「KOSMOS-2:Microsoftによるマルチモーダルな大規模言語モデル」
『KOSMOS-2:マイクロソフトによるマルチモーダルな大規模言語モデル』
イントロダクション
2023年はAIの年となりました。言語モデルから安定した拡散モデルの強化にSegMind APIを使うまで、AI技術は進化し続けています。その中で、Microsoftが開発したKOSMOS-2が注目を浴びています。これはマイクロソフトによって開発されたマルチモーダルの大規模言語モデル(MLLM)であり、テキストと画像の理解力において画期的な能力を発揮しています。言語モデルを開発することは一つのことですが、ビジョンモデルを作成することは別のことです。しかし、両方の技術を組み合わせたモデルを持つことは、さらなるレベルの人工知能を実現することになります。この記事では、KOSMOS-2の特徴と潜在的な応用について掘り下げ、AIと機械学習への影響を解説します。
学習目標
- KOSMOS-2のマルチモーダル大規模言語モデルの理解
- KOSMOS-2のマルチモーダルグラウンディングと参照表現生成の仕組みの学習
- KOSMOS-2の現実世界での応用について洞察を得る
- KOSMOSを使ったColabでの推論の実行
この記事はデータサイエンスブログマラソンの一部として公開されました。
KOSMOS-2モデルの理解
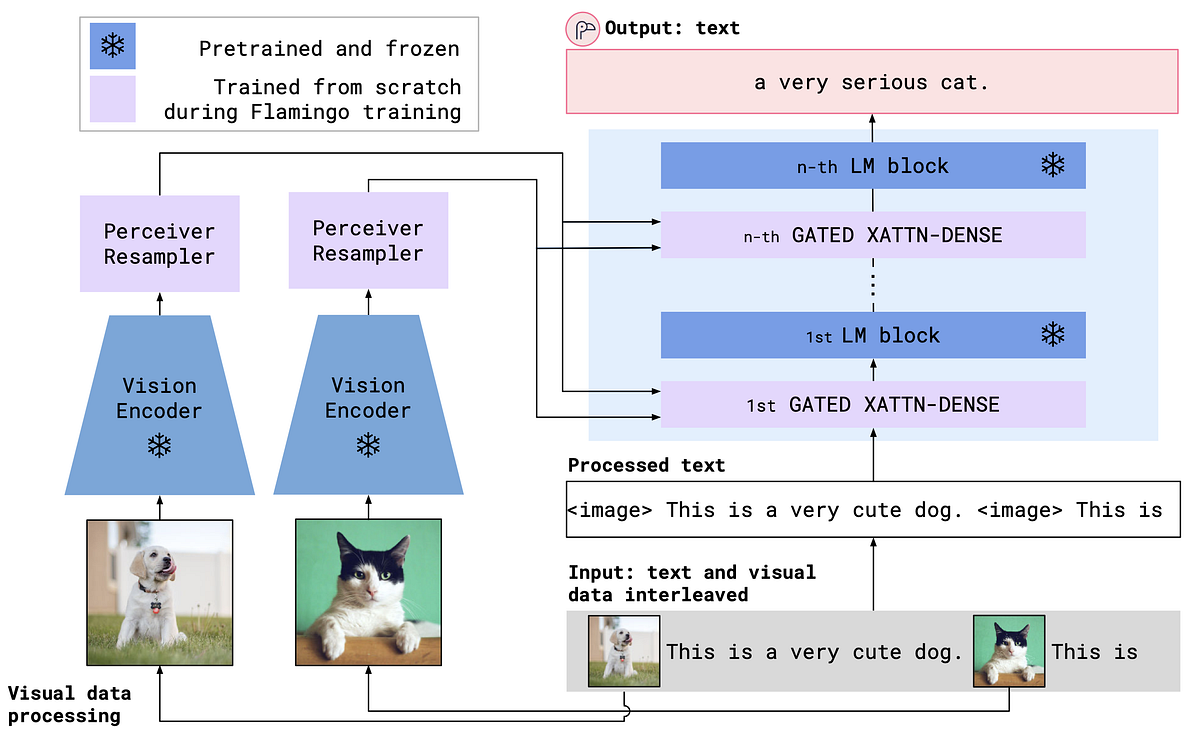
KOSMOS-2はマイクロソフトの研究チームによる研究成果で、そのタイトルは「Kosmos-2: Grounding Multimodal Large Language Models to the World(KOSMOS-2:マルチモーダル大規模言語モデルのグラウンディング)」です。テキストと画像を同時に処理し、マルチモーダルデータとの相互作用を再定義することを目指して設計されたKOSMOS-2は、他の有名なモデルであるLLaMa-2やMistral AIの7bモデルと同様にトランスフォーマーベースの因果言語モデルのアーキテクチャを採用しています。

- (CodeGPT AIコミュニティで話題となっている新たなコード生成ツールにご紹介します)
- コア42とCerebrasは、Jais 30Bのリリースにより、アラビア語の大規模言語モデルの新たな基準を設定しました
- 「隠れマルコフモデルの力を解読する」
しかし、KOSMOS-2の特徴はその独自のトレーニングプロセスです。特殊なトークンとして画像内のオブジェクトへの参照を含むテキストである、GRITと呼ばれる巨大なデータセットでトレーニングされています。この革新的なアプローチにより、KOSMOS-2はテキストと画像の新たな理解を提供することができます。
マルチモーダルグラウンディングとは何ですか?
KOSMOS-2の特徴的な機能の一つは、「マルチモーダルグラウンディング」の能力です。これは、画像のオブジェクトとその位置を記述するイメージキャプションを生成することができるという意味です。これにより、言語モデルにおける「幻覚」の問題を劇的に減少させ、モデルの精度と信頼性を向上させることができます。
この概念は、テキストを画像内のオブジェクトに特殊なトークンを通じて接続し、実質的にはオブジェクトを視覚的な文脈に結びつけるというものです。これにより幻覚が減少し、正確なイメージキャプションの生成能力が向上します。
参照表現生成
KOSMOS-2は「参照表現生成」でも優れた性能を発揮します。この機能により、ユーザーは画像内の特定のバウンディングボックスと質問でモデルにプロンプトを与えることができます。モデルは画像内の特定の箇所に関する質問に回答することができ、視覚コンテンツの理解と解釈の強力なツールとなります。
この「参照表現生成」の印象的なユースケースにより、ユーザーはプロンプトを使用して自然言語で視覚コンテンツとの対話を行うことができ、新たな可能性が広がります。
KOSMOS-2を使ったコードデモ
ColabでKOSMOS-2モードでの推論を実行する方法を紹介します。完全なコードはこちらからご覧いただけます:https://github.com/inuwamobarak/KOSMOS-2
ステップ1:環境の設定
このステップでは、🤗 Transformers、Accelerate、Bitsandbytesなどの必要な依存関係をインストールします。これらのライブラリはKOSMOS-2による効率的な推論に不可欠です。
!pip install -q git+https://github.com/huggingface/transformers.git accelerate bitsandbytesステップ2:KOSMOS-2モデルの読み込み
次に、KOSMOS-2モデルとそのプロセッサを読み込みます。
from transformers import AutoProcessor, AutoModelForVision2Seqprocessor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")model = AutoModelForVision2Seq.from_pretrained("microsoft/kosmos-2-patch14-224", load_in_4bit=True, device_map={"": 0})ステップ3:画像とプロンプトの読み込み
このステップでは、画像のグラウンディングを行います。画像を読み込み、モデルの完了のためのプロンプトを提供します。画像内のオブジェクトを参照するために重要な<grounding>トークンを使用します。
import requestsfrom PIL import Imageprompt = "<grounding>画像の"<grounding>An image of"url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.png"image = Image.open(requests.get(url, stream=True).raw)image
ステップ4:完了の生成
次に、プロセッサを使用してモデルに画像とプロンプトを準備させます。それから、モデルに自己回帰的に完了を生成させます。生成された完了は、画像とその内容に関する情報を提供します。
inputs = processor(text=prompt, images=image, return_tensors="pt").to("cuda:0")# Autoregressively generate completiongenerated_ids = model.generate(**inputs, max_new_tokens=128)# Convert generated token IDs back to stringsgenerated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]ステップ5:後処理
生の生成テキストを見て、画像パッチに関連するトークンが含まれている場合があります。この後処理ステップにより、意味のある結果を得ることができます。
print(generated_text)
<image>. the, to and of as in I that' for is was- on’ it with The as at bet he have from by are " you his “ this said not has an ( but had we her they will my or were their): up about out who one all been she can more would It</image><grounding> An image of<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> warming up by<phrase> a fire</phrase><object><patch_index_0006><patch_index_0879></object>ステップ6:さらなる処理
このステップでは、最初の画像関連のトークンを超えた生成テキストに焦点を当てます。オブジェクト名、フレーズ、場所トークンなどの詳細な情報を抽出します。この抽出された情報はより意味があり、モデルの応答をより理解することができます。
# By default, the generated text is cleaned up and the entities are extracted.processed_text, entities = processor.post_process_generation(generated_text)print(processed_text)print(entities)
An image of a snowman warming up by a fire[('a snowman', (12, 21), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a fire', (36, 42), [(0.203125, 0.015625, 0.484375, 0.859375)])]
end_of_image_token = processor.eoi_tokencaption = generated_text.split(end_of_image_token)[-1]print(caption)
<grounding> An image of<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> warming up by<phrase> a fire</phrase><object><patch_index_0006><patch_index_0879></object>ステップ7:バウンディングボックスをプロットする
画像で識別されたオブジェクトのバウンディングボックスの可視化方法を示します。このステップでは、モデルが特定のオブジェクトをどこに配置したかを把握することができます。抽出した情報を活用して画像に注釈を付けることができます。
from PIL import ImageDrawwidth, height = image.sizedraw = ImageDraw.Draw(image)for entity, _, box in entities: box = [round(i, 2) for i in box[0]] x1, y1, x2, y2 = tuple(box) x1, x2 = x1 * width, x2 * width y1, y2 = y1 * height, y2 * height draw.rectangle(xy=((x1, y1), (x2, y2)), outline="red") draw.text(xy=(x1, y1), text=entity)image
ステップ8:グラウンディングされた質問応答
KOSMOS-2を使用して、画像内の特定のオブジェクトと対話することができます。このステップでは、バウンディングボックスと特定のオブジェクトに関連する質問をモデルに提示します。モデルは、コンテキストと画像からの情報に基づいて回答を提供します。
url = "https://huggingface.co/ydshieh/kosmos-2-patch14-224/resolve/main/pikachu.png"image = Image.open(requests.get(url, stream=True).raw)image
ピカチュウについての質問とバウンディングボックスを準備することができます。特別な<phrase>トークンの使用は、質問にフレーズが存在していることを示しています。このステップでは、グラウンディングされた質問応答によって画像から特定の情報を取得する方法を示します。
prompt = "<grounding> 質問: このキャラクターは何ですか? 答え:"inputs = processor(text=prompt, images=image, bboxes=[(0.04182509505703422, 0.39244186046511625, 0.38783269961977185, 1.0)], return_tensors="pt").to("cuda:0")ステップ9:グラウンディングされた回答の生成
モデルに対して質問の自己回帰的な完了を許可し、提供されたコンテキストに基づいて回答を生成します。
generated_ids = model.generate(**inputs, max_new_tokens=128)generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]# デフォルトでは、生成されたテキストは整形され、エンティティが抽出されます。processed_text, entities = processor.post_process_generation(generated_text)print(processed_text)print(entities)
質問: このキャラクターは何ですか? 答え: アニメの中のピカチュウです。[('this character', (18, 32), [(0.046875, 0.390625, 0.390625, 0.984375)])]KOSMOS-2の応用
KOSMOS-2の機能は、研究室にとどまらず、実世界の応用に広がっています。その影響を及ぼす可能性のあるいくつかの分野には以下が含まれます:
- ロボティクス: 雲が重そうなら、ロボットに寝ている間に起こしてもらうように指示することができたらどうでしょう。ロボットが状況に適応的に空を見る能力は貴重な特徴です。KOSMOS-2は、ロボットに統合されて、環境を理解し、指示に従い、テキストと画像を通じて世界とのやり取りを通じて経験を観察し理解することができます。
- ドキュメントインテリジェンス: 外部環境に加えて、KOSMOS-2はドキュメントインテリジェンスにも使用できます。これは、テキスト、画像、表を含む複雑なドキュメントを分析し理解するために使用されます。関連情報の抽出と処理を容易にします。
- マルチモーダルダイアログ: AIの一般的な使用法は、言語またはビジョンに関連するものです。KOSMOS-2を使用すると、チャットボットと仮想アシスタントを連携させることができ、テキストと画像を含むユーザーのクエリに理解して応答することができます。
- 画像キャプショニングと視覚的質問応答: これらは、画像のキャプションを自動的に生成し、視覚情報に基づいて質問に答えるものであり、広告、ジャーナリズム、教育などの産業に応用があります。これには、特定のユースケースに特化したバージョンの生成や微調整も含まれます。
実践的な現実世界での活用例
私たちは、KOSMOS-2の能力が従来のAIと言語モデルを超えていることを見てきました。具体的な応用例を見てみましょう:
- 自動運転: KOSMOS-2は、自動車内のオブジェクトの相対位置を検出および理解することにより、自動運転システムの向上の可能性を持っています。例えば、ウィンカーやホイールなどの車内のオブジェクトをより知的な判断に基づいて扱うことができ、複雑な運転シナリオでのより賢明な意思決定を可能にします。また、高速道路上で歩行者を識別し、彼らの体の位置に基づいて彼らの意図を伝えることができます。
- 安全とセキュリティ: ポリスセキュリティロボットを構築する際には、KOSMOS-2のアーキテクチャを使用して、人々が「凍結」した状態にあるかどうかを検出することができます。
- 市場調査: さらに、KOSMOS-2は市場調査においても画期的な存在となる可能性があります。多量のユーザーフィードバック、画像、レビューを一緒に分析することができます。KOSMOS-2は、質的データを定量化し、統計分析と組み合わせることで、規模の大きな価値ある洞察を提供する新たな方法を提供します。
マルチモーダルAIの未来
KOSMOS-2は、マルチモーダルAIの分野において大きな飛躍を表しています。テキストと画像を正確に理解し記述する能力により、新たな可能性が開かれています。AIが進化するにつれて、KOSMOS-2のようなモデルは高度な機械知能を実現に近づけ、産業の革新をもたらします。
現在は仮説上のみの存在である人工汎用知能(AGI)に向けて、KOSMOS-2は最も近いモデルの一つです。もし実現されれば、AGIは人間が行えるタスクを学習することができます。
結論
マイクロソフトのKOSMOS-2は、テキストと画像を組み合わせて新たな機能と応用を創造するAIの潜在能力を示しています。AIが届くはずがないと考えられていた領域への進出が期待されます。未来は近づいており、KOSMOS-2のようなモデルがそれを形作っています。KOSMOS-2のようなモデルは、AIと機械学習の進歩を促進し、テキストと画像の間の鴨長川を埋め、産業を革新し、革新的な応用の扉を開きます。マルチモーダル言語モデルの可能性を追求するにつれて、AIのエキサイティングな進歩が期待され、AGIのような高度な機械知能の実現への道が開かれるでしょう。
まとめ
- KOSMOS-2は、テキストと画像を理解することができる画期的なマルチモーダル大型言語モデルであり、テキスト内の境界ボックスを使用したユニークなトレーニングプロセスが特徴です。
- KOSMOS-2は、画像内のオブジェクトの位置を指定するイメージキャプションを生成することにおいて、マルチモーダルグラウンディングに優れており、幻想を抑制しモデルの精度を向上させます。
- このモデルは、画像内の特定の位置に関する質問を境界ボックスを使用して回答することができ、視覚的なコンテンツとの自然言語のやり取りの新たな可能性を提供します。
よくある質問
参考文献
- https://github.com/inuwamobarak/KOSMOS-2
- https://github.com/NielsRogge/Transformers-Tutorials/tree/master/KOSMOS-2
- https://arxiv.org/pdf/2306.14824.pdf
- https://huggingface.co/docs/transformers/main/en/model_doc/kosmos-2
- https://huggingface.co/datasets/zzliang/GRIT
- Peng, Z., Wang, W., Dong, L., Hao, Y., Huang, S., Ma, S., & Wei, F. (2023). Kosmos-2: Grounding Multimodal Large Language Models to the World. ArXiv. /abs/2306.14824
この記事に表示されるメディアはAnalytics Vidhyaの所有ではなく、著者の裁量により使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「40歳以上の方にオススメのAIツール(2023年11月版)」
- はい、GitHubのCopilotは(実際の)秘密を漏洩する可能性があります
- 「初めに、AWS上でMONAI Deployを使用して医療画像AI推論パイプラインを構築しましょう!」
- 「Amazon CodeWhispererで持続可能性を最適化しましょう」
- テストに合格する:NVIDIAがMLPerfベンチマークでジェネラティブAIのトレーニングをターボチャージします
- NVIDIAはAPECの国々と協力し、人々の生活を変え、機会を増やし、成果を改善します
- クラウドウォッチの高度なメトリクス、ダッシュボード、アラートを使用してAWSのコストを最適化する