動詞理解のための画像言語トランスフォーマーの調査
Investigating Image Language Transformers for Verb Understanding.
言語を視覚に結びつけることは、画像の検索や視覚障害者のための説明生成など、多くの現実世界のAIシステムにとって基本的な問題です。これらのタスクでの成功には、モデルがオブジェクトや動詞など、言語の異なる側面を画像と関連付ける必要があります。たとえば、以下の中央の列の2つの画像を区別するには、モデルが「キャッチ」と「キック」という動詞を区別する必要があります。動詞の理解は特に困難であり、オブジェクトを認識するだけでなく、画像内の異なるオブジェクトの関係性も理解する必要があります。この困難を克服するために、私たちはSVO-Probesデータセットを導入し、動詞の理解について言語とビジョンのモデルを調査しました。

具体的には、多モーダルトランスフォーマーモデル(例:Lu et al.、2019;Chen et al.、2020;Tan and Bansal、2019;Li et al.、2020)を考慮しています。これらのモデルは、さまざまな言語とビジョンのタスクで成功を収めています。しかし、ベンチマークでの強力なパフォーマンスにもかかわらず、これらのモデルが細かい多モーダル理解を持っているかどうかは明確ではありません。特に、以前の研究は、言語とビジョンのモデルが多モーダル理解なしでもベンチマークで成功できることを示しています:たとえば、言語の事前条件のみに基づいて画像に関する質問に答える(Agrawal et al.、2018)または画像にキャプションを付けるときに画像に存在しないオブジェクトを「幻視する」(Rohrbach et al.、2018)。モデルの制約を予測するために、Shekhar et al.のような研究では、言語理解のための専門的な評価を提案しています。ただし、以前のプローブセットではオブジェクトと動詞の数が限られています。私たちは、現行のモデルの動詞理解の潜在的な制約をよりよく評価するために、SVO-Probesを開発しました。
SVO-Probesには48,000の画像と文章のペアが含まれ、400以上の動詞の理解をテストします。各文章は<主語、動詞、目的語>(またはSVOトリプレット)に分解され、ポジティブとネガティブの例の画像とペアになります。ネガティブの例は、主語、動詞、または目的語のいずれかが変更されたものだけが異なります。上の図は、主語(左)、動詞(中央)、または目的語(右)が画像と一致しないネガティブな例を示しています。このタスクの定義により、モデルが最も苦労する文章の部分を分離することが可能になります。また、SVO-Probesは、クエリ文章とは全く関係のないネガティブな例が頻繁に存在する標準的な画像検索タスクよりも難しいです。
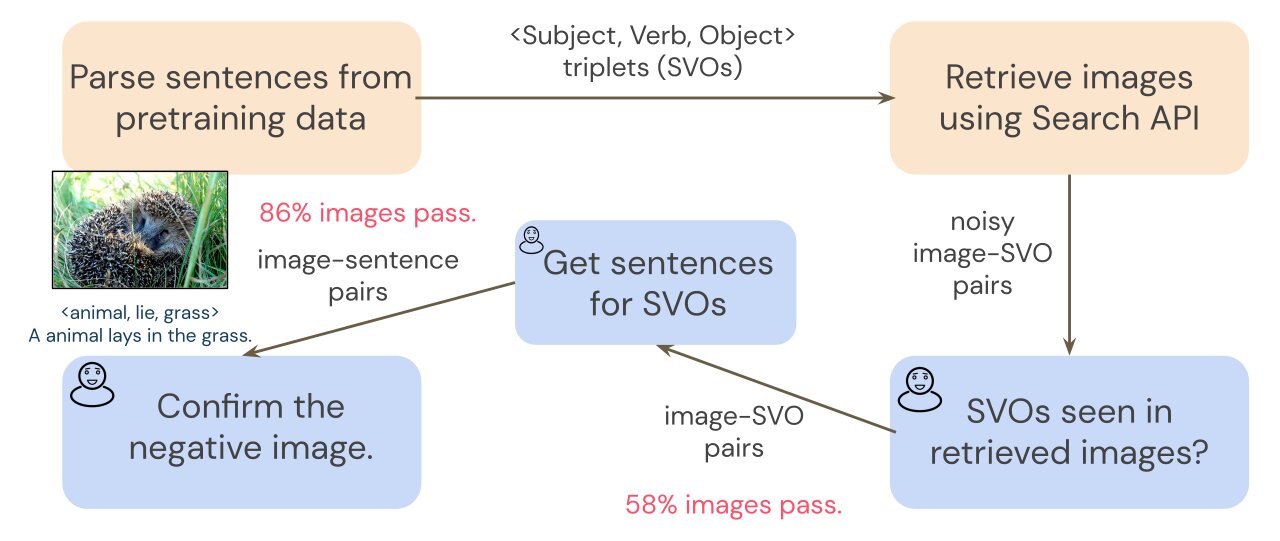
SVO-Probesを作成するために、共通のトレーニングデータセットであるConceptual Captions(Sharma et al.、2018)からSVOトリプレットで画像検索を行います。画像検索はノイズが発生する可能性があるため、予備の注釈ステップによって取得された画像をフィルタリングし、クリーンな画像-SVOペアのセットを確保します。トランスフォーマーは画像-文章のペアでトレーニングされているため、画像-SVOのペアでモデルを調査するために画像-文章のペアが必要です。各画像を説明する文章を収集するために、注釈者は各画像にSVOトリプレットを含む短い文章を作成します。たとえば、SVOトリプレット<動物、寝る、草>が与えられた場合、注釈者は「動物が草に寝そべっています」という文章を書くことができます。次に、SVOの注釈を使用して、各文章をネガティブな画像とペアにし、最終的な注釈ステップでネガティブな例を確認するように注釈者に依頼します。詳細については、以下の図を参照してください。
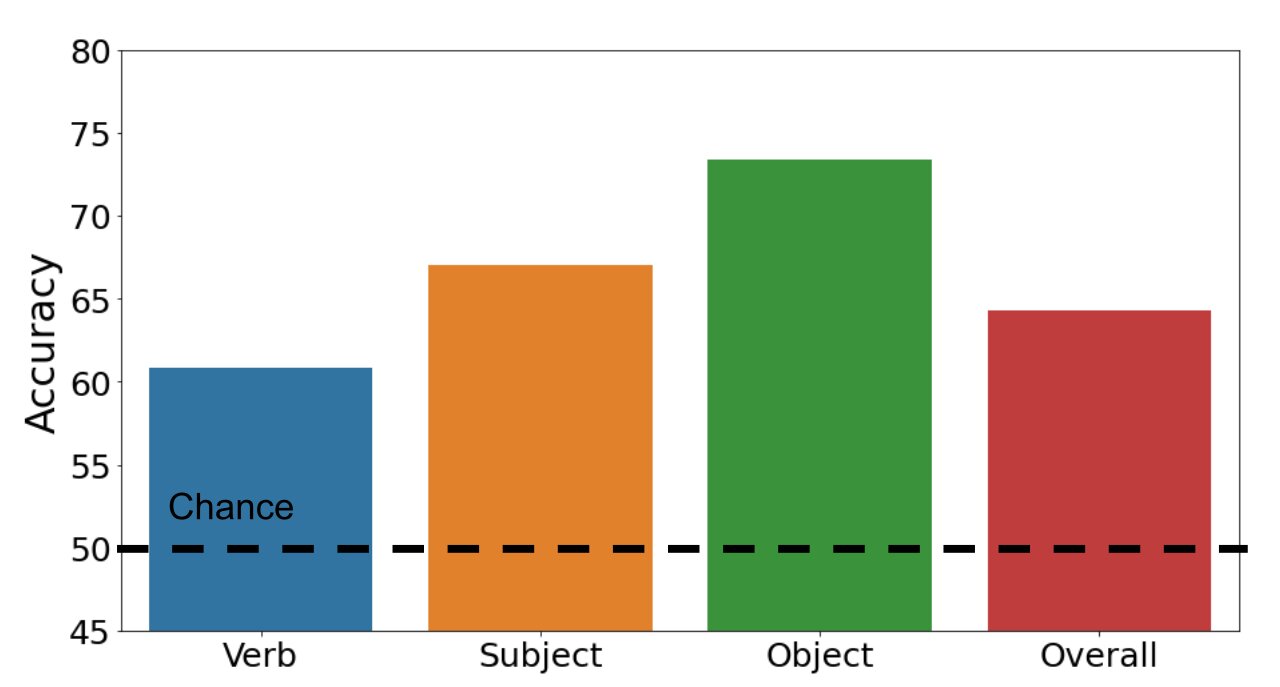
私たちは、多モーダルトランスフォーマーモデルが例を正確にポジティブまたはネガティブに分類できるかどうかを調査します。以下の棒グラフは、私たちの結果を示しています。私たちのデータセットは難解です:標準的な多モーダルトランスフォーマーモデルの全体的な正解率は64.3%です(偶然の正解率は50%です)。一方、主語と目的語の正解率はそれぞれ67.0%と73.4%ですが、動詞の場合は60.8%に低下します。この結果から、動詞の認識はビジョンと言語のモデルにとって本当に困難であることがわかります。
また、私たちは、私たちのデータセットで最も優れたモデルアーキテクチャを探索しています。驚くべきことに、画像モデリング能力が弱いモデルの方が標準的なトランスフォーマーモデルよりも優れたパフォーマンスを発揮します。1つの仮説は、標準モデル(より強力な画像モデリング能力を持つ)がトレーニングセットに過剰適合していることです。これらのモデルの両方は他の言語とビジョンのタスクで性能が低下するため、私たちのターゲットとするプローブタスクは、他のベンチマークでは観察されないモデルの弱点を明らかにします。
全体的に、ベンチマークでの印象的なパフォーマンスにもかかわらず、マルチモーダルトランスフォーマーは細かい理解、特に細かい動詞の理解に苦労していることがわかりました。SVO-Probesが言語とビジョンモデルの動詞理解の探索を支援し、より具体的なプローブデータセットの創造を促すことを願っています。
GitHubでのSVO-Probesベンチマークとモデルを訪問してください:ベンチマークとモデル。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles