JAXの始め方
'JAXを始める方法'
高性能な数値計算と機械学習の研究の未来を支える
イントロダクション
JAXは、Googleが開発したPythonライブラリであり、どのようなデバイス(CPU、GPU、TPUなど)でも高性能な数値計算を行うためのものです。 JAXの主な応用の1つは、機械学習とディープラーニングの研究開発ですが、このライブラリは主に一般的な科学計算タスク(高次元行列操作など)を実行するための必要な機能を提供するように設計されています。
特に高性能コンピューティングに焦点を当てると、JAXはXLA(加速線形代数)をベースに構築されているため、非常に高速に動作するように設計されています。 XLAは、線形代数演算の高速化を目的としたコンパイラであり、TensorFlowやPyTorchなどの他のフレームワークでも使用することができます。さらに、JAXの配列はNumpyと同じ原則に従って設計されており、古いNumpyのコードを簡単にJAXに移行し、GPUやTPUを使用したパフォーマンスの向上を活用することができます。
JAXの主な特徴のいくつかは次のとおりです:
- Just in Time(JIT)コンパイル:JITと高速化ハードウェアによって、JAXは素のNumpyよりもはるかに高速に動作することが可能です。 jit()関数を使用することで、XLAカーネルでカスタム関数をコンパイルしてキャッシュすることができます。キャッシュを使用することで、関数を最初に実行するときの実行時間が増えますが、次の実行では時間を大幅に短縮することができます。キャッシュを使用する場合は、必要に応じてキャッシュをクリアすることが重要です(たとえば、グローバル変数が変更される場合など)。
- 自動並列化:非同期ディスパッチにより、JAXベクトルは遅延評価され、計算が完了する前にコンテンツが具現化されます(制御がプログラムに戻されます)。また、グラフの最適化を可能にするために、JAX配列はイミュータブルです(Apache Sparkでも遅延評価とグラフの最適化の概念が適用されます)。pmap()関数を使用すると、複数のGPU / TPUで計算を並列化することができます。
- 自動ベクトル化:vmap()関数を使用すると、自動的に操作を並列化するためのベクトル化が行われます。ベクトル化では、アルゴリズムが単一の値ではなく、一連の値で動作するように変換されます。
- 自動微分:grad()関数を使用すると、関数の勾配(導関数)を自動的に計算することができます。特に、JAXの自動微分は、ディープラーニングの範囲外で一般の微分プログラムの開発を可能にします。再帰、分岐、ループを通して微分を行うことができ、高階微分(ヤコビアンやヘッシアンなど)を実行し、順方向および逆方向のモードの微分を使用することができます。
したがって、JAXは高度なディープラーニングモデルを構築するために必要な基盤を提供できますが、最も一般的なディープラーニング操作(損失/活性化関数、レイヤーなど)に対するすぐに使用できる高レベルのユーティリティは提供していません。たとえば、MLトレーニング中に学習されたモデルのパラメータは、JAXのPytree構造に格納することができます。 JAXの提供するすべての利点を考慮して、Haiku(DeepMindが使用)やFlax(Google Brainが使用)など、さまざまなDL志向のフレームワークが構築されています。
デモンストレーション
この記事の一環として、JAXとKaggle Mobile Price Classificationデータセット[1]を使用して、単純な分類問題を解決する方法を見ていきます。この記事全体で使用されたコード(およびその他のもの)は、私のGitHubアカウントとKaggleアカウントで使用できます。
まず、環境にJAXがインストールされていることを確認する必要があります。
pip install jaxこの時点で、必要なライブラリとデータセットをインポートする準備が整いました(図1)。分析を簡単にするために、ラベルのすべてのクラスを使用する代わりに、データをフィルタリングして2つのクラスだけを使用し、特徴量の数を減らします。
import pandas as pdimport jax.numpy as jnpfrom jax import gradfrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import classification_reportimport matplotlib.pyplot as pltdf = pd.read_csv('/kaggle/input/mobile-price-classification/train.csv')df = df.iloc[:, 10:]df = df.loc[df['price_range'] <= 1]df.head()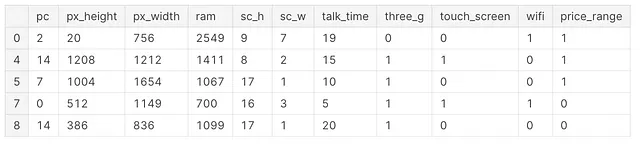
データセットをクリーンアップした後、トレーニングセットとテストセットに分割し、入力特徴量を標準化して、すべての特徴量が同じ範囲内にあることを確認します。この時点で、入力データはJAX配列に変換されます。
X = df.iloc[:, :-1]y = df.iloc[:, -1]X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, stratify=y)X_train, X_test, y_train, Y_test = jnp.array(X_train), jnp.array(X_test), \ jnp.array(y_train), jnp.array(y_test)scaler = StandardScaler()scaler.fit(X_train)X_train = scaler.transform(X_train)X_test = scaler.transform(X_test)電話の価格帯を予測するために、ゼロからロジスティック回帰モデルを作成します。そのために、まずいくつかのヘルパー関数(シグモイド活性化関数を作成するための1つとバイナリ損失関数を作成するためのもう1つ)を作成する必要があります。
def activation(r): return 1 / (1 + jnp.exp(-r))def loss(c, w, X, y, lmbd=0.1): p = activation(jnp.dot(X, w) + c) loss = jnp.sum(y * jnp.log(p) + (1 - y) * jnp.log(1 - p)) / y.size reg = 0.5 * lmbd * (jnp.dot(w, w) + c * c) return - loss + reg トレーニングループを作成し、結果をプロットする準備ができました(図2)。
n_iter, eta = 100, 1e-1w = 1.0e-5 * jnp.ones(X.shape[1])c = 1.0history = [float(loss(c, w, X_train, y_train))]for i in range(n_iter): c_current = c c -= eta * grad(loss, argnums=0)(c_current, w, X_train, y_train) w -= eta * grad(loss, argnums=1)(c_current, w, X_train, y_train) history.append(float(loss(c, w, X_train, y_train)))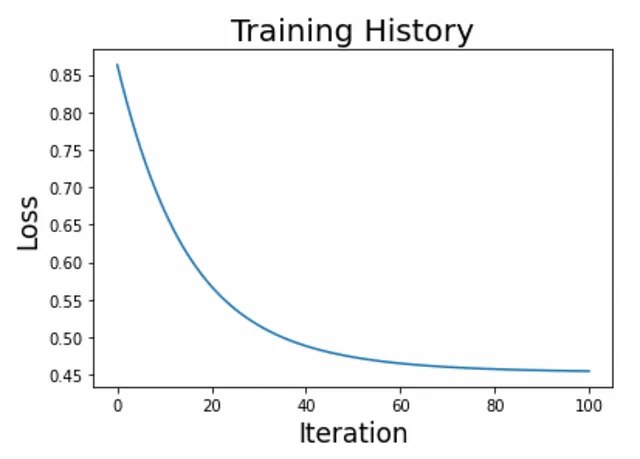
結果に満足したら、テストセットに対してモデルをテストできます(図3)。
y_pred = jnp.array(activation(jnp.dot(X_test, w) + c))y_pred = jnp.where(y_pred > 0.5, 1, 0) print(classification_report(y_test, y_pred))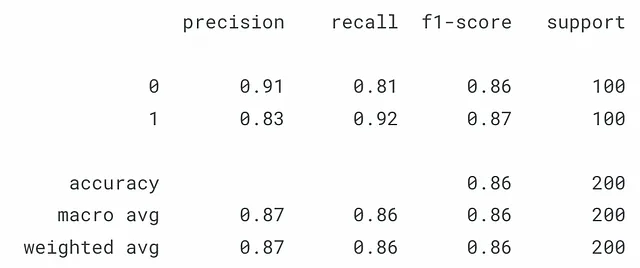
結論
この短い例で示されるように、JAXは非常に直感的なAPIを持ち、Numpyの規則に密接に従いながら、CPU/GPU/TPUの使用に対応することができます。これらのビルディングブロックを使用することで、パフォーマンスに最適化された高度にカスタマイズ可能なディープラーニングモデルを作成することができます。
連絡先
最新の記事やプロジェクトについては、VoAGIで私をフォローし、メーリングリストに登録してください。以下は私の連絡先の詳細です:
- 個人ウェブサイト
- VoAGIプロフィール
- GitHub
- Kaggle
参考文献
[1] “Mobile Price Classification” (ABHISHEK SHARMA)。アクセス先:https://thecleverprogrammer.com/2021/03/05/mobile-price-classification-with-machine-learning/(MITライセンス:https://github.com/alifrmf/Mobile-Price-Prediction-Classification-Analysis/tree/main)
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- JourneyDBとは:多様かつ高品質な生成画像が400万枚収録された大規模データセットであり、マルチモーダルな視覚理解のためにキュレーションされています
- Amazon SageMaker Ground Truthのはじめ方
- 人材分析のための R ツールキット:ヘッドカウントのストーリーを伝える
- 自分の脳の季節性を活用した、1年間のデータサイエンスの自己学習プランの作成方法
- 探索的データ解析:データセットの中に隠されたストーリーを解き明かす
- NumpyとPandasを超えて:知られざるPythonライブラリの潜在能力の解放
- ロッテン・トマト映画の評価予測のデータサイエンスプロジェクト:2つ目のアプローチ
