LangChain 101 パート1. シンプルなQ&Aアプリの構築
LangChain 101 パート1. シンプルなQ&Aアプリの構築
紹介
LangChainは、テキスト生成、質問に答える、言語を翻訳するなど、さまざまなテキスト関連の処理を行うアプリケーションを作成するための強力なフレームワークです。私はLangChainと一緒に今年の始めから取り組んでおり、その能力に非常に感銘を受けています。
この記事は私のLangChain 101コースのスタートです。概念、実践、経験を共有しながら、自分自身のLangChainアプリケーションを構築する方法を紹介します。
今日は以下のトピックについて議論します:
- LangChainとは何か
- LangChainの基本的な概念とコンポーネント
- 基本的なLangChainアプリケーションの構築方法
LangChainとは何ですか
Langは言語を意味し、LangChainの主な焦点です。そして、chainは接続することを意味し、LangChainで使用されるチェーンコンポーネントを指します。チェーンは、タスクを実行するためにフレームワークが実行する命令のシーケンスです。これにより、特定のタスクにおいて大規模言語モデル(LLM)の使用を簡素化し、LLMの力を他のプログラミング技術と組み合わせることができます。
- 「Brain2Musicに会ってください:機能的磁気共鳴画像法(fMRI)を用いた脳活動から音楽を再構築するためのAI手法」
- 「拡散を支配するための1つの拡散:マルチモーダル画像合成のための事前学習済み拡散モデルの調節」
- 新しい技術の詳細なコース:AWS上の生成AIの基礎
LangChainがChatGPTやLLMとどのように異なるかという質問を受けました。この質問に答えるために、以下の表を添付します。
+==========+========================+====================+====================+| | LangChain | LLM | ChatGPT | +==========+========================+====================+====================+| 種類 | フレームワーク | モデル | モデル | +----------+------------------------+--------------------+--------------------+| 目的 | アプリケーションの構築 | テキスト生成 | チャット生成 | | | LLMを用いて | | | | | | | | | | | | | | | | | | | | | | | | | | | | +----------+------------------------+--------------------+--------------------+| 特徴 | チェーン、プロンプト、LLM、| 大規模なテキストと | 大規模なテキストと | | | メモリ、インデックス、エー| コードのデータセット | チャットのデータセ | | | ジェント | | ット | +----------+------------------------+--------------------+--------------------+| 利点 | LLMをプログラミング技術 | ほぼ人間の品質のテ | リアルなチャットの | | | と組み合わせることができ | キストを生成する | 対話を生成する | | | ることができます | | | +----------+------------------------+--------------------+--------------------+| 欠点 | 一定のプログラミング知識 | 特定のタスクには | LangChainほど汎用 | | | を必要とします | 使用しにくい | ではありません | +----------+------------------------+--------------------+--------------------+LangChainの基本コンポーネント
LangChainには、以下の6つの基本コンポーネントがあります:- モデル- プロンプト- チェーン- メモリ- インデックス- エージェントとツール
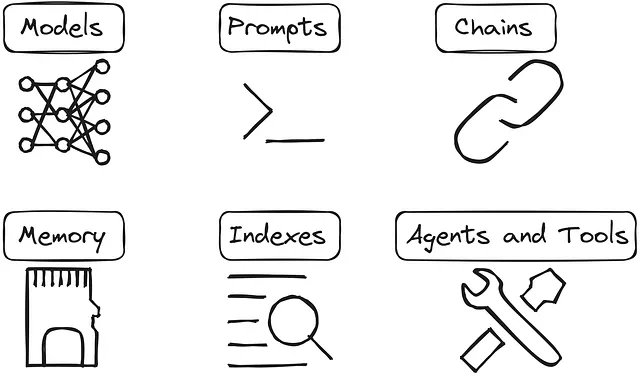
すべてのコンポーネントについて簡単に説明しましょう。
モデル
LangChainのモデルは、膨大な量のテキストとコードのデータセットでトレーニングされた大規模な言語モデル(LLM)です。
モデルは、LangChainでテキストを生成したり、質問に答えたり、言語を翻訳したりするために使用されます。また、フレームワークが後でアクセスできるように情報を格納するためにも使用されます。例:GPT-x、Bloom、Flan T5、Alpaca、LLama、Dolly、FastChat-T5など。
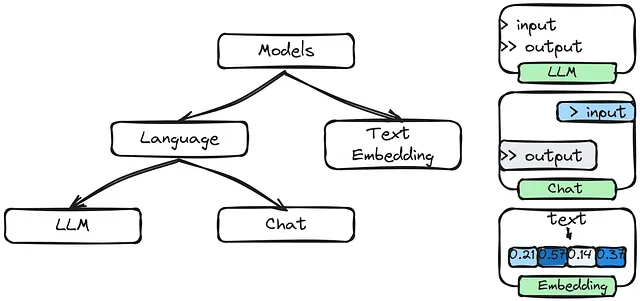
プロンプト
プロンプトは、LLMが望ましい出力を生成するためのテキストの断片です。プロンプトは単純または複雑であり、テキスト生成、言語の翻訳、質問に答えるなどに使用することができます。
LangChainでは、プロンプトはLLMの出力を制御するために重要な役割を果たします。プロンプトを注意深く作成することで、LLMに望ましい出力を生成させることができます。
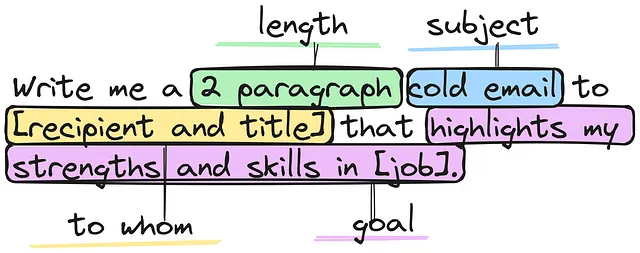
プロンプトの使用例をいくつか紹介します:
- 望ましい出力形式を指定する: たとえば、プロンプトを使用してLLMにテキストの生成や言語の翻訳、質問に答えるよう指示することができます。例: 入力をアラビア語に翻訳する
- 文脈を提供する: プロンプトはLLMに文脈を提供することができます。例えば、出力のトピックに関する情報や望ましい出力の例などです。例: 学校の先生のようにステップバイステップで回答を説明する
- 出力を制約する: プロンプトを使用してLLMの出力を制約することができます。出力の最大長を指定したり、出力に含めるキーワードのリストを選択したりすることができます。例: 140文字未満でツイートポストを生成する
インデックス
インデックスはデータの内容に関する情報を格納するためのユニークなデータ構造です。この情報には、各ドキュメントに含まれる用語、データセット内のドキュメントの位置、ドキュメント間の関係などが含まれます。ベクトルストアは、データセットの用語のベクトル表現を格納するデータ構造です。リトリーバーは、構造化されていないクエリに対してドキュメントを返すインターフェースです。ベクトルストアよりも広範な範囲をカバーしています。
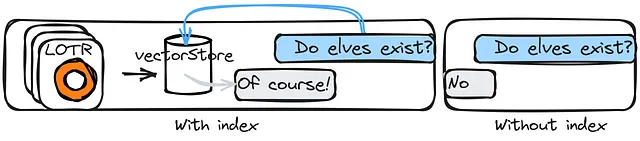
インデックス、ベクトルストア、およびリトリーバーの理解は、特定のデータに基づいてアプリを構築するための鍵となります。以下は、これらの3つのコンポーネントを含むチェーンの別の例を考えてみましょう:
- チェーンは金融に関する質問に答えるために形成されます。
- チェーンは、単語「ファイナンス」を含むすべてのドキュメントを見つけるためにインデックスを使用します。
- チェーンは、単語「ファイナンス」に最も類似した他の用語(「お金」、「投資」など)を見つけるためにベクトルストアを使用します。
- チェーンは、「どのように投資する方法はありますか?」というクエリに対してランク付けされたドキュメントを取得するためにリトリーバーを使用します。
メモリ
LangChainのメモリは、LLMが後でアクセスできるようにデータを格納する方法です。この情報には、以前のチェーンの結果、現在のチェーンのコンテキスト、LLMが必要とするその他の情報が含まれます。また、アプリケーションは現在の会話のコンテキストを追跡することができます。
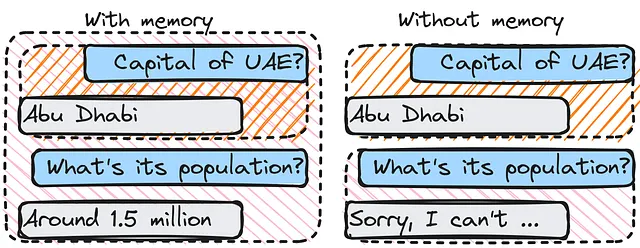
メモリはLangChainで重要な役割を果たし、LLMが以前の対話から学び、知識ベースを構築することができます。この知識ベースは、将来のチェーンのパフォーマンスを向上させるために使用することができます。
不動産に関する質問に答えるためのチェーンの作成を考えてみましょう。チェーンは、以前の不動産に関する質問に対応した前のチェーンの結果を記憶するためにメモリを使用するかもしれません。同じトピックに関する新しい質問がチェーンに対してされた場合、この情報を使用してパフォーマンスを向上させることができます。
チェーン
チェーンは、タスクを実行するためにLangChainフレームワークが実行する一連の命令です。チェーンは、アプリケーションの要件に基づいて他のLangChainコンポーネントを接続することができます。これにより、フレームワークはさまざまなタスクを実行することができます。
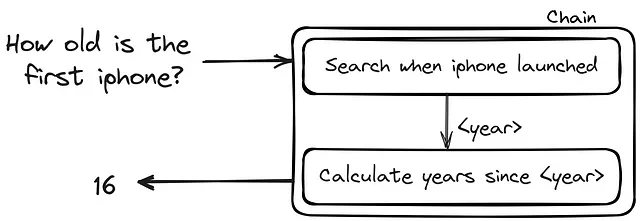
面接の準備を支援するアプリを作成しているとします:
- プロンプト: 「ソフトウェアエンジニアのポジションの面接の準備をしています。予想される一般的な面接の質問をしてくれますか?」
- 関数A: この関数は、ソフトウェアエンジニアリングの分野に関するLLMの知識、例えばソフトウェアエンジニア向けの一般的な面接の質問に関する知識やベクトルストア内の適切なデータの検索などを行います。
- 関数B: この関数は、質問のリストや面接の準備を支援するためのリソースのリストなど、データの操作を行います。質問を選択してそれを尋ねます。
- メモリ: 選択されたトピックの知識をより良く理解するために、追加の質問が行われる場合があります。メモリの実装により、チェーンは会話のコンテキストを保持することができます。
エージェントとツール
エージェントとツールは、LangChainで重要な概念です。エージェントは、テキスト生成、言語翻訳、質問応答など特定のタスクを実行できる再利用可能なコンポーネントです。ツールは、さまざまなエージェントの開発を支援するために使用できる関数ライブラリです。
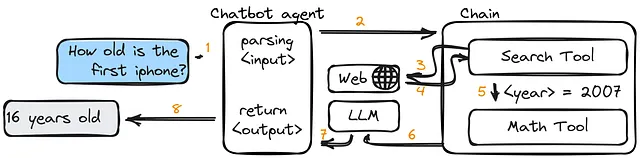
例:
NewsGeneratorエージェント-ニュース記事や見出しを生成するためのエージェント。DataManipulatorツール-データの操作(クリーニング、変換、特徴の抽出など)を支援するためのツール。
アプリケーション。Q&Aシステムの構築。
ColabとGithubのリンク。
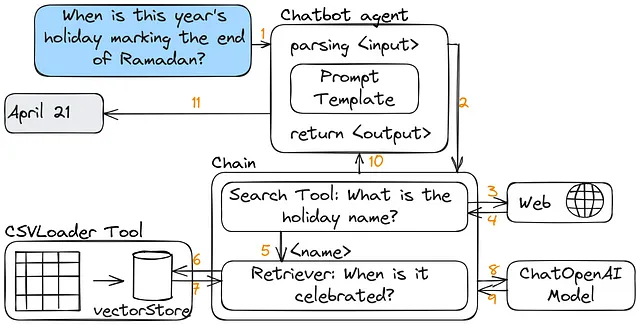
アラブ首長国連邦の公式休日に関する質問に答えるためのQ&Aシステムを構築しましょう。学んだコンポーネントに基づいて、以下のスキーマと類似したものを作成できます:
まず、すべての依存関係をインストールします。バージョンが更新される場合がありますが、特定のバージョンをインストールすることで、ほとんどまたはすべての内部依存関係が解決されます。
pip install chromadb==0.3.25 pydantic==1.10.9 openai==0.27.8 bs4 tiktoken==0.4.0 langchain==0.0.235 huggingface_hub==0.16.4 sentence_transformers==2.2.2 panda使用するデータは、以下のウェブサイトで見つけることができます(表に示されています):
+--------+-----+-----------------------------+| 日付 | 曜日 | 祝日 |+--------+-----+-----------------------------+| 1 1月 | 日 | 元日 || 4 月 20日 | 木 | イード・アル・フィトル休日 || 4 月 21日 | 金 | イード・アル・フィトル || 4 月 22日 | 土 | イード・アル・フィトル休日 || 4 月 23日 | 日 | イード・アル・フィトル休日 || 6 月 27日 | 火 | アラファトの日 || 6 月 28日 | 水 | イード・アル・アドハ || 6 月 29日 | 木 | イード・アル・アドハ休日 || 6 月 30日 | 金 | イード・アル・アドハ休日 || 7 月 21日 | 金 | イスラムの新年 || 9 月 29日 | 金 | ムハンマドの誕生日 || 12 月 1日 | 金 | 記念日 || 12 月 2日 | 土 | 国民の日 || 12 月 3日 | 日 | 国民の日休日 |+--------+-----+-----------------------------+データをメモリまたはデータフレームに保存した後、必要なパッケージをインポートできます:
# チャットモデル、埋め込み、および対話型AIのインデックスをロードfrom langchain.chat_models import ChatOpenAI #モデルfrom langchain.indexes import VectorstoreIndexCreator #インデックスfrom langchain.document_loaders.csv_loader import CSVLoader #ツールfrom langchain.prompts import PromptTemplate #プロンプトfrom langchain.memory import ConversationBufferMemory #メモリfrom langchain.chains import RetrievalQA #チェーン
import osos.environ['OPENAI_API_KEY'] = 'sk-...'このチュートリアルでは、OpenAI APIキーを使用します。今すぐすべてのモジュールを準備できます。
def load_llm(): # LLMモデルの設定 llm = ChatOpenAI(temperature=0,model_name="gpt-3.5-turbo") return llm
def load_index(): # ファイルの保存/読み込みの手順を回避したい場合は、VectorstoreIndexCreator()の`from_documents()`メソッドを使用できます loader = CSVLoader(file_path='uae_holidays.csv') index = VectorstoreIndexCreator().from_loaders([loader]) return indextemplate = """提供されたデータのみを基に、公式のUAEの祝日はいつですかという質問に答えるためのアシスタントです。コンテキスト:{context}-----------------------履歴:{chat_history}=======================ユーザー:{question}チャットボット:"""# テンプレートを使用してプロンプトを作成prompt = PromptTemplate( input_variables=["chat_history", "context", "question"], template=template)# チャット履歴を追跡するための会話メモリを設定memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True, input_key="question")# 検索ベースの対話型AIを設定qa = RetrievalQA.from_chain_type( llm=load_llm(), chain_type='stuff', retriever=load_index().vectorstore.as_retriever(), verbose=True, chain_type_kwargs={ "prompt": prompt, "memory": memory, })すべてのコンポーネントについて詳しく説明します。現時点では、OpenAIの「gpt-3.5-turbo」、カスタムプロンプト、デフォルトの「VectorstoreIndexCreator()」、チャット履歴の追跡のための「ConversationBufferMemory」を選択し、すべてを「RetrievalQA」チェーンに結び付けました。
3月/12月の休日
query = "3月に休日はありますか?"print_response_for_query(query)
> チェーンが終了しました。提供されたデータに基づいて、3月には休日はありません。正しい回答です。では、12月はどうですか?
query = "すみません、12月のことを言いたかったです"print_response_for_query(query)
> チェーンが終了しました。提供されたデータに基づいて、UAEには12月に公式の休日が2つあります。1つ目は12月1日の記念日で、金曜日です。2つ目は12月2日の国民の日で、土曜日です。さらに、12月3日には国民の日の休日があり、日曜日です。ここでメモリを使ったことに気づきましたか?もしそれがなかったら、回答は次のようになったでしょう:
> チェーンが終了しました。すみません、理解できません。12月に具体的に何を探していますか?最初のカウントで公式の休日が2つあるというエラーがあるにもかかわらず、回答にはリスト内の3つの休日が含まれていることに注意する価値があります。プロンプトのアップグレードで問題を解決することができます。
マルチチェーンのラマダンの例
では、もう少し難しい質問をしてみましょう。
query = "今年のラマダンの終わりを祝う休日はいつですか?"print_response_for_query(query)この場合、チェーンはまずラマダンの終わりを祝う休日の名前に関する情報を見つけ、それからテーブルから必要な情報を取得する必要があります。
> チェーンが終了しました。今年のラマダンの終わりを祝う休日であるイード・アル・フィトルは4月21日に始まります。非常に興味深いですね。チェーンは正しくイード・アル・フィトルをラマダンの終わりを祝う休日として特定しました。問題はデータが不正確であり、モデルが4日間の週末であることを認識できないことです。もちろん、簡単な解決策は、データをクリーンにするか、可能であればツールを使用してプロンプトを修正することです。
最も近い予定されている休日は何ですか?
最後に、次に来る公式の休日は何かを取得することです。
query = "今日は7月16日です。最も近い休日はいつですか?"print_response_for_query(query)
> チェーンが終了しました。最も近い休日はイスラム暦の新年で、7月21日です。ご覧のように、最も近い休日が正しく検出されています。質問に答えるために構築された可能なチェーンについては、考えることをあなたに任せます。
まとめ
今回の講義では、モデル、チェーン、プロンプト、エージェント、メモリ、およびインデックスなど、LangChainの基礎について学びました。また、LangChainがさまざまなタスクを実行し、質問に答えるアプリを構築する方法の例も見ました。
今後の講義
LangChain 101コースは現在開発中です。
コースの中で、以下のことを学びます:
- 自分のコンピュータでモデルを利用する方法
- 自分のデータを使用する方法
- より複雑なタスクを実行するためのチェーンの使用方法
- 情報を保存するためのメモリの使用方法
- その他多くの内容
LangChainを使用した実世界のアプリを引き続き構築していきます。
LangChainと関連情報、新しい講義、機能、チュートリアル、例などのアップデートを入手するために、VoAGIやLinkedInでフォローしていただけると幸いです。
お時間いただきありがとうございました!

We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






