データ分析の求人トレンド:求人トレンド分析のためのNLP
データ分析求人の最新トレンド:NLPを活用した求人トレンド分析
マハンテーシュ・パッタドカル & アンドレア・デ・マウロによる
データアナリティクスは、データが重要な意思決定プロセスでどのように活用されるかの進歩により、近年著しい成長を遂げています。データの収集、保管、分析もこれらの進展により大きく進歩しています。さらに、データアナリティクスの人材需要は急増しており、必要なスキルと経験を持つ個人のために求人市場は激しく競争が激化しています。
データ駆動型テクノロジーの急速な拡大は、データエンジニアなどの専門的な役割への需要の増加にも繋がっています。この需要の急増はデータエンジニアリングだけに留まらず、データサイエンティストやデータアナリストといった関連職種も含まれます。
これらの職業の重要性を認識し、私たちのブログシリーズでは、オンラインの求人広告からリアルワールドのデータを収集し、それぞれのカテゴリー内で必要な多様なスキルセットとともに、これらの仕事の需要の性質を理解するために分析します。
- 初心者のデータサイエンスの面接を成功させるためのヒント
- あなたのプロジェクトに最適な5つのデータ管理ツール
- VoAGIニュース、10月5日:Pythonのマスターに役立つ無料の5冊の本 • データサイエンスのためのトップ7の無料クラウドノートブック
このブログでは、「データアナリティクスの求人トレンド」を視覚化し分析するためのブラウザベースの「データアナリティクス求人トレンド」アプリケーションを紹介します。オンライン求人サイトからデータをスクレイピングし、NLP技術を使用して求人投稿に必要な主要なスキルセットを特定します。図1はデータアプリのスナップショットであり、データアナリティクス求人市場のトレンドを探索しています。

この実装については、低コードデータサイエンスプラットフォームであるKNIME Analytics Platformを採用しました。このオープンソースかつ無料のエンドツーエンドデータサイエンスプラットフォームは、ビジュアルプログラミングに基づいており、ETL操作からデータブレンドのためのさまざまなデータソースコネクタまで、ディープラーニングを含む機械学習アルゴリズムまで幅広い機能を提供しています。
アプリケーションの基盤となるワークフローは、KNIMEコミュニティハブの「データアナリティクス求人トレンド」から無料でダウンロードできます。ブラウザベースのインスタンスは、「データアナリティクス求人トレンド」で評価することができます。
「データアナリティクス求人トレンド」アプリケーション
このアプリケーションは、図2に示されている4つのワークフローによって生成され、以下の手順で順次実行されます:
- データ収集のためのWebスクレイピング
- NLPパーシングとデータクリーニング
- トピックモデリング
- 仕事の役割とスキルの寄与の分析
これらのワークフローは、KNIMEコミュニティハブのパブリックスペース – データアナリティクス求人トレンドで利用可能です。

- 「01_Webスクレイピングによるデータ収集」ワークフローは、オンライン求人広告をクロールし、テキスト情報を構造化された形式に抽出します
- 「02_NLPパーシングとクリーニング」ワークフローは、必要なクリーニング手順を実行し、長いテキストをより小さな文に分割します
- 「03_トピックモデリングと探索データアプリ」は、クリーンデータを使用してトピックモデルを構築し、その結果をデータアプリ内で視覚化します
- 「04_仕事のスキルの帰属」ワークフローは、LDAの結果に基づいて、データサイエンティスト、データエンジニア、データアナリストなどの仕事の役割ごとのスキルの関連性を評価します。
データ収集のためのWebスクレイピング
求人市場で求められるスキルについて最新の理解を得るために、オンラインの求人広告からのウェブスクレイピングによる求人投稿の分析を選択しました。地域の違いや言語の多様性を考慮し、アメリカ合衆国の求人広告に焦点を当てました。これにより、求人広告の相当部分が英語で表記されていることが保証されます。また、2023年2月から2023年4月までの求人広告に焦点を当てました。
図3のKNIMEワークフロー「01_Web Scraping for Data Collection」は、求人エージェンシーのウェブサイトでの検索URLのリストをクロールします。
データアナリティクスに関連する求人情報を抽出するために、データアナリティクスの領域を網羅する6つのキーワードを使用しました。具体的には、「ビッグデータ」、「データサイエンス」、「ビジネスインテリジェンス」、「データマイニング」、「機械学習」、「データアナリティクス」です。検索キーワードはExcelファイルに保存され、Excel Readerノードを介して読み込まれます。
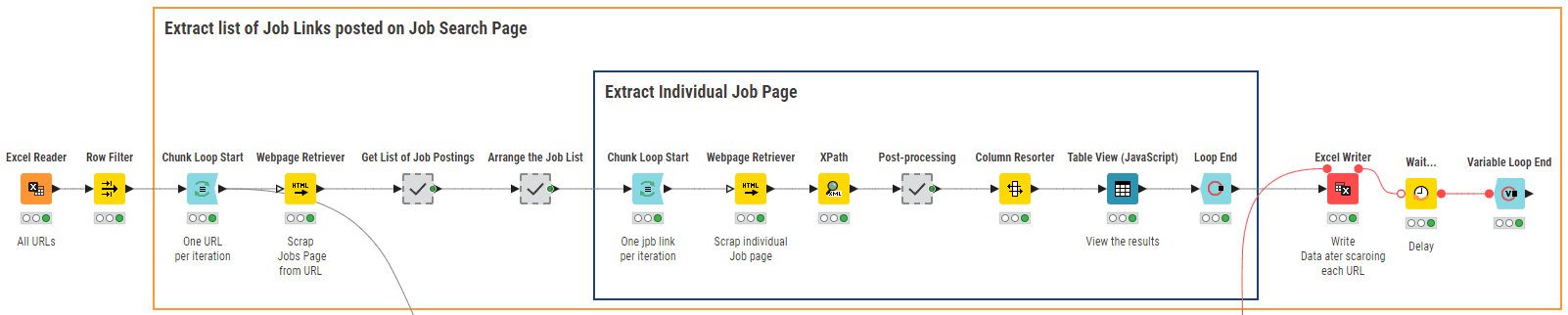
このワークフローの中核ノードはWebpage Retrieverノードです。このノードは2回使用されます。1回目(外側のループ)では、キーワードを入力としてサイトをクロールし、米国で過去24時間以内に公開された求人情報の関連URLのリストを生成します。2回目(内側のループ)では、ノードは各求人URLからテキストコンテンツを取得します。Webpage Retrieverノードに続くXpathノードは、求人のタイトル、必要な資格、求人の説明、給与、会社の評価など、必要な情報に到達するために抽出されたテキストを解析します。最後に、結果はさらなる分析のためにローカルファイルに書き込まれます。図4は2023年2月にスクレイピングされた求人情報のサンプルを示しています。

NLPパーシングとデータクリーニング
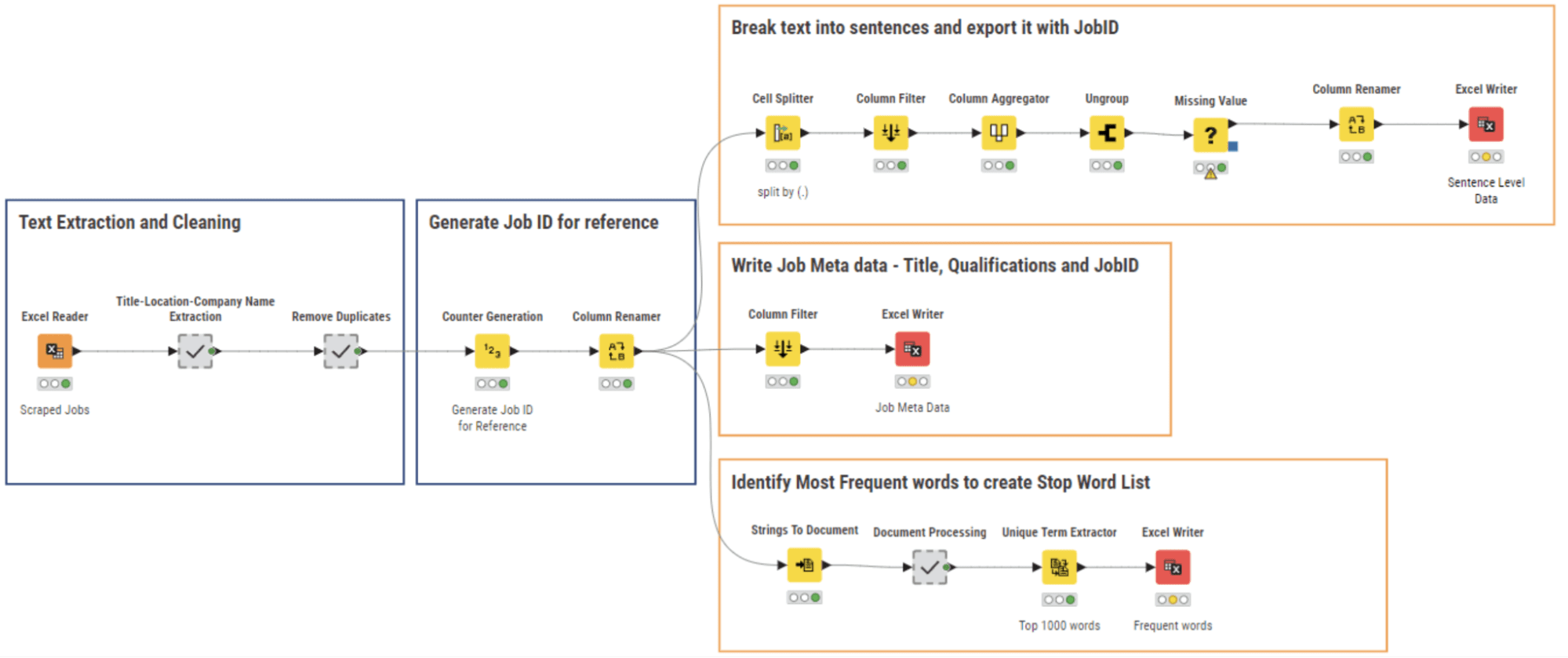
新鮮に収集されたデータと同様に、ウェブスクレイピングの結果はクリーニングが必要です。我々はNLPパーシングとデータクリーニングを実行し、Figure 5に示すワークフロー02_NLP Parsing and cleaningを使用して、それぞれのデータファイルを書き込みます。
スクレイピングされたデータからは、複数のフィールドが文字列値の連結形式で保存されています。ここでは、「Title-Location-Company Name Extraction」というメタノード内のString Manipulationノードの一連の操作を使用して各セクションを抽出し、不要な列を削除して重複行を取り除きました。
その後、各求人テキストに固有のIDを割り当て、Cell Splitterノードを使用してドキュメント全体を文に分割しました。求人のメタ情報(タイトル、場所、会社)も抽出され、求人IDと共に保存されます。
すべてのドキュメントから最も頻度の高い1000単語のリストを抽出し、次のNLPタスクには「応募者」、「コラボレーション」、「雇用」などの単語を含むストップワードリストを生成しました。これらの単語はすべての求人に存在するため、次のNLPタスクには何の情報も追加しません。
クリーニングフェーズの結果は、次の3つのファイルのセットです:
– ドキュメントの文を含むテーブル
– 求人の説明メタデータを含むテーブル
– ストップワードリストを含むテーブル
トピックモデリングと結果の探索
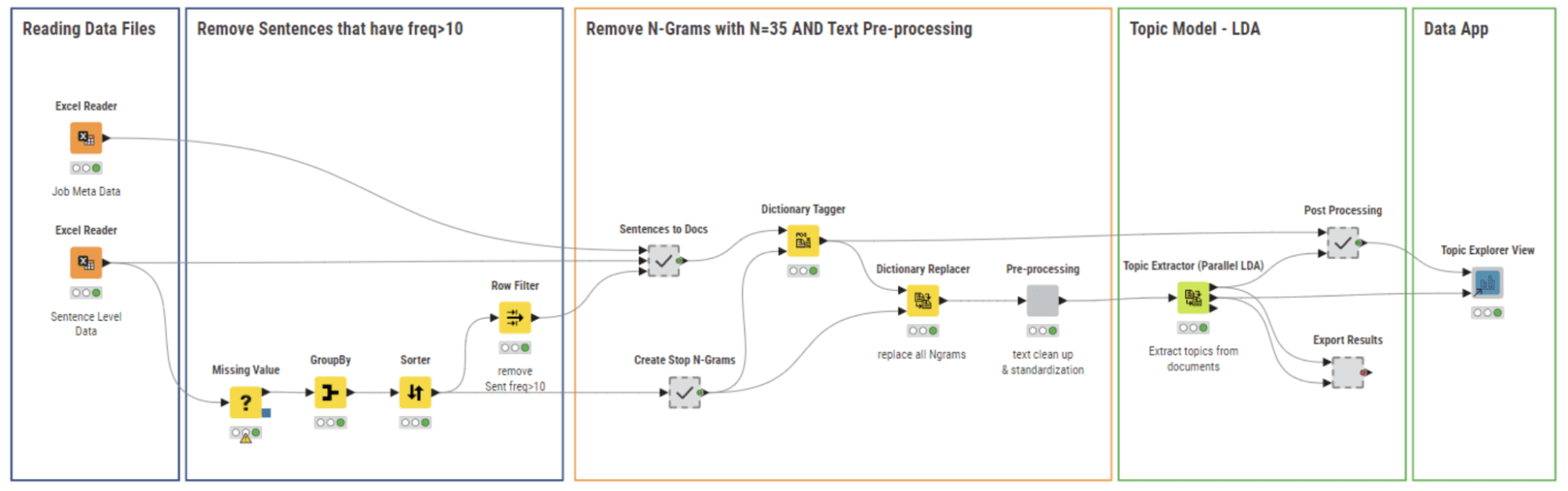
ワークフロー03_Topic Modeling and Exploration Data App(図6)は、前のワークフローからのクリーンデータファイルを使用しています。この段階では、次のことを目指しています:
- 多くの求人に現れる一般的な文(ストップフレーズ)を検出して削除する
- トピックモデリングのためにデータを準備するための標準的なテキスト処理手順を実行する
- トピックモデルを構築し、結果を可視化する
上記のタスクについては、以下のサブセクションで詳細に議論します。
3.1 N-グラムを使用してストップフレーズを削除する
多くの求人広告には、企業の方針や一般的な合意事項によく見られる文言が含まれています。たとえば、「非差別方針」とか「機密保持契約」といったものです。図7は、求人広告1と求人広告2で「非差別」方針に言及している例を示しています。これらの文は私たちの分析には関連性がないため、テキストコーパスから削除する必要があります。私たちはこれらを「ストップフレーズ」と呼び、それらを特定してフィルタリングするために2つのメソッドを使用します。
最初のメソッドは簡単です。コーパス内の各文の頻度を計算し、頻度の値が10を超える文を除外します。
2番目のメソッドはN-グラムのアプローチを使用し、Nの値を20から40の範囲で試します。Nの値を選択し、コーパスから導出されたN-グラムがストップフレーズとして分類される個数を数えることで、N-グラムの関連性を評価します。このプロセスを範囲内の各Nの値に対して繰り返します。私たちは、N=35が最も多くのストップフレーズを特定するための最適な値であると選びました。

図7に示すワークフローに従って、我々は「ストップフレーズ」を削除するために両方のメソッドを使用しました。最初に最も頻度の高い文を削除し、次にN=35のN-グラムを作成し、Dictionary Taggerノードを使用して各文書にタグ付けし、最後にDictionary Replacerノードを使用してこれらのN-グラムを削除しました。
3.2 テキスト前処理技術を使用してトピックモデリング用のデータを準備する
ストップフレーズを削除した後、トピックモデリング用のデータを準備するために標準的なテキスト前処理を行います。
まず、コーパスから数値と英数字を削除します。次に、句読点や一般的な英語のストップワードを削除します。さらに、以前に作成したカスタムストップワードリストを使用して、職種に固有のストップワードをフィルタリングします。最後に、すべての文字を小文字に変換します。
私たちは意味を持つ単語に焦点を当てることにしましたので、文書内の単語にParts of Speech (POS) タグを割り当てて名詞と動詞のみを保持するようにフィルタリングします。このタグ付けとフィルタリングにはPOS Taggerノードを使用します。
最後に、コーパスをトピックモデリングのために準備するためにStanfordのレンマ化を適用します。これらの前処理ステップは、図6に示されている「Pre-processing」コンポーネントによって実行されます。
3.3 トピックモデルの構築と可視化
実装の最終段階では、図6に示されているTopic Extractor (Parallel LDA)ノードを使用して潜在ディリクレ配分(LDA)アルゴリズムを適用してトピックモデルを構築しました。LDAアルゴリズムは、いくつかのトピック(k)を生成し、各トピックを(m)個のキーワードで説明します。パラメータ(k、m)を定義する必要があります。
補足として、kとmは大きすぎないようにする必要があります。なぜなら、トピック(スキルセット)をキーワード(スキル)とそれらの重みを確認することによって可視化し解釈したいからです。kについては[1, 10]の範囲を探索し、mの値を15に固定しました。注意深い分析の結果、k=7が最も多様で明確なトピックを持ち、キーワードの重複が最小であることがわかりました。したがって、k=7を私たちの分析において最適な値としました。
インタラクティブデータアプリでトピックモデリングの結果を探索する
誰もがトピックモデリングの結果にアクセスし、それを自分自身で試すことができるようにするために、私たちはワークフロー(図6)をデータアプリとしてKNIME Business Hubに展開し、公開しました。誰もがアクセスできるようになりました。以下からチェックできます。データ分析の求人トレンド。
このデータアプリのビジュアル部分は、 Francesco TuscolanoとPaolo Tamagniniによる、KNIMEコミュニティハブから無料でダウンロードできるTopic Explorer Viewコンポーネントから提供されており、トピックとドキュメントのさまざまなインタラクティブな視覚化を提供します。
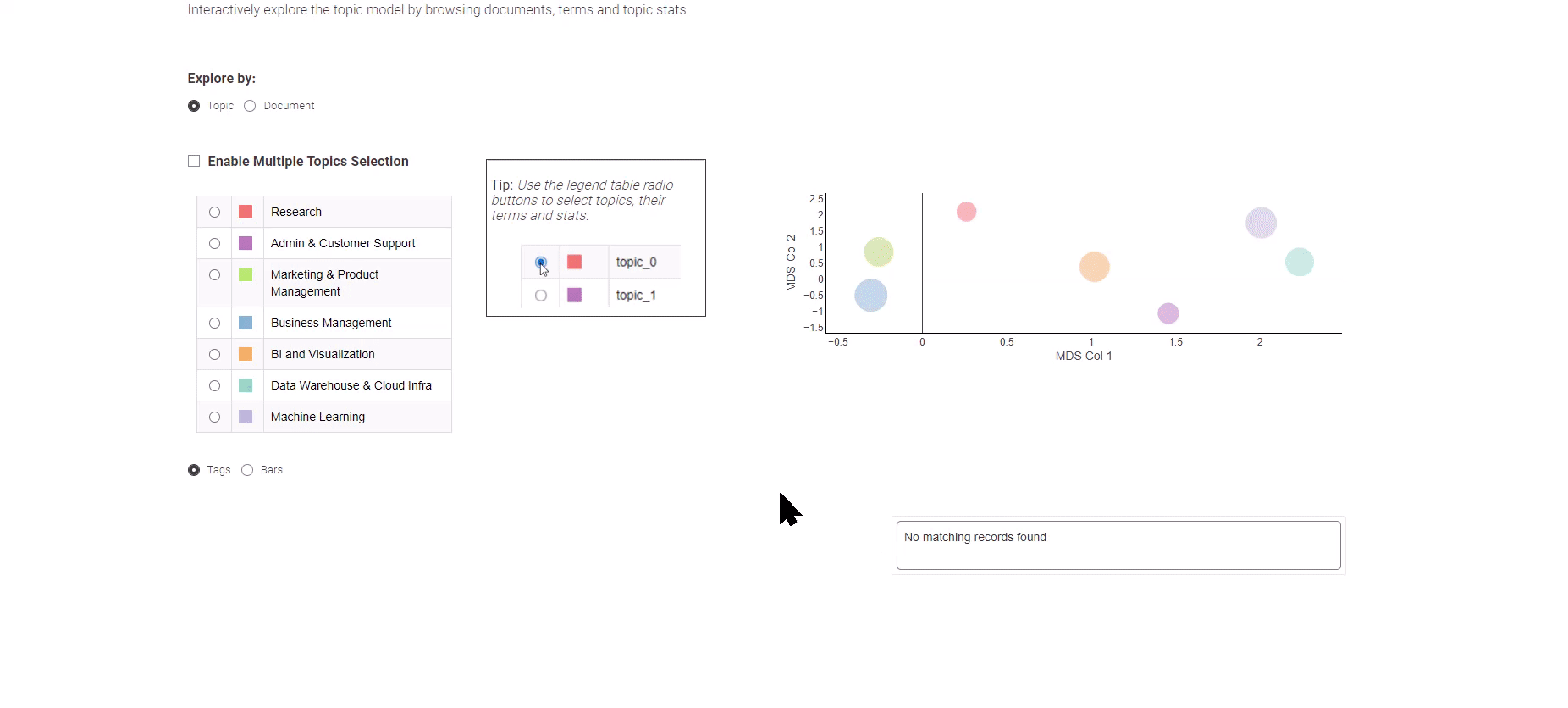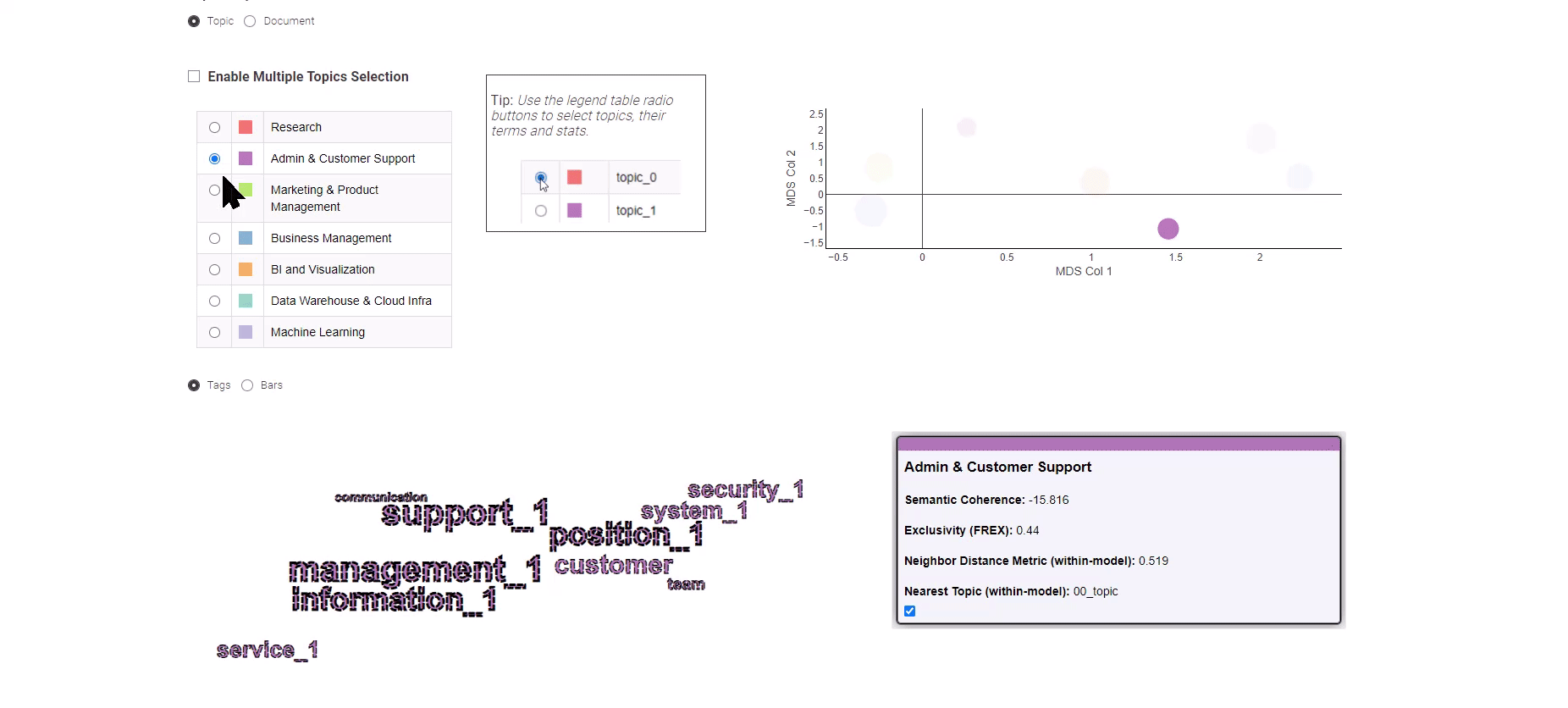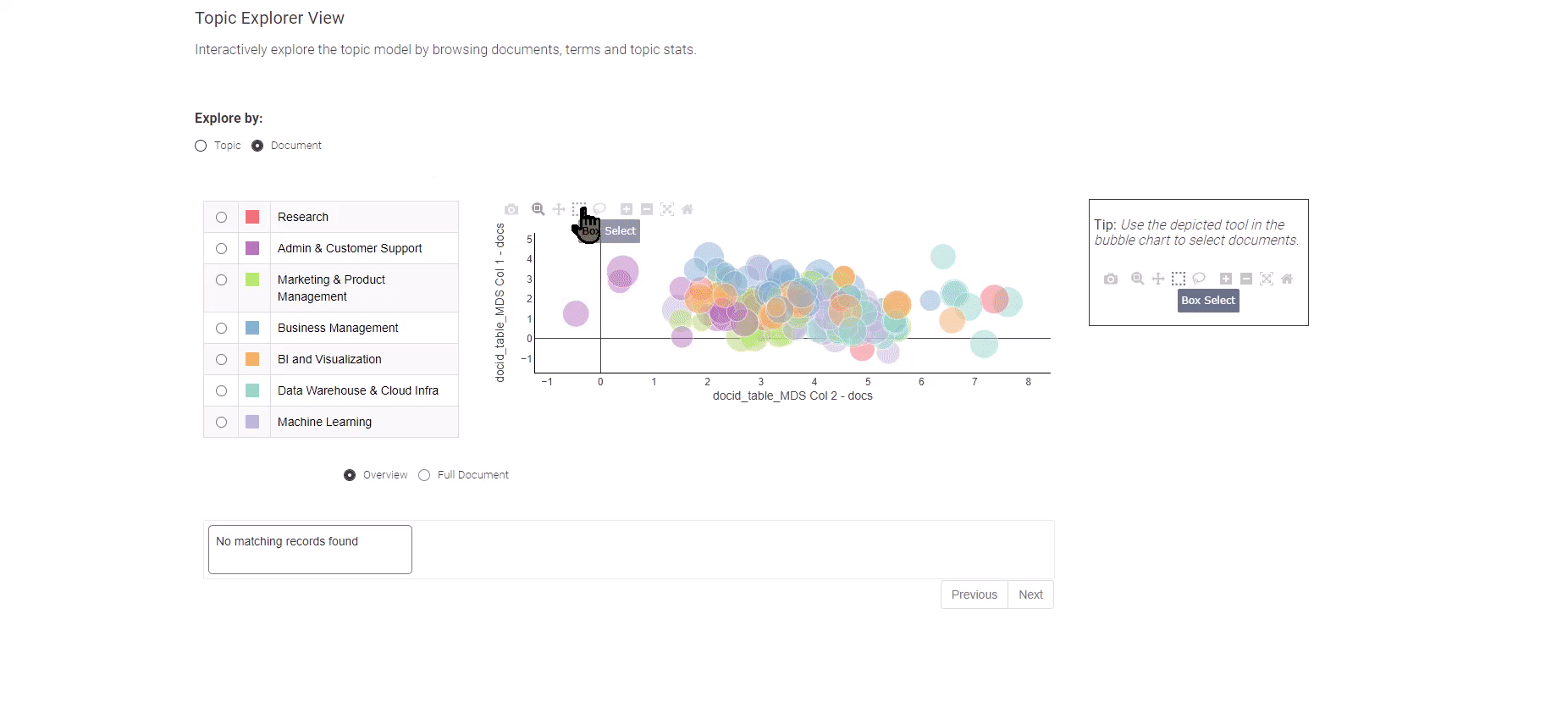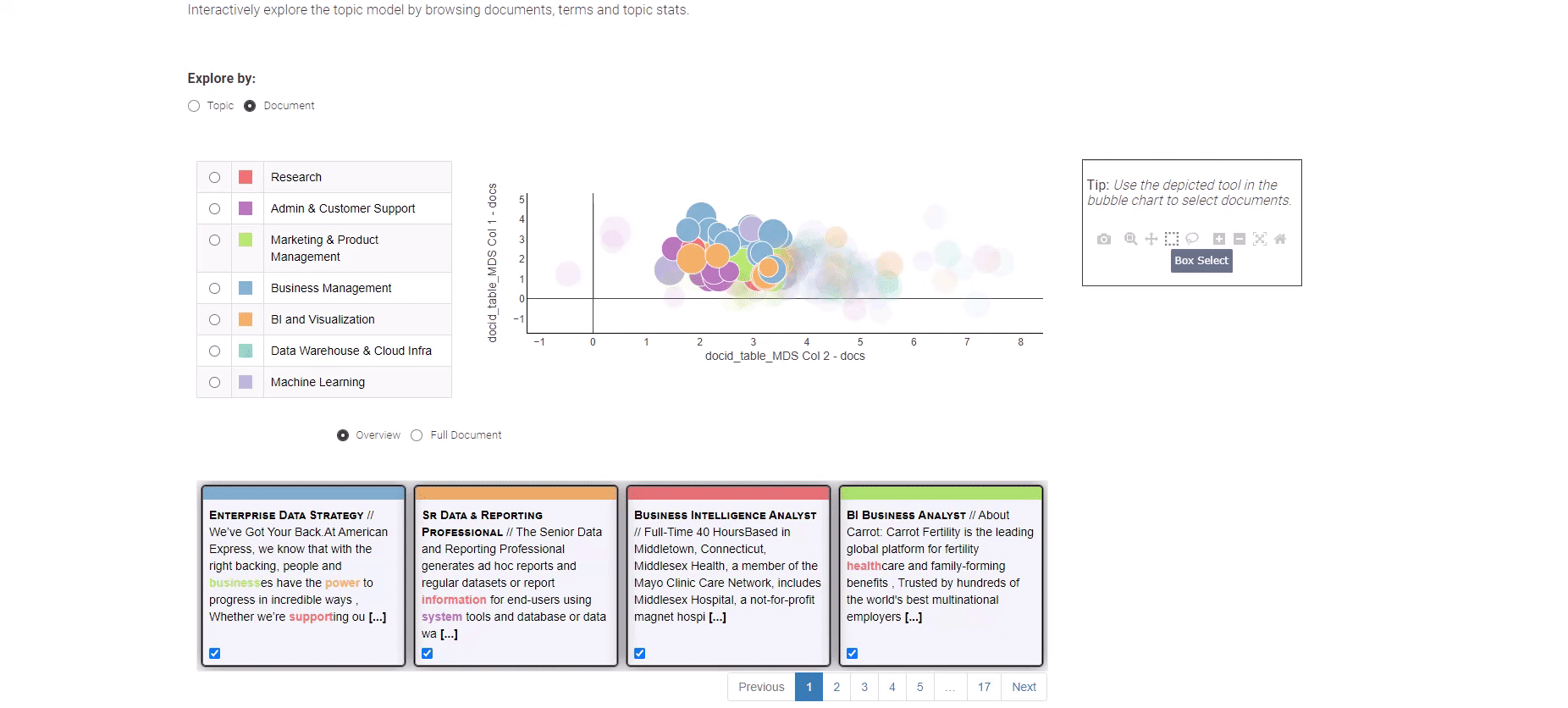 図8: データ分析の求人トレンド(トピックモデリングの結果の探索)
図8: データ分析の求人トレンド(トピックモデリングの結果の探索)
図8に示されているこのデータアプリでは、2つの異なるビュー、「トピックビュー」と「ドキュメントビュー」の間で選択できます。
「トピックビュー」は、多次元スケーリングアルゴリズムを使用して2次元プロット上にトピックを表示し、それらの間の意味的な関係を効果的に示します。左側のパネルで興味のあるトピックを選択して、それに対応する上位キーワードを表示できます。
個々の求人情報の探索に進むには、「ドキュメントビュー」を選択してください。このビューでは、2つの次元を横断してすべてのドキュメントを簡略化して表示します。重要なドキュメントを特定するためにボックス選択メソッドを利用し、一番下には選択したドキュメントの概要が表示されます。
NLPを利用したデータ分析の求人市場の探索
ここでは、「データ分析の求人トレンド」というアプリケーションの概要を提供しています。このアプリケーションは、データサイエンスの求人市場における最新のスキル要件や役割を探索するために実装され、使用されました。このブログでは、2023年2月から4月までの期間に、米国の英語で書かれた求人のジョブデスクリプションに絞って行いました。
求人のトレンドを理解し、レビューを提供するために、「データ分析の求人トレンド」は求人代理店のサイトをクロールし、オンラインの求人広告からテキストを抽出し、一連のNLPタスクを実行した後にトピックとキーワードを抽出し、データ内のパターンを明らかにするためにトピックとドキュメントごとに結果を視覚化します。
このアプリケーションは、ウェブスクレイピング、データ処理、トピックモデリング、そしてインタラクティブな視覚化のための4つのKNIMEワークフローのセットで構成されており、ユーザーが求人のトレンドを把握できるようになります。
私たちはこのワークフローをKNIME Business Hubに展開し、公開しましたので、誰でもアクセスできます。以下からチェックできます。データ分析の求人トレンド。
ワークフローの全セットは、KNIMEコミュニティハブからデータ分析の求人トレンドで無料でダウンロードできます。ワークフローは簡単に変更し、求人市場の他の分野のトレンドを発見するために適応できます。検索キーワードのリストをExcelファイル内で変更し、ウェブサイトおよび検索の期間を変更するだけです。
結果はどうでしょうか?今日のデータサイエンスの求人市場で最も求められているスキルと専門職は何でしょうか?次のブログ記事では、このトピックモデリングの結果の探索を通じて、ジョブロールとスキルの興味深い相互作用を詳しく検証します。その過程でデータサイエンスの求人市場について貴重な洞察を得ます。刺激的な探索にご期待ください!
リソース
- データ分析の求人要件とオンラインコースの体系的なレビュー by A. マウロ 他。
Mahantesh Pattadkalは、データサイエンスのコンサルティングで6年以上の経験を持ちました。データサイエンスの修士号を持つ彼は、ディープラーニング、自然言語処理、説明可能な機械学習においてその専門知識を発揮しています。また、彼はKNIMEコミュニティとの協力を通じてデータサイエンスベースのプロジェクトに積極的に関与しています。
アンドレア・デ・マウロは、P&Gやボーダフォンなどの多国籍企業でビジネスアナリティクスとデータサイエンスチームの構築に15年以上の経験を持っています。企業の役割に加えて、彼はイタリアとスイスのいくつかの大学でマーケティングアナリティクスと応用機械学習の教鞭を執っています。彼はデータとAIのビジネスと社会的な影響を研究し、広範な分析リテラシーが世界をよりよくすると信じています。彼の最新の本はPacktから出版された「データ分析が簡単になる」です。彼はCDOマガジンの2022年の「40歳未満の40人」のリストにも掲載されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
