JuliaでのMS SQL Serverの操作
JuliaでのMS SQL Server操作
データ分析ワークフローをスーパーチャージしましょう
SQLデータベースは世界中で広く展開されているソフトウェアの一つです。ビジネスデータ分析から天気予報まで、さまざまなアプリケーションの基盤となっています。現在、いくつかのクライアント・サーバー実装が存在し、MicrosoftのSQL Serverがその一つです。フル機能を備えた開発者向けエディションは無料で利用できます。Windows、Linux、およびDockerを介して実行できます。
データサイエンティストはしばしばSQLデータベースに格納されたデータと対話する必要があります。Pythonなどの言語を使ってこれを行う方法は簡単に見つけることができますが、Juliaのチュートリアルは非常に少ないです。そのため、この記事ではJuliaを使用してSQL Serverと連携する方法に焦点を当てます。サンプルコードはJulia 1.9.1を実行しているLinux(Elementary OS)上のPlutoノートブックで生成されています。
前提条件
- SQL Server 2022
ローカルで実行されているSQLサーバーが必要です。最も簡単な設定方法はDockerを使用することです。SQL Server 2022の手順はこちらで提供されています。Dockerコンテナが実行されているかどうかを確認するには、次のコマンドを使用します:
watch -n 2 sudo docker ps -aこれにより2秒ごとに更新され、STATUS列には「Up X minutes」と表示されるはずです。ここでXはコンテナの起動から経過した時間です。
- GPBoostを使用した縦断およびパネルデータのための混合効果機械学習(パートIII)
- 「データクリーニングでPandasを使用する前にこれを読むべき理由」
- 「データアクセスはほとんどの企業で大きな課題であり、71%の人々が合成データが役立つと考えています」
2. Microsoft ODBC Driver 17 for Linux
手順はこちらで提供されています。新しいドライバー18を使用してデータベースに接続できなかったため、そのドライバーの使用はお勧めできません。
3. sqlcmdユーティリティ(オプション)
sqlcmdユーティリティを使用すると、Transact-SQLステートメントを入力することができ、すべてが予想どおりに動作しているかをテストするのに便利です。手順はこちらで提供されています。
パッケージの読み込み
以下のJuliaパッケージが必要になります。Plutoノートブックを使用している場合、組み込みのパッケージマネージャーが自動的にダウンロードしてインストールします。
using ODBC, DBInterface, DataFramesドライバーの確認
Open Database Connectivity(ODBC)ドライバーを使用すると、SQLサーバーに接続することができます。ODBC.jlパッケージを使用して、システム上で現在利用可能なドライバーを確認できます:

ドライバーの場所がわかれば、ドライバーをインストールすることも可能です。

ドライバーを削除するには、次のコマンドを使用します:

接続の追加
完全な接続文字列を使用して、事前に設定したローカルで実行されているSQLサーバーに接続できます。IPアドレス、ポート、既存のデータベース名、ユーザーID、およびパスワードが必要です。データベース名が不明な場合は、常にデフォルトで存在する「master」に接続することができます。

すべての既存のデータベースのリスト
conn_masterオブジェクトを使用して、サーバー上でクエリを実行できます。すべてのデータベースをリストアップしましょう。
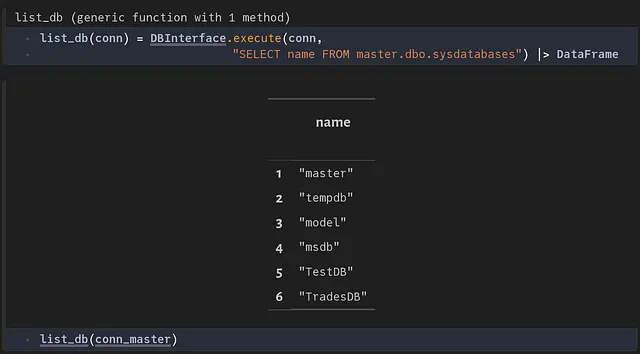
新しいデータベースを作成する
新しいデータベースを作成するためには、まずlist_db関数を使用して名前が既に存在するかどうかを確認する必要があります。 存在しない場合は、以下の例で示されているように ‘FruitsDB’ として作成します。

再びすべてのデータベースをリストアップすると、’FruitsDB’ が作成されたことが確認できます。

新しいテーブルを作成する
SQL Server データベースには、データの順序付けられたコレクションであるテーブルが含まれています。 テーブル自体は行(レコード)のコレクションです。 テーブルにデータを追加する前に、既存のデータベース内にテーブルを作成する必要があります。 例として、’FruitsDB’ 内に ‘Price_and_Origin’ という名前のテーブルを作成しましょう。 このテーブルには、Name(文字列)、Price(浮動小数点数)、Origin(文字列)の3つの列が含まれます。 VARCHAR(50)は可変長の文字列データを示すために使用されます。 50はバイト単位のサイズであり、単一バイトエンコーディングの場合、これは文字列の長さも表します。
新しいテーブルに追加する
テーブルが存在する場合、データを追加することができます。 最も簡単な方法は、ソースとして DataFrame を使用することです。 テーブル ‘Price_and_Origin’ では、名前、価格、原産地の3つの列が必要です。 したがって、以下のようにいくつかのダミーデータを使用できます:
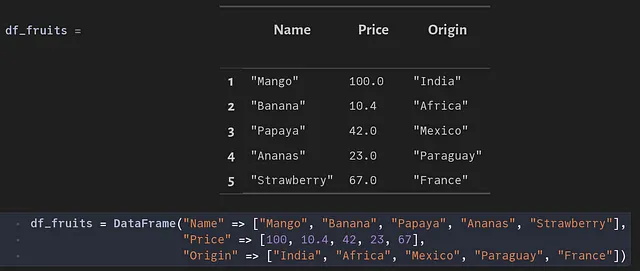
値を挿入するには、DBInterface.executemany 関数を使用できます。 これにより、シーケンス内の複数の値を渡すことができます。 これは以下の関数で行うことができます。 finally 節は、DBInterface.close! 関数を使用してデータベース接続を閉じることを保証します。 これは一般的には良い習慣であり、同じ接続を誤って他の用途に再利用することを防ぐのに役立ちます。

データベースが予想どおりに作成されたかどうかを確認しましょう。 SQL Server 上の ‘FruitsDB’ に接続するための接続 ‘conn_fruit’ を最初に設定します。 次に、テーブル ‘Price_and_Origin’ からすべてのエントリを選択し、DataFrame シンクに渡すことができます。
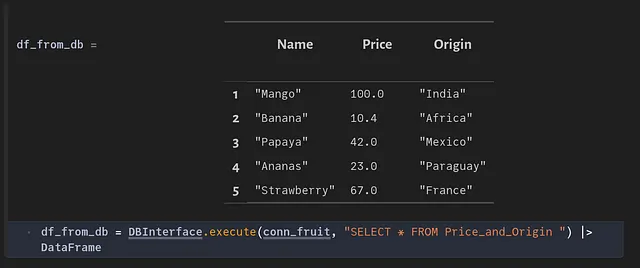
テーブルの更新
前のセクションと同じ手順に従って、データベースを新しいデータで更新することができます。

新しいデータがデータベース内に実際に存在するかどうかを確認しましょう。
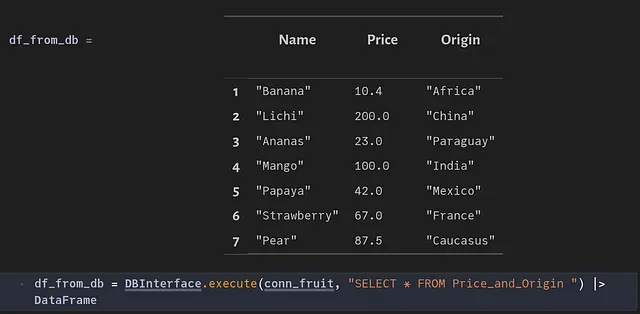
重複の削除
上記のadd_to_fruit_table関数を再実行すると、テーブルに重複した行が追加されます。
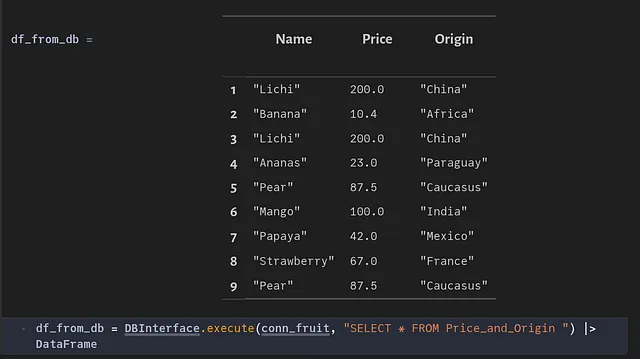
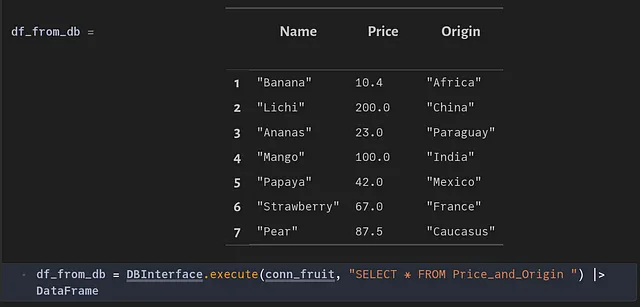
共通のテーブル式(CTE)を使用することで、指定されたテーブルから重複した行を削除することができます。以下の関数がこれを実現します:

行が一意であるかどうかを確認します。
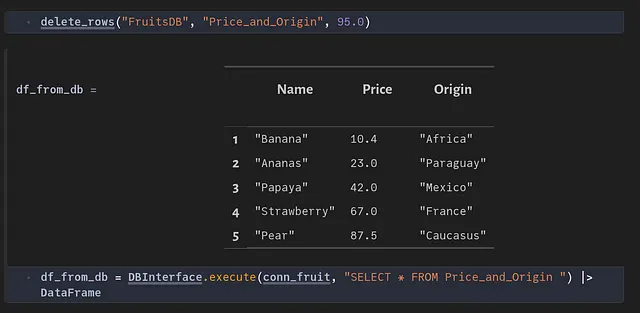
レコードの削除
データベース内のテーブルから、特定の条件に一致するエントリを削除することはよくあります。例えば、以下のように価格が95より大きい果物をすべて削除することができます:
テーブルの削除
DBInterface.execute関数内でDROPステートメントを使用すると、テーブルを削除することができます。関数の残りの部分はdelete_rowsと同じままです。
DBInterface.execute(conn_db, "DROP TABLE $table_name")結論
DBInterface.execute関数は有効なSQLステートメントを入力として受け入れます。したがって、既に提示されている内容に加えて、ここで説明されているすべての種類のクエリを実行することが可能です。先に示したように、クエリの結果は簡単にJuliaのDataFrame sinkに渡すことができ、それを使用して追加の操作を実行することができます。
ODBC.jlとDBInterface.jlパッケージは積極的にメンテナンスされており、特にDataFramesの使用が関係している場合にうまく統合されているようです。これにより、Juliaを使用してデータ分析や可視化を行うための新たな可能性が広がります。このエクササイズが役立つことを願っています。お時間をいただき、ありがとうございました! LinkedInで私とつながるか、私のWeb 3.0パワードのウェブサイトを訪問してください。
参考文献
- https://odbc.juliadatabases.org/stable/#Getting-Started
- https://juliadatabases.org/DBInterface.jl/dev/
- https://www.w3schools.com/sql/default.asp
- https://learn.microsoft.com/en-us/sql/?view=sql-server-linux-ver16
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「データを分析するためにOpenAIのコードインタープリタを使う方法」
- データサイエンスにおけるツールに依存しない方向へ:SQLのCase WhenとPandasのWhere
- 「私のデータサイエンスキャリアの2年後に発見した、Jupyter Notebookの5つの裏技」
- 「データサイエンス、機械学習、コンピュータビジョンプロジェクトを強化する 効果的なプロジェクト管理のための必須ツール」
- 「H1 2023 アナリティクス&データサイエンスの支出とトレンドレポート」
- 「2023年の機械学習モデルにおけるトップな合成データツール/スタートアップ」
- 「ChatGPTを活用したデータ探索:データセットの隠れた洞察を解き放つ」
