLMに渡すChainを作成することができます。複数のChainを組み合わせるか、Chainを他のコンポーネントと組み合わせることで、より複雑なChainを構築することができます。
具体例を理解するために、すでに作成された個々のコンポーネントを使用して、ユーザーの入力を受け取り、それをプロンプトでフォーマットし、それをLLMに送信する非常にシンプルなChainを作成しましょう。
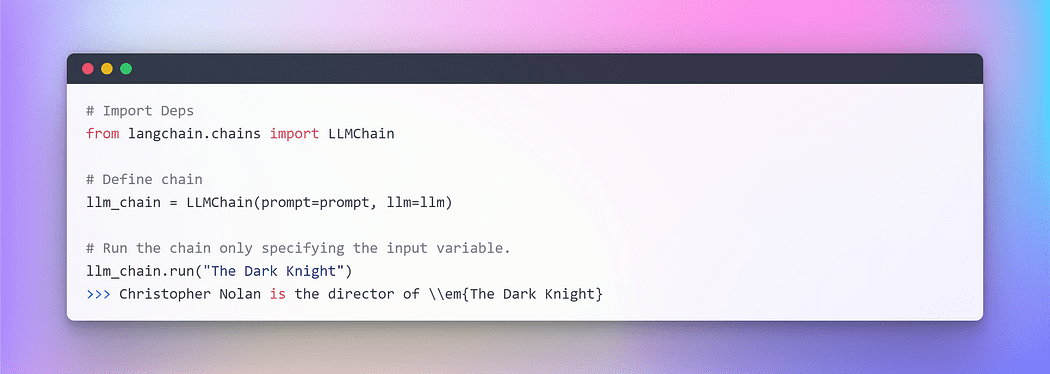 作者: LangChainにおけるチェーンの活用
作者: LangChainにおけるチェーンの活用
複数の変数を扱う場合、辞書を利用してそれらをまとめて入力することができます。このセクションは以上です。そして、次に、外部テキストを質問応答のためのリトリーバとして組み込むメインパートに入りましょう。
セクション4: 質問応答のための埋め込みとベクトルストアの生成
多くのLLMアプリケーションでは、モデルのトレーニングセットに含まれていないユーザー固有のデータが必要です。LangChainは、データをロード、変換、保存、クエリするための必須コンポーネントを提供します。
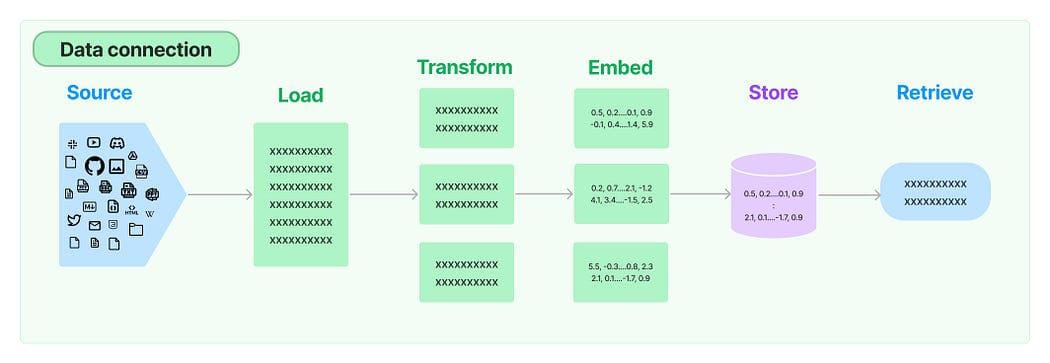 LangChainにおけるデータ接続: ソース
LangChainにおけるデータ接続: ソース
以下の5つのステージがあります:
- ドキュメントローダ: データをドキュメントとしてロードするために使用されます。
- ドキュメントトランスフォーマ: ドキュメントをより小さなチャンクに分割します。
- 埋め込み: チャンクをベクトル表現、つまり埋め込みに変換します。
- ベクトルストア: 上記のチャンクベクトルをベクトルデータベースに保存するために使用されます。
- リトリーバ: クエリに最も類似したセット/セットのベクトルを、同じ潜在空間に埋め込まれたベクトルの形で取得するために使用されます。
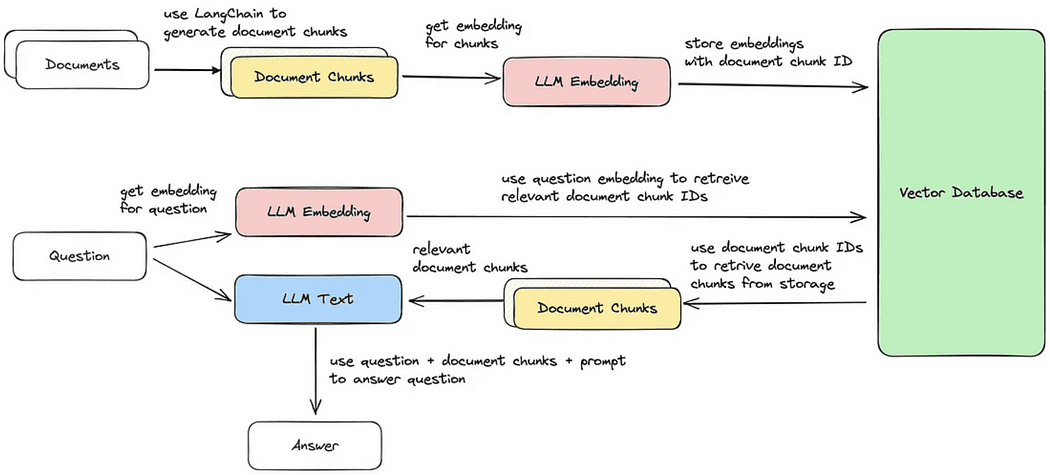 ドキュメント検索/質問応答のサイクル
ドキュメント検索/質問応答のサイクル
では、次に、上記のクエリに最も類似したドキュメントのチャンクを検索し、それに基づいて回答を生成するための5つのステップを順番に説明します。提供されたイメージのように、検索されたベクトルチャンクに基づいて回答を生成することができます。
ただし、さらに進む前に、上記のタスクを実行するためにテキストを準備する必要があります。この架空のテストのために、いくつかの人気のあるDCスーパーヒーローに関するWikipediaからテキストをコピーしました。以下にテキストを示します:
 作者: テスト用の生のテキスト
作者: テスト用の生のテキスト
ドキュメントのロードと変換
まず、ドキュメントオブジェクトを作成しましょう。この例では、テキストローダーを使用します。ただし、LangChainでは複数のドキュメントに対応しているため、特定のドキュメントに応じて異なるローダーを使用することができます。次に、事前に設定されたソースからデータを取得し、ドキュメントとしてロードするためにloadメソッドを使用します。
ドキュメントが読み込まれると、それを小さなチャンクに分割することで変換プロセスを進めることができます。これを実現するために、TextSplitterを利用します。デフォルトでは、スプリッタは「\n\n」のセパレータでドキュメントを分割します。しかし、セパレータをnullに設定し、特定のチャンクサイズを定義すると、各チャンクはその指定された長さになります。結果として得られるリストの長さは、ドキュメントの長さをチャンクサイズで割った値になります。要するに、次のようになります:list length = length of doc / chunk size。言葉だけではなく、実際にやってみましょう。
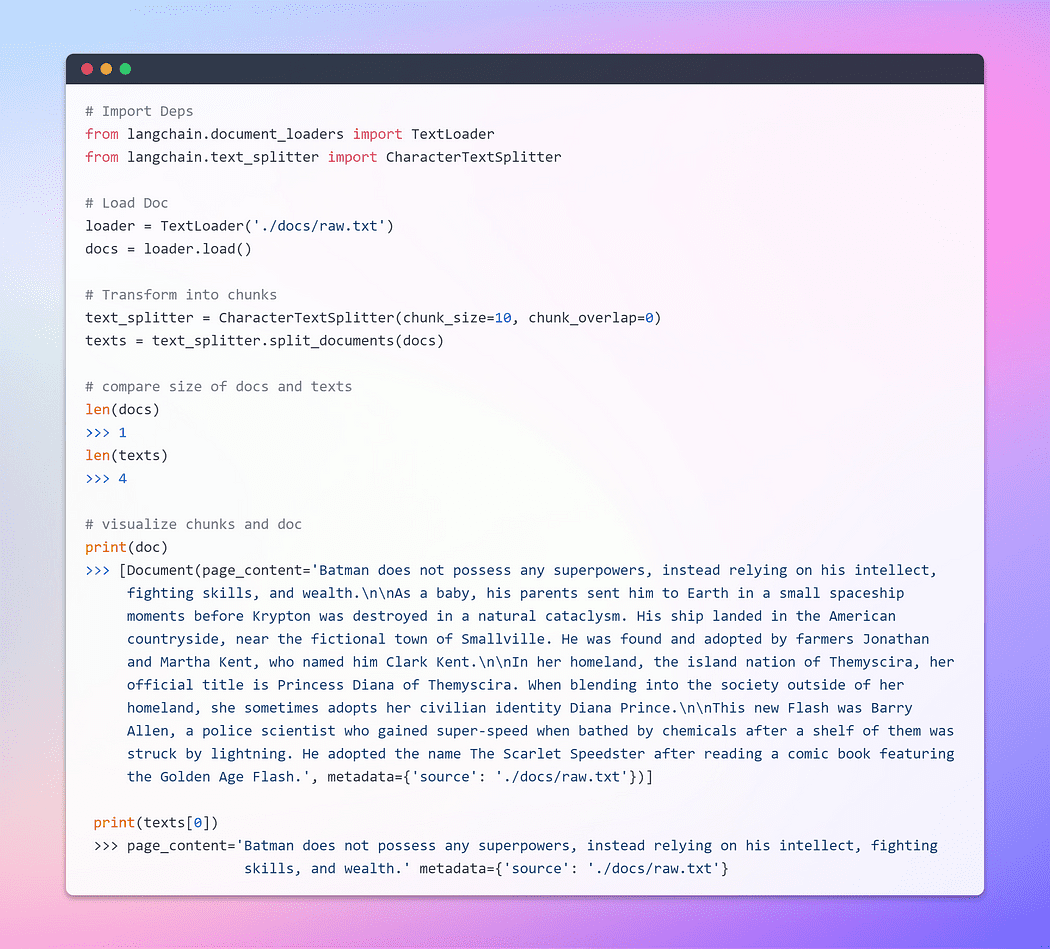 画像提供: ドキュメントの読み込みと変換
画像提供: ドキュメントの読み込みと変換
旅の一部は埋め込みです!!!
これが最も重要なステップです。埋め込みはテキストコンテンツのベクトル化された表現を生成します。これは実用的な意味を持ちます。なぜなら、テキストをベクトル空間内で概念化することができるからです。
単語埋め込みは、単語のベクトル表現であり、ベクトルには実数が含まれます。通常、言語には少なくとも何万もの単語が含まれるため、単純なバイナリ単語ベクトルは次元数が非常に高くなるため実用的ではありません。単語埋め込みは、低次元のベクトル空間で単語の密な表現を提供することで、この問題を解決します。
検索について話すとき、埋め込まれたベクトルと似ているベクトルのセットをクエリとして取得することを指します。これらのベクトルは同じ潜在空間に埋め込まれています。
LangChainのベースとなるEmbeddingsクラスには、ドキュメントを埋め込むためのメソッドとクエリを埋め込むためのメソッドの2つが公開されています。前者は複数のテキストを入力として受け取り、後者は単一のテキストを入力として受け取ります。
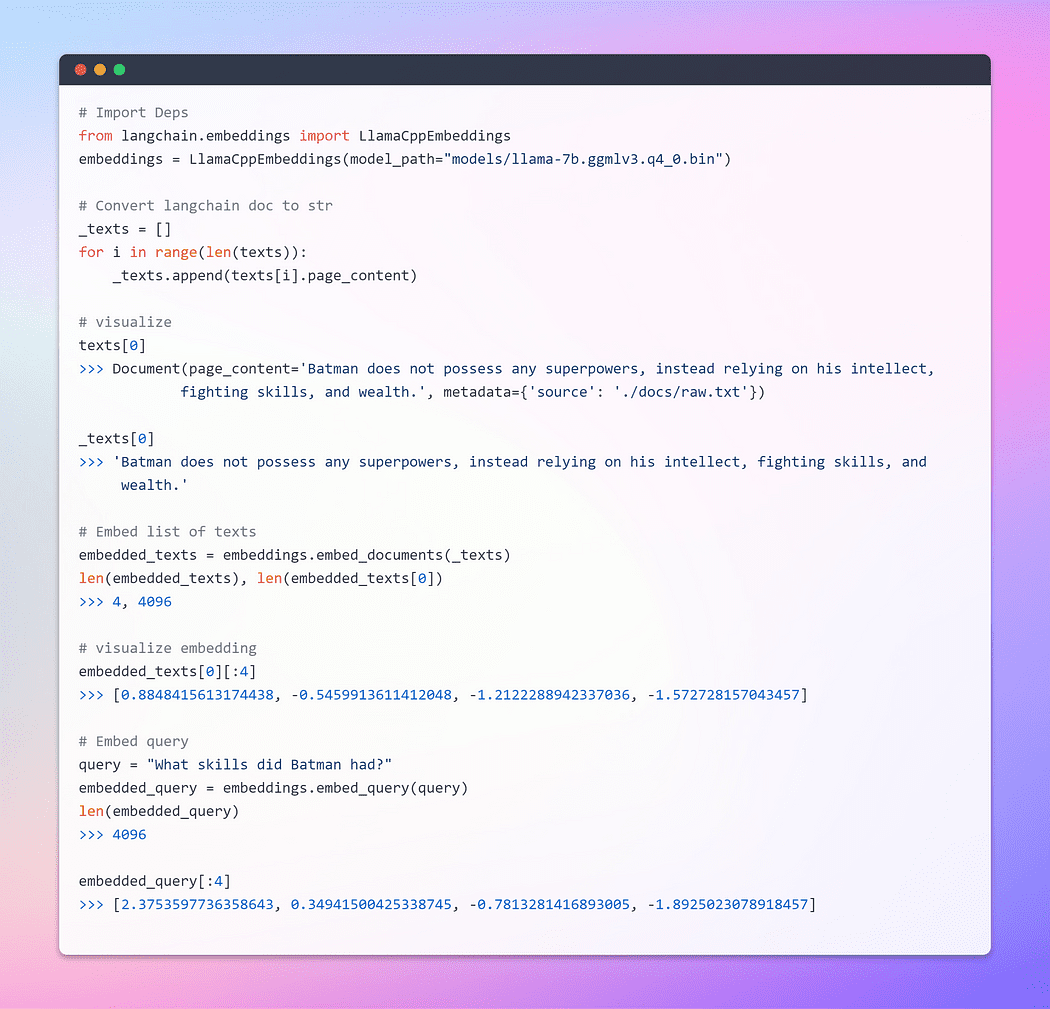 画像提供: 埋め込み
画像提供: 埋め込み
埋め込みについて包括的に理解するためには、ニューラルネットワークがテキストデータをどのように扱うかの核となる基礎を深く掘り下げることを強くお勧めします。TensorFlowを利用した私のブログでこのトピックを詳しく説明しています。以下はリンクです。
単語埋め込み – ニューラルネットワークのテキスト表現
ベクトルストアの作成とドキュメントの取得
ベクトルストアは埋め込みデータの効率的な管理と、ベクトル検索操作をあなたの代わりに容易に行うことができます。埋め込みと結果の埋め込みベクトルの保存は、構造化されていないデータの保存と検索の一般的な方法です。クエリ時には、構造化されていないクエリも埋め込まれ、埋め込まれたクエリに最も類似している埋め込みベクトルが取得されます。このアプローチにより、ベクトルストアから関連情報を効果的に取得することができます。
ここでは、埋め込みデータベースであるChromaを利用します。Chromaは埋め込みを組み込んだAIアプリケーションの開発を簡素化するために特別に作られたベクトルストアです。初期セットアップを容易にするために、包括的な組み込みツールと機能のスイートを提供しており、簡単なpip install chromadbコマンドを実行するだけでローカルマシンに簡単にインストールできます。
 画像提供: ベクトルストアの作成
画像提供: ベクトルストアの作成
これまで、埋め込みとベクトルストアの優れた能力を見てきました。これらは広範なドキュメントコレクションから関連するチャンクを取得するための重要な手法です。そして、この取得したチャンクをコンテキストとしてクエリと一緒にLLMに提示する時が来ました。その魔法の杖で、私たちが提供した情報に基づいて答えを生成するようLLMに請願しましょう。重要なのは、適切な構造を持つプロンプトです。
ただし、適切に作成されたプロンプトの重要性を強調することが重要です。適切に作成されたプロンプトを作成することで、LLMが不確実性に直面したときに事実を創作する可能性を軽減することができます。
もう待つことなく、最終フェーズに進み、私たちのLLMが魅力的な回答を生成できるかどうかを確認しましょう。私たちの努力の結実を目の当たりにする時が来ました。さあ、行きましょう!
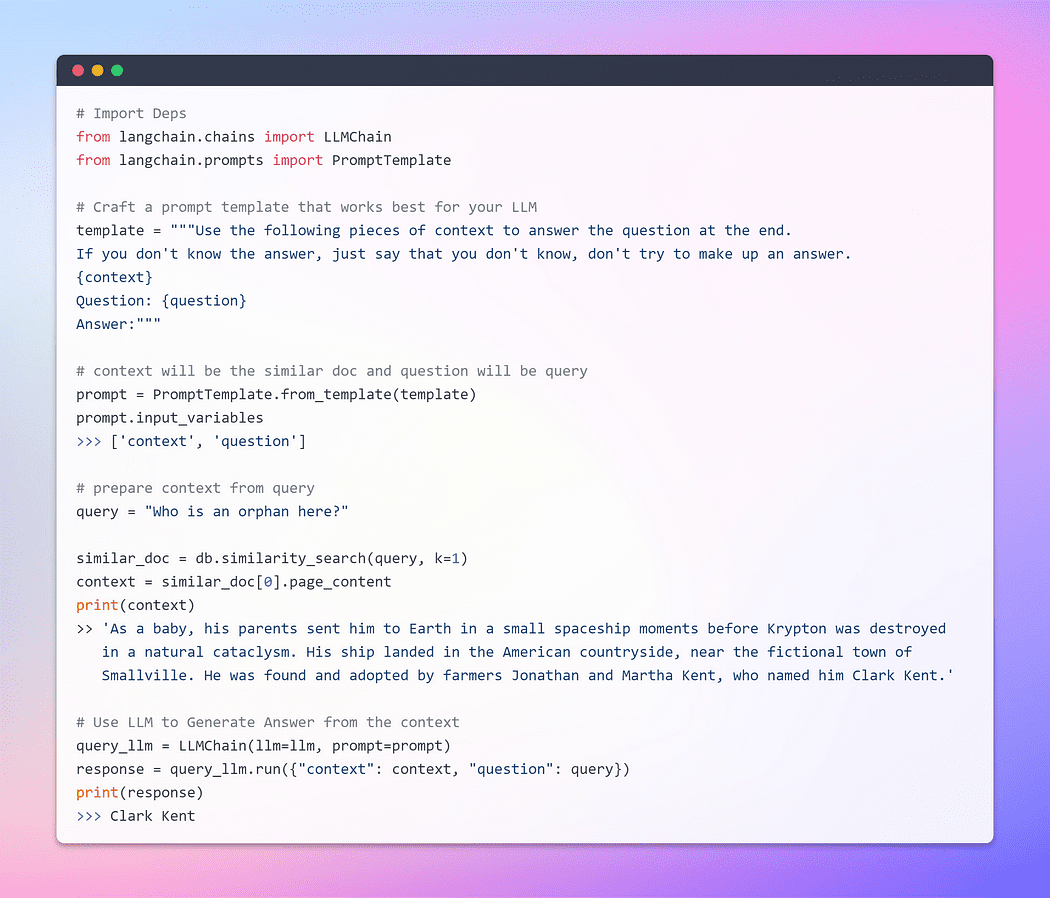 画像提供: ドキュメントとのQ/A
画像提供: ドキュメントとのQ/A
これは私たちが待ち望んでいた瞬間です!私たちはそれを成し遂げました!私たちはちょうど、LLMを使用してローカルで動作する質問応答ボットを作りました。
セクション5:Streamlitを使用してすべてを連結する
このセクションは完全にオプションです。Streamlitの包括的なガイドとしては機能しません。この部分には深く立ち入りません。代わりに、ユーザーが任意のテキストドキュメントをアップロードできる基本的なアプリケーションを紹介します。その後、テキスト入力を通じて質問をするオプションがあります。裏側では、機能は前のセクションでカバーした内容と一貫しています。
ただし、Streamlitでのファイルのアップロードには注意点があります。特にLLMのメモリ集中型の性質を考慮して、潜在的なメモリ不足エラーを防ぐために、ドキュメントを単純に読み取り、ファイル構造内の一時フォルダに書き込み、raw.txtという名前を付けます。これにより、ドキュメントの元の名前に関係なく、Textloaderが将来的にシームレスに処理できるようになります。
現在、このアプリはテキストファイル用に設計されていますが、PDF、CSV、または他の形式に適応させることもできます。基本的なコンセプトは同じです。なぜなら、LLMは主にテキストの入力と出力に設計されているからです。また、Llama C++バインディングでサポートされているさまざまなLLMを試すこともできます。
複雑な詳細に立ち入ることなく、アプリのコードを紹介します。特定のユースケースに合わせてカスタマイズしてください。
以下は、streamlitアプリの見た目です。
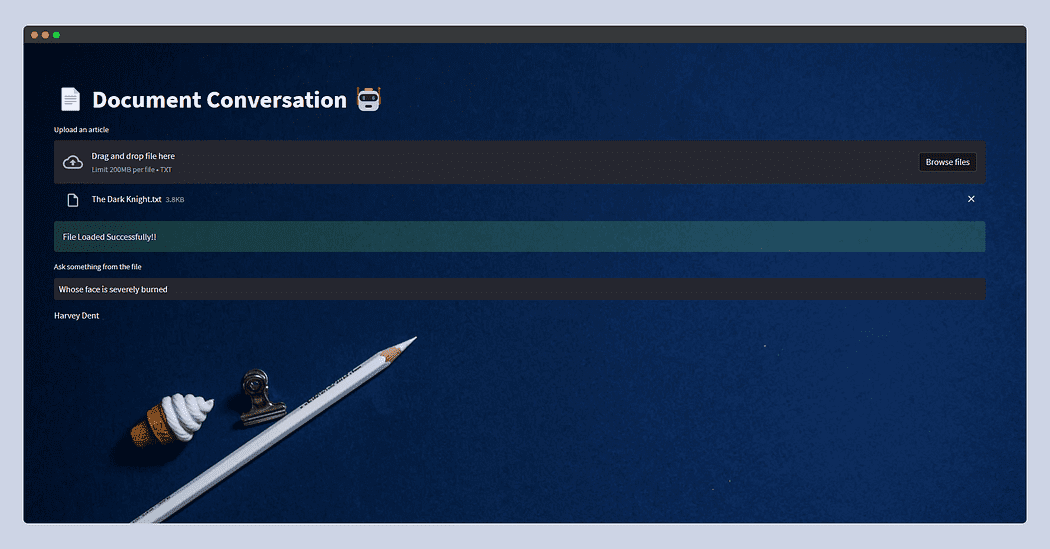
今回は、WikiからコピーしたThe Dark Knightのプロットを与え、単にWhose face is severely burnt?と尋ねたところ、LLMはHarvey Dentと答えました。
さて、さて、さて!それでは、このブログの終わりになります。
この記事がお楽しみいただけたら幸いです!情報を得ることができ、魅力的であると感じました。さらに多くの記事を読むために、私をフォローしてください。Afaque Umer
私はより多くの機械学習/データサイエンスの概念を取り上げ、難しそうな用語や概念をより簡単なものに分解しようとします。
Afaque Umerは情熱的な機械学習エンジニアです。最新のテクノロジーを使用して効率的なソリューションを見つけるために新しいチャレンジに取り組むことが大好きです。一緒にAIの限界を押し広げましょう!
オリジナル。許可を得て再投稿されました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 効率化の解除:Amazon SageMaker Pipelinesでの選択的な実行の活用
- 「AIプロジェクトはどのように異なるのか」
- 「Embroid」を紹介します:複数の小さなモデルから埋め込み情報を組み合わせるAIメソッドで、監視なしでLLMの予測を自動的に修正することができます
- 「ONNXフレームワークによるモデルの相互運用性と効率の向上」
- トムソン・ロイターが6週間以内に開発したエンタープライズグレードの大規模言語モデルプレイグラウンド、Open Arena
- Amazon SageMakerを使用して、オーバーヘッドイメージで自己教師ありビジョン変換モデルをトレーニングする
- MLOpsとは何ですか






