「ビデオ編集はもはや難問ではありません:INVEはインタラクティブなニューラルビデオ編集を可能にするAI手法です」
INVE is an AI method that enables interactive neural video editing, making video editing no longer a difficult problem.


イメージ編集なしのインターネットを想像することができますか? すべての面白いミーム、素敵なインスタグラムの写真、魅力的な風景などがなくなってしまうでしょう。それは楽しいインターネットではないですよね?
デジタルカメラの初期から、イメージ編集は多くの人々の情熱でした。最初は簡単な編集ができるツールがありましたが、今ではほとんど努力をせずに画像の中の何でも何にでも変えることができます。特に最近の数年間で、強力なAIの手法のおかげで、イメージ編集ツールは驚くほど進化しました。
しかし、ビデオ編集に関しては、遅れています。ビデオ編集はしばしば専門知識と洗練されたソフトウェアが必要なものです。PremierやFinalCut Proなどの複雑なツールに入り込んで、細部を自分で調整しようとする必要があります。今ではビデオ編集は高給のスキルとなっていますから、それも無理はありません。一方、イメージ編集はモバイルアプリでも可能であり、結果は一般ユーザーに十分です。
- 大規模な言語モデルを効率的に提供するためのフレームワーク
- AIが迷走するとき:現実世界での注目すべき機械学習のミスハップ
- 「ディープラーニングを用いたナノアレイの開発:特定の構造色を生み出すことができるナノホールアレイを設計する新しいAI手法」
インタラクティブなビデオ編集が、イメージ編集と同じくらい使いやすくなれば、どんな可能性があるでしょうか。技術的な複雑さとはおさらばし、全く新しい自由のレベルにこんにちはと言えるようになることを想像してみてください!それがINVEです。
INVE (インタラクティブニューラルビデオエディタ)は、その名前が示すとおり、ビデオ編集の問題に取り組むAIモデルです。非専門のユーザーが複雑なビデオ編集を簡単に行える方法を提案しています。
INVE の主な目標は、ユーザーがビデオに対して複雑な編集を簡単かつ直感的な方法で行えるようにすることです。このアプローチは、レイヤー化されたニューラルアトラス表現に基づいています。この表現には、ビデオ内の各オブジェクトと背景のための2Dアトラス(画像)が含まれています。これらのアトラスにより、局所的かつ一貫した編集が可能となります。
ビデオ編集はいくつかの固有の課題により手間がかかります。たとえば、ビデオ内の異なるオブジェクトは独立して移動するため、不自然なアーティファクトを避けるために正確なローカリゼーションと注意深い構成が必要です。さらに、個々のフレームの編集は不一致や目に見える欠陥を引き起こす可能性があります。これらの問題に対処するために、INVE はレイヤー化されたニューラルアトラス表現を使用した新しいアプローチを導入しています。
アイデアは、ビデオを動くオブジェクトごとに1つ、背景用にもう1つの2Dアトラスのセットとして表現することです。この表現により、ビデオ全体で一貫性を保ちながら局所的な編集が可能となります。ただし、以前の手法では双方向のマッピングに問題があり、特定の編集の結果を予測することが困難でした。さらに、計算量の複雑さがリアルタイムのインタラクティブな編集を妨げました。
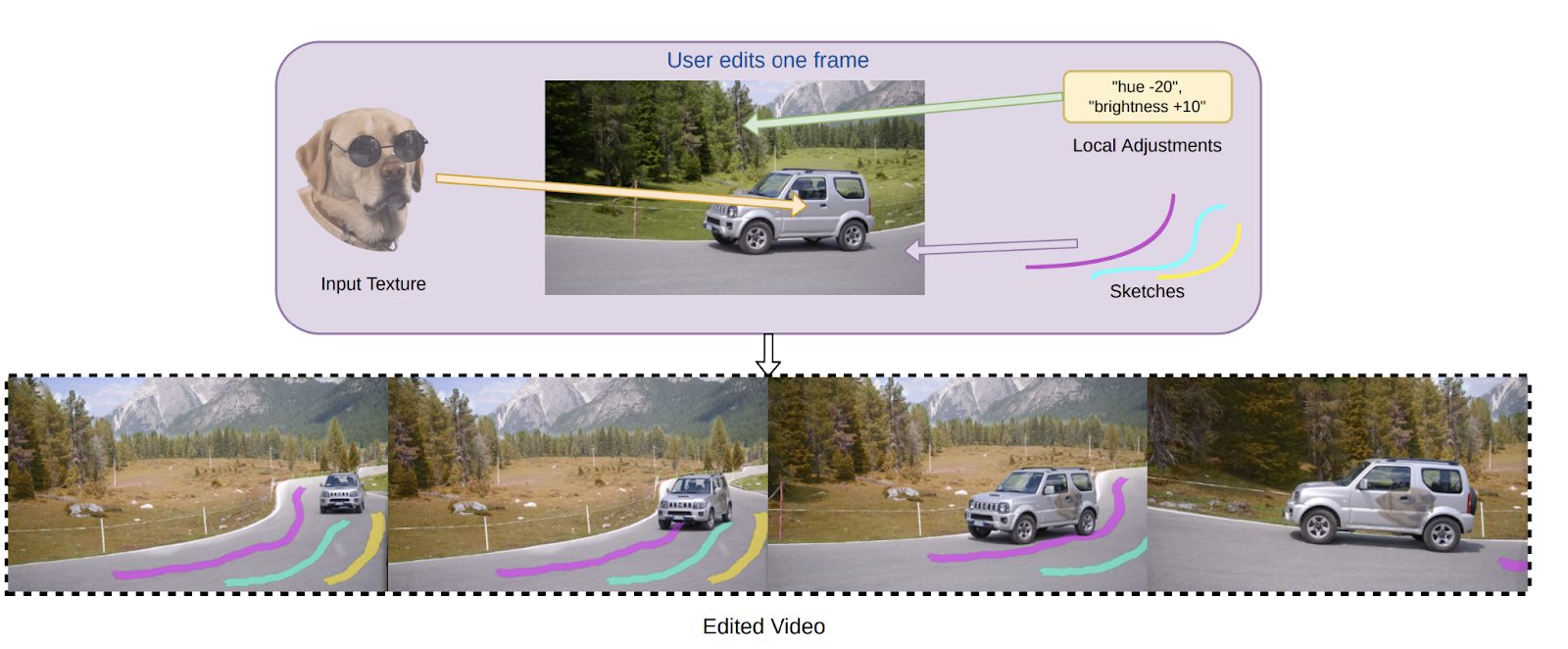
INVE は、アトラスとビデオイメージの間の双方向のマッピングを学習します。これにより、ユーザーはアトラスまたはビデオ自体のどちらでも編集を行うことができ、より多くの編集オプションがあり、最終的なビデオでどのように編集が認識されるかをより良く理解することができます。
さらに、INVE はマルチ解像度ハッシュコーディングを採用しており、学習と推論の速度が大幅に向上しています。これにより、ユーザーは本当にインタラクティブな編集体験を楽しむことができます。

INVEは、剛体テクスチャトラッキングやベクトル化されたスケッチなど、豊富な編集操作を提供しています。これにより、ユーザーは自分の編集ビジョンを努力せずに実現することができます。初心者のユーザーでも、技術的な複雑さに苦しまずに、インタラクティブなビデオ編集の力を活用することができます。これにより、動く車に外部グラフィックスを追加したり、背景の森の色合いを調整したり、道路にスケッチしたりするなどのビデオ編集が容易になります。これらの編集は、ビデオ全体に簡単に伝播します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 思っているベイダーではありません 3D VADERは3Dモデルを拡散するAIモデルです
- 「コンテキストの解読:NLPにおける単語ベクトル化技術」
- 「ROUGEメトリクス:大規模言語モデルにおける要約の評価」
- プラグ可能な回折ニューラルネットワーク(P-DNN):内部プラグインを切り替えることによって、様々なタスクを認識するために適用できるカスケードメタサーフェスを利用する一般的なパラダイム
- 「RAVENに会ってください:ATLASの制限に対処する検索強化型エンコーダーデコーダーランゲージモデル」
- アーサーがベンチを発表:仕事に最適な言語モデルを見つけるためのAIツール
- 「ベイズフローネットワークの公開:生成モデリングの新たなフロンティア」






