Juliaでの一致するチャットボットの構築
Juliaでのチャットボット構築
コンフォーマル予測、LLM、およびHuggingFace — パート1
大規模言語モデル(LLM)は現在非常に注目されています。テキスト分類、質問応答、テキスト生成など、さまざまなタスクに使用されています。このチュートリアルでは、ConformalPrediction.jlを使用して、テキスト分類のためのトランスフォーマーランゲージモデルをコンフォーマライズする方法を示します。
👀 一目でわかること
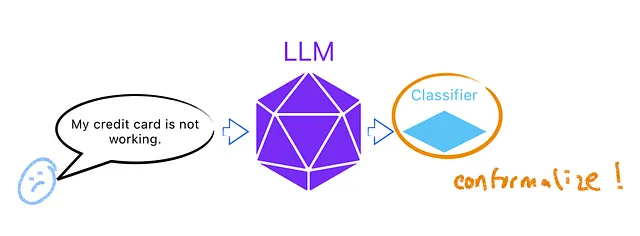
特に、以下のスケッチで示される意図分類のタスクに興味があります。まず、顧客のクエリをLLMに入力して埋め込みを生成します。次に、これらの埋め込みを可能な意図に一致させるために分類器をトレーニングします。もちろん、この教師あり学習の問題では、入力(クエリ)と真の意図を示すラベルのトレーニングデータが必要です。最後に、コンフォーマル予測を適用して分類器の予測的な不確実性を定量化します。
コンフォーマル予測(CP)は、予測的不確実性の定量化のための急速に進化している方法論です。CPについて詳しく知りたい場合は、まずこの投稿を始める私の3部作の紹介シリーズを参照してください。
🤗 HuggingFace
私たちはBanking77データセット(Casanueva et al.、2020)を使用します。このデータセットには、銀行に関連する77の意図に関する13,083のクエリが含まれています。モデル側では、Banking77データセットでファインチューニングされたRoBERTa(Liu et al.、2019)の蒸留バージョンであるDistilRoBERTaモデルを使用します。
- アラウカナXAI:医療における意思決定木を用いたローカル説明性
- ディープAIの共同創業者兼CEO、ケビン・バラゴナ氏- インタビューシリーズ
- 「インテルCPU上での安定したディフューションモデルのファインチューニング」
モデルはTransformers.jlパッケージを使用してHFから直接実行中のJuliaセッションにロードできます。
このパッケージを使用すると、HFモデルをJuliaで非常に簡単に扱うことができます。開発者に感謝します! 🙏
以下では、トークナイザーtkrとモデルmodをロードしています。トークナイザーはテキストを整数のシーケンスに変換し、それがモデルに入力されます。モデルは隠れ状態を出力し、それが分類器に入力され、各クラスのロジットを取得します。最後に、ロジットはソフトマックス関数を介して対応する予測確率を取得します。以下では、いくつかのクエリをモデルに実行してパフォーマンスを確認します。
# HFからモデルをロード 🤗:tkr =…We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






